Download Database Management Systems Relation Model and more Study notes Database Management Systems (DBMS) in PDF only on Docsity!
Relation Model
Relational model or Relational data model is the primary data model, which is used widely around the world for data storage and processing. This model is simple and it has all the properties and capabilities required to process data with storage efficiency.
Concepts
Tables − In relational data model, relations are saved in the format of Tables. This format stores the relation among entities. A table has rows and columns, where rows represents records and columns represent the attributes. Tuple − A single row of a table, which contains a single record for that relation is called a tuple. Relation instance − A finite set of tuples in the relational database system represents relation instance. Relation instances do not have duplicate tuples. Relation schema − A relation schema describes the relation name (table name), attributes, and their names. Relation key − Each row has one or more attributes, known as relation key, which can identify the row in the relation (table) uniquely. Attribute domain − Every attribute has some pre-defined value scope, known as attribute domain.
Constraints
Every relation has some conditions that must hold for it to be a valid relation. These conditions are called Relational Integrity Constraints. There are three main integrity constraints − Key constraints Domain constraints Referential integrity constraints Key Constraints There must be at least one minimal subset of attributes in the relation, which can identify a tuple uniquely. This minimal subset of attributes is called key for that relation. If there are more than one such minimal subsets, these are called candidate keys. Key constraints force that − in a relation with a key attribute, no two tuples can have identical values for key attributes. a key attribute can not have NULL values. Key constraints are also referred to as Entity Constraints. Domain Constraints Attributes have specific values in real-world scenario. For example, age can only be a positive integer. The same constraints have been tried to employ on the attributes of a relation. Every attribute is bound to have a specific range of values. For example, age cannot be less than zero and telephone numbers cannot contain a digit outside 0-9. Referential integrity Constraints Referential integrity constraints work on the concept of Foreign Keys. A foreign key is a key attribute of a relation that can be referred in other relation.
Referential integrity constraint states that if a relation refers to a key attribute of a different or same relation, then that key element must exist.
Codd's 12 Rules
Dr Edgar F. Codd, after his extensive research on the Relational Model of database systems, came up with twelve rules of his own, which according to him, a database must obey in order to be regarded as a true relational database. These rules can be applied on any database system that manages stored data using only its relational capabilities. This is a foundation rule, which acts as a base for all the other rules.
Rule 1: Information Rule
The data stored in a database, may it be user data or metadata, must be a value of some table cell. Everything in a database must be stored in a table format.
Rule 2: Guaranteed Access Rule
Every single data element (value) is guaranteed to be accessible logically with a combination of table-name, primary-key (row value), and attribute-name (column value). No other means, such as pointers, can be used to access data.
Rule 3: Systematic Treatment of NULL Values
The NULL values in a database must be given a systematic and uniform treatment. This is a very important rule because a NULL can be interpreted as one the following − data is missing, data is not known, or data is not applicable.
Rule 4: Active Online Catalog
The structure description of the entire database must be stored in an online catalog, known as data dictionary , which can be accessed by authorized users. Users can use the same query language to access the catalog which they use to access the database itself.
Rule 5: Comprehensive Data Sub-Language Rule
A database can only be accessed using a language having linear syntax that supports data definition, data manipulation, and transaction management operations. This language can be used directly or by means of some application. If the database allows access to data without any help of this language, then it is considered as a violation.
Rule 6: View Updating Rule
All the views of a database, which can theoretically be updated, must also be updatable by the system.
Rule 7: High-Level Insert, Update, and Delete Rule
A database must support high-level insertion, updation, and deletion. This must not be limited to a single row, that is, it must also support union, intersection and minus operations to yield sets of data records.
Rule 8: Physical Data Independence
The data stored in a database must be independent of the applications that access the database. Any change in the physical structure of a database must not have any impact on how the data is being accessed by external applications.
Rule 9: Logical Data Independence
The logical data in a database must be independent of its user’s view (application). Any change in logical data must not affect the applications using it. For example, if two tables are merged or one is split into two different
Relational Algebra
Relational database systems are expected to be equipped with a query language that can assist its users to query the database instances. There are two kinds of query languages − relational algebra and relational calculus.
Relational Algebra
Relational algebra is a procedural query language, which takes instances of relations as input and yields instances of relations as output. It uses operators to perform queries. An operator can be either unary or binary. They accept relations as their input and yield relations as their output. Relational algebra is performed recursively on a relation and intermediate results are also considered relations. The fundamental operations of relational algebra are as follows − Select Project Union Set different Cartesian product Rename We will discuss all these operations in the following sections.
Select Operation (σ)σ))
It selects tuples that satisfy the given predicate from a relation. Notation − σ p (r) Where σ stands for selection predicate and r stands for relation. p is prepositional logic formula which may use connectors like and, or, and not. These terms may use relational operators like − =, ≠, ≥, < , >, ≤. For example − σ subject = "database" (Books) Output − Selects tuples from books where subject is 'database'. σsubject = "database" and price = "450"(Books) Output − Selects tuples from books where subject is 'database' and 'price' is 450. σsubject = "database" and price = "450" or year > "2010"(Books) Output − Selects tuples from books where subject is 'database' and 'price' is 450 or those books published after
Project Operation (σ)∏)
It projects column(s) that satisfy a given predicate. Notation − ∏A 1 , A 2 , An (r) Where A 1 , A 2 , An are attribute names of relation r. Duplicate rows are automatically eliminated, as relation is a set.
For example − ∏subject, author (Books) Selects and projects columns named as subject and author from the relation Books.
Union Operation (σ) ∪ )
It performs binary union between two given relations and is defined as − r ∪ s = { t | t ∈ r or t ∈ s} Notation − r U s Where r and s are either database relations or relation result set (temporary relation). For a union operation to be valid, the following conditions must hold − r , and s must have the same number of attributes. Attribute domains must be compatible. Duplicate tuples are automatically eliminated. ∏ (^) author (Books) ∪ ∏ (^) author (Articles) Output − Projects the names of the authors who have either written a book or an article or both.
Set Difference (σ)−)
The result of set difference operation is tuples, which are present in one relation but are not in the second relation. Notation − r − s Finds all the tuples that are present in r but not in s. ∏ (^) author (Books) − ∏ (^) author (Articles) Output − Provides the name of authors who have written books but not articles.
Cartesian Product (σ)Χ))
Combines information of two different relations into one. Notation − r Χ s Where r and s are relations and their output will be defined as − r Χ s = { q t | q ∈ r and t ∈ s} σauthor = 'ABCD'(Books Χ Articles) Output − Yields a relation, which shows all the books and articles written by ABCD.
Rename Operation (σ)ρ))
The results of relational algebra are also relations but without any name. The rename operation allows us to rename the output relation. 'rename' operation is denoted with small Greek letter rho ρ. Notation − ρ (^) x (E) Where the result of expression E is saved with name of x. Additional operations are −
using ER diagram. We cannot import all the ER constraints into relational model, but an approximate schema can be generated. There are several processes and algorithms available to convert ER Diagrams into Relational Schema. Some of them are automated and some of them are manual. We may focus here on the mapping diagram contents to relational basics. ER diagrams mainly comprise of − Entity and its attributes Relationship, which is association among entities.
Mapping Entity
An entity is a real-world object with some attributes. Mapping Process (Algorithm) Create table for each entity. Entity's attributes should become fields of tables with their respective data types. Declare primary key.
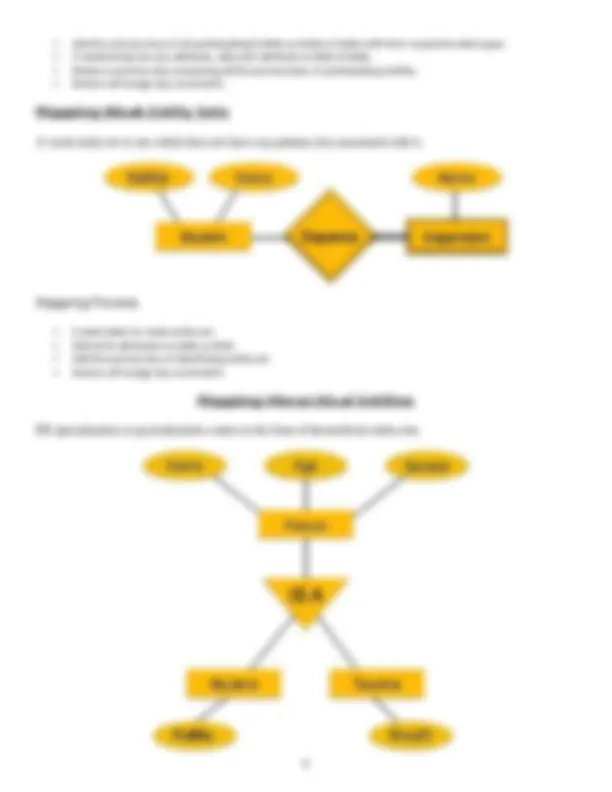
Mapping Relationship
A relationship is an association among entities. Mapping Process Create table for a relationship.
Add the primary keys of all participating Entities as fields of table with their respective data types. If relationship has any attribute, add each attribute as field of table. Declare a primary key composing all the primary keys of participating entities. Declare all foreign key constraints.
Mapping Weak Entity Sets
A weak entity set is one which does not have any primary key associated with it. Mapping Process Create table for weak entity set. Add all its attributes to table as field. Add the primary key of identifying entity set. Declare all foreign key constraints.
Mapping Hierarchical Entities
ER specialization or generalization comes in the form of hierarchical entity sets.
SQL Overview
SQL is a programming language for Relational Databases. It is designed over relational algebra and tuple relational calculus. SQL comes as a package with all major distributions of RDBMS. SQL comprises both data definition and data manipulation languages. Using the data definition properties of SQL, one can design and modify database schema, whereas data manipulation properties allows SQL to store and retrieve data from database.
Data Definition Language
SQL uses the following set of commands to define database schema − CREATE Creates new databases, tables and views from RDBMS. For example − Create database ABCD; Create table article; Create view for_students; DROP Drops commands, views, tables, and databases from RDBMS. For example − Drop object_type object_name; Drop database ABCD; Drop table article; Drop view for_students; ALTER Modifies database schema. Alter object_type object_name parameters; For example − Alter table article add subject varchar; This command adds an attribute in the relation article with the name subject of string type.
Data Manipulation Language
SQL is equipped with data manipulation language (DML). DML modifies the database instance by inserting, updating and deleting its data. DML is responsible for all forms data modification in a database. SQL contains the following set of commands in its DML section − SELECT/FROM/WHERE INSERT INTO/VALUES UPDATE/SET/WHERE DELETE FROM/WHERE These basic constructs allow database programmers and users to enter data and information into the database and retrieve efficiently using a number of filter options.
SELECT/FROM/WHERE
SELECT − This is one of the fundamental query command of SQL. It is similar to the projection operation of relational algebra. It selects the attributes based on the condition described by WHERE clause. FROM − This clause takes a relation name as an argument from which attributes are to be selected/projected. In case more than one relation names are given, this clause corresponds to Cartesian product. WHERE − This clause defines predicate or conditions, which must match in order to qualify the attributes to be projected. For example − Select author_name From book_author Where age > 50; This command will yield the names of authors from the relation book_author whose age is greater than 50. INSERT INTO/VALUES This command is used for inserting values into the rows of a table (relation). Syntax − INSERT INTO table (column1 [, column2, column3 ... ]) VALUES (value1 [, value2, value ... ]) Or INSERT INTO table VALUES (value1, [value2, ... ]) For example − INSERT INTO ABCD (Author, Subject) VALUES ("anonymous", "computers"); UPDATE/SET/WHERE This command is used for updating or modifying the values of columns in a table (relation). Syntax − UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition] For example − UPDATE ABCD SET Author="webmaster" WHERE Author="anonymous"; DELETE/FROM/WHERE This command is used for removing one or more rows from a table (relation). Syntax − DELETE FROM table_name [WHERE condition]; For example − DELETE FROM ABCDs WHERE Author="unknown";