Download Data Processing: Relational Model and Data Modeling Techniques and more Essays (high school) Computer science in PDF only on Docsity!
DOMINICAN COLLEGE, ABUJA
DATA PROCESSING
E-Lesson Note Year 11 First Term 2024-25 Academic Session
1. INTRODUCTION
Overview of the Subject:
Data Processing is an academic field that explores the theory, design, development, and application of computer systems and technology, encompassing subfields like Computer Science, Information Technology, and Information Systems, to prepare students for careers in software development, data analysis, cybersecurity, and more.
Learning Objectives:
Here are the learning objectives of Data Processing:
Understand the fundamental concepts of computer science, including algorithms, data structures, and software design. Develop proficiency in programming languages, such as Python, Java, or C++. Analyze and solve computational problems using logical and methodical approaches. Design, implement, and test computer-based systems, including software and hardware components. Understand computer architecture, organization, and networking fundamentals. Apply database concepts and management techniques to store and retrieve data.
Relevance to Real-world Applications:
The learning objectives of Data Processing are highly relevant to the real world, preparing students to develop software solutions, analyze data, design secure systems, and pursue careers in emerging fields like AI, cybersecurity, and data science, ultimately enabling them to solve real-world problems and make meaningful contributions to society.
Prerequisites:
The typical prerequisites for studying Data Processing include basic computer literacy, a high school diploma, mathematics and science fundamentals, and optional programming experience, with specific requirements varying by institution and program.
FIRST TERM DATA PROCESSING NOTE (YEAR 11)
TOPIC: DATA MODELS
What is a Data Model? Good data allows organizations to establish baselines, benchmarks, and goals to keep moving forward. In order for data to allow this measuring, it has to be organized through data description, data semantics, and consistency constraints of data. A Data Model is this abstract model that allows the further building of conceptual models and to set relationships between data items. An organization may have a huge data repository; however, if there is no standard to ensure the basic accuracy and interpretability of that data, then it is of no use. A proper data model certifies actionable downstream results, knowledge of best practices regarding the data, and the best tools to access it.
Data Model is the modeling of the data description, data semantics, and consistency constraints of the data. It provides the conceptual tools for describing the design of a database at each level of data abstraction. Therefore, there are following four data models used for understanding the structure of the database:
1) Relational Data Model: This type of model designs the data in the form of rows and columns within a table. Thus, a relational model uses tables for representing data and in- between relationships. Tables are also called relations. This model was initially described by Edgar F. Codd, in 1969. The relational data model is the widely used model which is primarily used by commercial data processing applications.
Data Modeling thus helps to increase consistency in naming, rules, semantics, and security. This, in turn, improves data analytics. The emphasis is on the need for availability and organization of data, independent of the manner of its application.
Data Modeling Process Data modeling is a process of creating a conceptual representation of data objects and their relationships to one another. The process of data modeling typically involves several steps, including requirements gathering, conceptual design, logical design, physical design, and implementation. During each step of the process, data modelers work with stakeholders to understand the data requirements, define the entities and attributes, establish the relationships between the data objects, and create a model that accurately represents the data in a way that can be used by application developers, database administrators, and other stakeholders.
Levels of Data Abstraction Data modeling typically involves several levels of abstraction, including: Conceptual level: The conceptual level involves defining the high-level entities and relationships in the data model, often using diagrams or other visual representations. Logical level: The logical level involves defining the relationships and constraints between the data objects in more detail, often using data modeling languages such as SQL or ER diagrams. Physical level: The physical level involves defining the specific details of how the data will be stored, including data types, indexes, and other technical details.
Data Modeling Examples The best way to picture a data model is to think about a building plan of an architect. An architectural building plan assists in putting up all subsequent conceptual models, and so does a data model. These data modeling examples will clarify how data models and the process of data modeling highlights essential data and the way to arrange it.
1. ER (Entity-Relationship) Model This model is based on the notion of real-world entities and relationships among them. It creates an entity set, relationship set, general attributes, and constraints.
Here, an entity is a real-world object; for instance, an employee is an entity in an employee database. An attribute is a property with value, and entity sets share attributes of identical value. Finally, there is the relationship between entities.
2. Hierarchical Model This data model arranges the data in the form of a tree with one root, to which other data is connected. The hierarchy begins with the root and extends like a tree. This model effectively explains several real-time relationships with a single one-to-many relationship between two different kinds of data. For example, one supermarket can have different departments and many aisles. Thus, the ‘root’ node supermarket will have two ‘child’ nodes of (1) Pantry, (2) Packaged Food. 3. Network Model This database model enables many-to-many relationships among the connected nodes. The data is arranged in a graph-like structure, and here ‘child’ nodes can have multiple ‘parent’ nodes. The parent nodes are known as owners, and the child nodes are called members. 4. Relational Model This popular data model example arranges the data into tables. The tables have columns and rows, each cataloging an attribute present in the entity. It makes relationships between data points easy to identify. For example, e-commerce websites can process purchases and track inventory using the relational model. 5. Object-Oriented Database Model This data model defines a database as an object collection, or recyclable software components, with related methods and features. For instance, architectural and engineering real-time systems used in 3D modeling use this data modeling process. 6. Object-Relational Model This model is a combination of an object-oriented database model and a relational database model. Therefore, it blends the advanced functionalities of the object-oriented model with the ease of the relational data model.
governance and data quality. Overall, the evolution of data modeling reflects the ongoing importance of effective data management in today's data-driven business environment.
Types of Data Modeling There are three main types of data models that organizations use. These are produced during the course of planning a project in analytics. They range from abstract to discrete specifications, involve contributions from a distinct subset of stakeholders, and serve different purposes.
1. Conceptual Model It is a visual representation of database concepts and the relationships between them identifying the high-level user view of data. Rather than the details of the database itself, it focuses on establishing entities, characteristics of an entity, and relationships between them. 2. Logical Model This model further defines the structure of the data entities and their relationships. Usually, a logical data model is used for a specific project since the purpose is to develop a technical map of rules and data structures. 3. Physical Model This is a schema or framework defining how data is physically stored in a database. It is used for database-specific modeling where the columns include exact types and attributes. A physical model designs the internal schema. The purpose is the actual implementation of the database. The logical vs. physical data model is characterized by the fact that the logical model describes the data to a great extent, but it does not take part in implementing the database, which a physical model does. In other words, the logical data model is the basis for developing the physical model, which gives an abstraction of the database and helps to generate the schema. The conceptual data modeling examples can be found in employee management systems, simple order management, hotel reservation, etc. These examples show that this particular data model is used to communicate and define the business requirements of the database and to present concepts. It is not meant to be technical but simple.
Data Modelling Techniques There are three basic data modeling techniques. First, there is the Entity-Relationship Diagram or ERD technique for modeling and the design of relational or traditional databases. Second, the UML or Unified Modeling Language Class Diagrams is a standardized family of notations for modeling and design of information systems. Finally, the third is Data Dictionary modeling technique where tabular definition or representation of data assets is done.
Data Modeling Tools We have seen that data modeling is the process of applying certain techniques and methodologies to the data in order to convert it to a useful form. This is done through Data Modeling tools which assists in creating a database structure from diagrammatic drawings. It makes connecting data easier and forms a perfect data structure according to requirement. Those are the important tools we discussed in what is data modelling.
Importance of Data Modeling It is clear by now that data modeling is necessary foundational work. It allows data to be easily stored in a database and positively impacts data analytics. It is critical for data management, data governance, and data intelligence.
- It means better documentation of data sources, higher quality and clearer scope of data use with faster performance and few errors.
- From the regulatory compliance view, data modeling ensures that an organization adheres to governmental laws and applicable industry regulations.
- It empowers employees to make data-driven decisions and strategies.
- It builds on business intelligence as it allows the identification of new opportunities by expanding data capability.
TOPIC: NORMAL FORMS
Normalization A large database defined as a single relation may result in data duplication. This repetition of data may result in: o Making relations very large.
Types of Normal Forms: Normalization works through a series of stages called Normal forms. The normal forms apply to individual relations. The relation is said to be in particular normal form if it satisfies constraints.
Following are the various types of Normal forms:
Advantages of Normalization o Normalization helps to minimize data redundancy. o Greater overall database organization. o Data consistency within the database. o Much more flexible database design. o Enforces the concept of relational integrity.
Disadvantages of Normalization o You cannot start building the database before knowing what the user needs. o The performance degrades when normalizing the relations to higher normal forms, i.e., 4NF, 5NF. o It is very time-consuming and difficult to normalize relations of a higher degree. o Careless decomposition may lead to a bad database design, leading to serious problems.
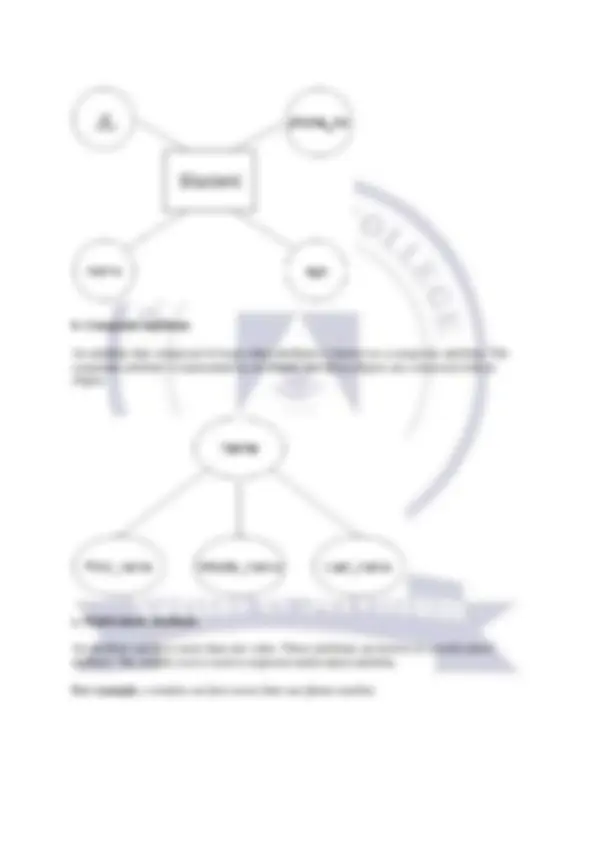
First Normal Form (1NF) o A relation will be 1NF if it contains an atomic value. o It states that an attribute of a table cannot hold multiple values. It must hold only single-valued attribute. o First normal form disallows the multi-valued attribute, composite attribute, and their combinations. Example: Relation EMPLOYEE is not in 1NF because of multi-valued attribute EMP_PHONE. EMPLOYEE table: The decomposition of the EMPLOYEE table into 1NF has been shown below:
Normal Form
Description
1NF A relation is in 1NF if it contains an atomic value.
2NF A relation will be in 2NF if it is in 1NF and all non-key attributes are fully functional dependent on the primary key.
3NF A relation will be in 3NF if it is in 2NF and no transition dependency exists.
BCNF A stronger definition of 3NF is known as Boyce Codd's normal form.
4NF A relation will be in 4NF if it is in Boyce Codd's normal form and has no multi- valued dependency.
5NF A relation is in 5NF. If it is in 4NF and does not contain any join dependency, joining should be lossless.
EMP_ID EMP_NAME EMP_PHONE EMP_STATE
14 John 7272826385, 9064738238
UP
20 Harry 8574783832 Bihar
12 Sam 7390372389, 8589830302
Punjab
TEACHER_DETAIL table: TEACHER_ID TEACHER_AGE
25 30
47 35
83 38
TEACHER_SUBJECT table: TEACHER_ID SUBJECT
25 Chemistry
25 Biology
47 English
83 Math
83 Computer
Third Normal Form (3NF) o A relation will be in 3NF if it is in 2NF and not contain any transitive partial dependency. o 3NF is used to reduce the data duplication. It is also used to achieve the data integrity. o If there is no transitive dependency for non-prime attributes, then the relation must be in third normal form. A relation is in third normal form if it holds atleast one of the following conditions for every non-trivial function dependency X → Y.
- X is a super key.
- Y is a prime attribute, i.e., each element of Y is part of some candidate key.
Example: EMPLOYEE_DETAIL table: EMP_ID EMP_NAME EMP_ZIP EMP_STATE EMP_CITY
222 Harry 201010 UP Noida
333 Stephan 02228 US Boston
444 Lan 60007 US Chicago
555 Katharine 06389 UK Norwich
666 John 462007 MP Bhopal
Super key in the table above:
- {EMP_ID}, {EMP_ID, EMP_NAME}, {EMP_ID, EMP_NAME, EMP_ZIP}....so on
Candidate key: {EMP_ID} Non-prime attributes: In the given table, all attributes except EMP_ID are non- prime. Here, EMP_STATE & EMP_CITY dependent on EMP_ZIP and EMP_ZIP dependent on EMP_ID. The non-prime attributes (EMP_STATE, EMP_CITY) transitively dependent on super key(EMP_ID). It violates the rule of third normal form. That's why we need to move the EMP_CITY and EMP_STATE to the new <EMPLOYEE_ZIP> table, with EMP_ZIP as a Primary key.
EMPLOYEE table: EMP_ID EMP_NAME EMP_ZIP
222 Harry 201010
333 Stephan 02228
444 Lan 60007
In the above table Functional dependencies are as follows:
- EMP_ID → EMP_COUNTRY
- EMP_DEPT → {DEPT_TYPE, EMP_DEPT_NO} Candidate key: {EMP-ID, EMP-DEPT} The table is not in BCNF because neither EMP_DEPT nor EMP_ID alone are keys. To convert the given table into BCNF, we decompose it into three tables:
EMP_COUNTRY table: EMP_ID EMP_COUNTRY
264 India
264 India
EMP_DEPT table: EMP_DEPT DEPT_TYPE EMP_DEPT_NO
Designing D394 283
Testing D394 300
Stores D283 232
Developing D283 549
EMP_DEPT_MAPPING table: EMP_ID EMP_DEPT
D394 283
D394 300
D283 232
D283 549
Functional dependencies:
- EMP_ID → EMP_COUNTRY
- EMP_DEPT → {DEPT_TYPE, EMP_DEPT_NO} Candidate keys: For the first table: EMP_ID For the second table: EMP_DEPT For the third table: {EMP_ID, EMP_DEPT} Now, this is in BCNF because left side part of both the functional dependencies is a key.
Fourth normal form (4NF) o A relation will be in 4NF if it is in Boyce Codd normal form and has no multi-valued dependency. o For a dependency A → B, if for a single value of A, multiple values of B exists, then the relation will be a multi-valued dependency. Example STUDENT STU_ID COURSE HOBBY
21 Computer Dancing
21 Math Singing
34 Chemistry Dancing
74 Biology Cricket
59 Physics Hockey
The given STUDENT table is in 3NF, but the COURSE and HOBBY are two independent entity. Hence, there is no relationship between COURSE and HOBBY.
o 5NF is also known as Project-join normal form (PJ/NF). Example SUBJECT LECTURER SEMESTER
Computer Anshika Semester 1
Computer John Semester 1
Math John Semester 1
Math Akash Semester 2
Chemistry Praveen Semester 1
In the above table, John takes both Computer and Math class for Semester 1 but he doesn't take Math class for Semester 2. In this case, combination of all these fields required to identify a valid data. Suppose we add a new Semester as Semester 3 but do not know about the subject and who will be taking that subject so we leave Lecturer and Subject as NULL. But all three columns together acts as a primary key, so we can't leave other two columns blank. So to make the above table into 5NF, we can decompose it into three relations P1, P2 & P3: P SEMESTER SUBJECT
Semester 1 Computer
Semester 1 Math
Semester 1 Chemistry
Semester 2 Math
P SUBJECT LECTURER
Computer Anshika
Computer John
Math John
Math Akash
Chemistry Praveen
P SEMSTER LECTURER
Semester 1 Anshika
Semester 1 John
Semester 1 John
Semester 2 Akash
Semester 1 Praveen
TOPIC: RELATIONAL MODEL
E.F. Codd proposed the relational Model to model data in the form of relations or tables. After designing the conceptual model of the Database using ER diagram, we need to convert the conceptual model into a relational model which can be implemented using any RDBMS language like Oracle SQL, MySQL, etc. So we will see what the Relational Model is. The relational model uses a collection of tables to represent both data and the relationships among those data. Each table has multiple columns, and each column has a unique name. Tables are also known as relations. The relational model is an example of a record-based model. Record-based models are so named because the database is structured in fixed- format records of several types. Each table contains records of a particular type. Each record type defines a fixed number of fields, or attributes. The columns of the table correspond to the attributes of the record type. The relational data model is the most widely