Download Databricks zero to hero and more Slides Computer science in PDF only on Docsity!
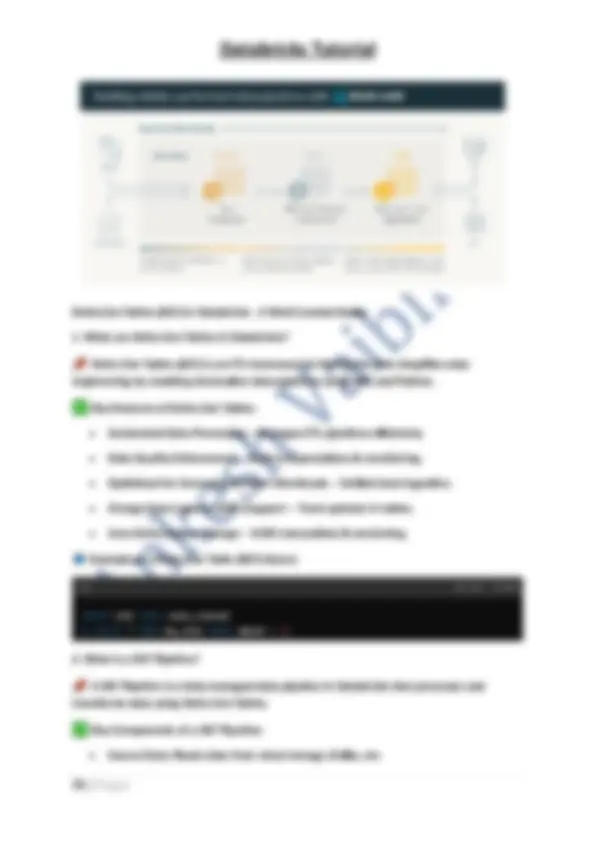
The Databricks Intelligence Platform provides:
- Unified Data Analytics – Combines data engineering, data science, and business analytics in one platform.
- Lakehouse Architecture – Merges data lakes and data warehouses for structured and unstructured data processing.
- AI & Machine Learning – Supports ML workflows with AutoML, Feature Store, and MLflow for experiment tracking.
- Data Engineering – Optimized ETL workflows with Delta Live Tables and Apache Spark.
- Business Intelligence (BI) – Integration with visualization tools like Power BI, Tableau, and Databricks SQL.
- Data Governance & Security – Unity Catalog for access control, data lineage, and compliance.
- Collaborative Workspaces – Shared notebooks, real-time collaboration, and multi- language support (Python, SQL, Scala, R).
- Serverless & Scalable Compute – Auto-scaling clusters and serverless computing for cost efficiency.
- Workspaces are created and managed at the account level. Key Relationship
- A Databricks account can have multiple workspaces.
- Each workspace operates independently but is billed through the same Databricks account.
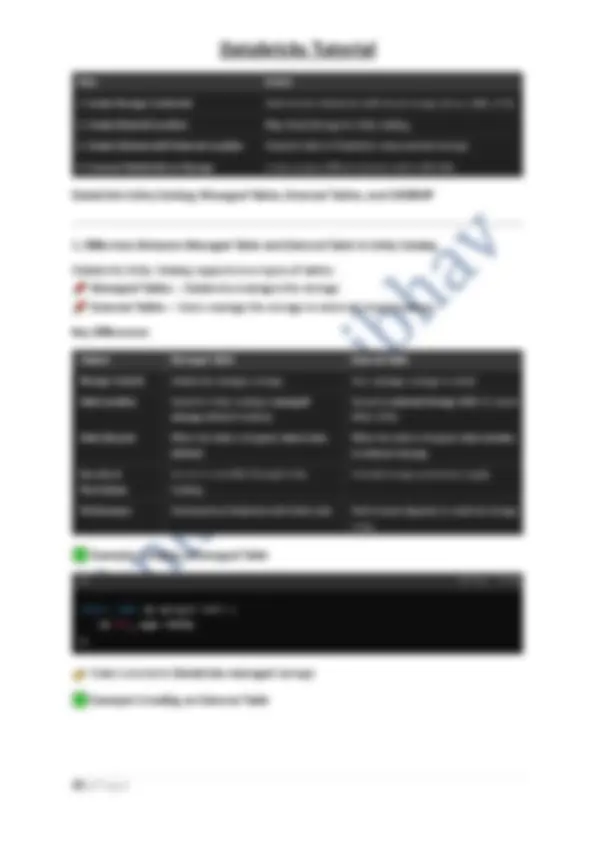
- Workspaces can be configured differently based on security, compute needs, and data access policies. 2. What is Databricks Workspace? Definition Databricks Workspace is a collaborative, cloud-based environment for data analytics, engineering, and machine learning. It provides tools for:
- Data ingestion from multiple sources
- Data processing using Apache Spark
- Machine Learning & AI with MLflow
- Visualization with Databricks SQL Key Features
- Notebooks : Interactive notebooks supporting Python, SQL, Scala, and R.
- Clusters : Managed Spark clusters for scalable computing.
- Jobs : Automated workflows for ETL and ML training.
- Data Governance : Unity Catalog for security and access control.
- Workspace API : Automate workspace operations via REST API. 3. Databricks High-Level Architecture The Databricks platform is built on a Lakehouse Architecture , combining data lakes and warehouses. Key Components
- Data Sources o Cloud storage: AWS S3, Azure Data Lake, GCP Storage o Databases: SQL, NoSQL o Streaming: Kafka, IoT data
- Data Ingestion & Processing o Apache Spark for big data processing o Delta Lake for structured and unstructured data o Databricks Notebooks for ETL and ML tasks
- Storage Layer (Delta Lake) o ACID transactions for reliability o Schema enforcement & governance
- Compute & Processing o Scalable, auto-managed Spark clusters o Serverless compute for optimized performance
- Machine Learning & AI o MLflow for experiment tracking o Feature Store for reusable ML features
- BI & Visualization o Databricks SQL, Power BI, Tableau integration
- Security & Governance o Unity Catalog for access control o Role-based permissions 4. What is Control and Data Plane in Databricks? Control Plane
- Managed by Databricks (not within user’s cloud account).
- Handles workspace UI, authentication, job scheduling, and cluster management.
- Stores metadata, notebook code, and configurations.
- Hosted by Databricks on AWS, Azure, or GCP. Data Plane
- Runs in the customer’s cloud environment (AWS, Azure, GCP).
- Contains compute resources (clusters, VMs) that process data.
- Stores actual data in cloud storage (S3, ADLS, GCS).
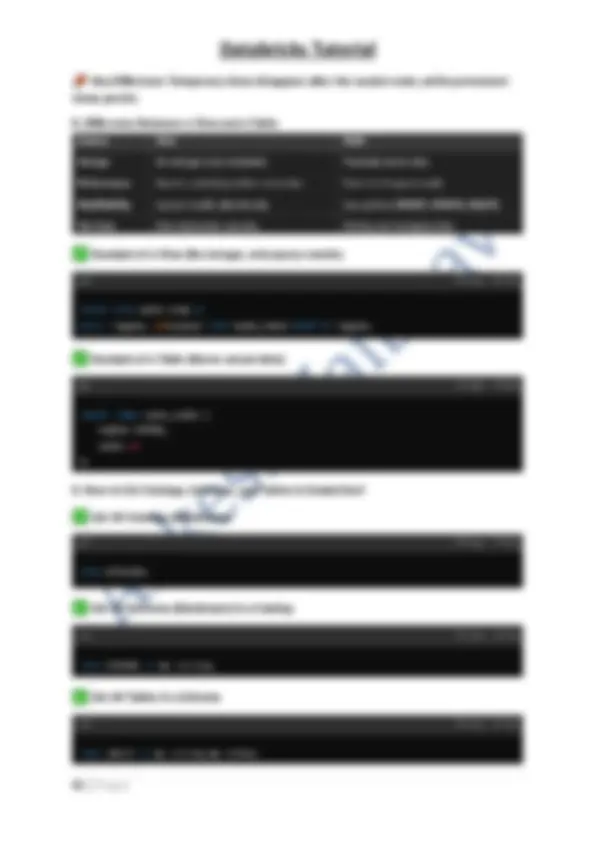
Conclusion Databricks is a powerful cloud platform enabling data analytics, AI, and data engineering at scale. Its workspace-based architecture, separation of control & data planes, and Lakehouse model provide high performance, security, and collaboration. 1. Setup Databricks with AWS and GCP Step 1: Create a Databricks Account
- Visit Databricks and sign up.
- Select AWS or Google Cloud as your cloud provider.
- Create a Databricks workspace from the Databricks account console. Step 2: Configure AWS Integration
- IAM Role Creation : o Create an IAM role in AWS with S3, EC2, and KMS permissions. o Attach the policy: o Enable cross-account role access for Databricks.
- Deploy Databricks on AWS : o Go to the AWS Marketplace and search for Databricks. o Choose Databricks E2 or Serverless based on pricing needs. o Launch using CloudFormation. Step 3: Configure Google Cloud Integration
- Enable Dataproc API and create a GCP project.
- Create a service account and grant: o Storage Admin for GCS access. o Compute Admin for VM management.
- Deploy Databricks from GCP Console and configure network settings. 3. Setup Databricks with Azure Step 1: Create an Azure Databricks Workspace
- Go to Azure Portal → Create a Resource → Search for Azure Databricks.
- Click Create , then choose: o Subscription : Select your Azure subscription. o Resource Group : Create a new or use an existing one. o Workspace Name : Give it a unique name. o Region : Choose closest to your users. Step 2: Configure Networking
- Select Virtual Network Injection (Optional for custom VNet).
- Enable Managed VNet for auto-handling of network traffic. Step 3: Assign User Permissions
- Open Azure Active Directory (AAD).
- Assign RBAC roles for Admins, Engineers, and Data Scientists.
- Enable Unity Catalog for governance (if needed). Step 4: Launch Databricks & Start Using Notebooks
- Open the Databricks workspace from Azure.
- Create a cluster (Auto-Scaling or Serverless).
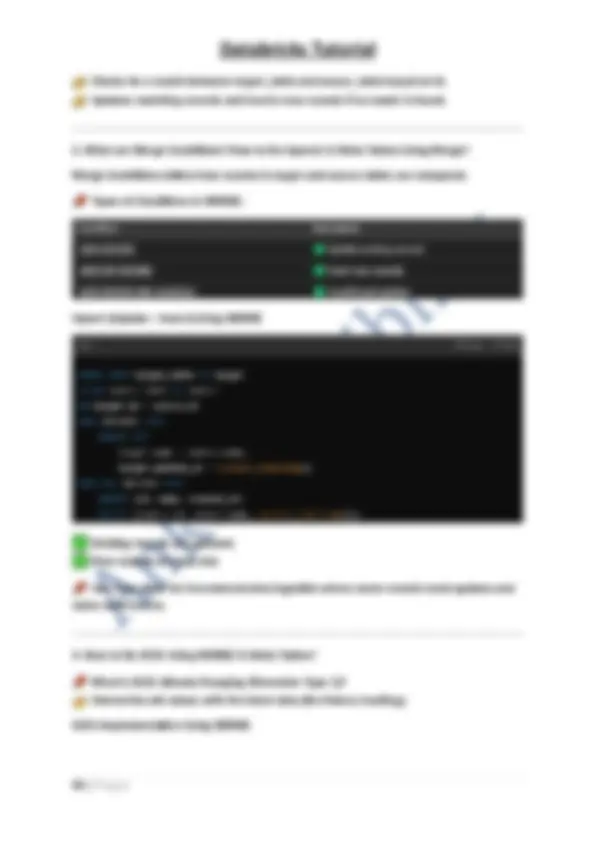
- Launch Databricks Notebooks for development. 4. Databricks Tiers and Pricing Databricks offers different pricing tiers based on compute usage and features. 1. Databricks Pricing Tiers
o Click the Cluster dropdown in the notebook UI and select an available cluster.
- Write & Execute Code: o Enter code in cells and press Shift + Enter to execute. o Use multiple languages in the same notebook with Magic Commands (covered later).
- Save & Share Notebooks: o Click File → Save or use Ctrl + S. o Share with team members via email, links, or repositories. 2. What Are Different Types of Cells in a Notebook? Databricks Notebooks support three main types of cells: Additional Features in Cells: ✔ Visualization Support : Create charts and graphs from query results. ✔ Collapsible Sections : Organize large notebooks efficiently. 3. What Are Language Magic Commands in Databricks Notebooks? Databricks Notebooks allow multiple programming languages in one notebook using Magic Commands. Common Magic Commands:
Tip: The default language of a notebook can be changed using Magic Commands dynamically.
4. How Databricks Helps in Collaboration? Databricks enhances collaboration by enabling teams to work together efficiently in notebooks and workflows. **Collaboration Features:
- Real-Time Editing:**
- Multiple users can edit a notebook simultaneously , similar to Google Docs.
- See real-time changes made by others. 2. Commenting System:
- Users can add inline comments to notebook cells.
- Use @mentions to notify teammates in discussions. 3. Notebook Sharing & Permissions:
- Share notebooks via URLs, Databricks workspace, or Git integration.
- Set permissions (View, Edit, Run, Manage) for team members. 4. Git Integration:
- Version control with GitHub, Azure DevOps, and Bitbucket.
- Use Databricks Repos for direct Git operations inside Databricks. 5. Databricks Workflows & Jobs:
- Automate data pipelines by scheduling jobs that execute notebooks.
- Enable team workflows for data engineering and ML models.
- Networking & Security : Databricks communicates with Azure Storage, AAD, and Key Vault securely through private endpoints.
- Billing & Monitoring : Costs are managed through Azure Billing , and usage is tracked in Azure Monitor. 2. How Databricks Clusters Are Spin-Up Using Azure VMs? A Databricks cluster consists of multiple Azure Virtual Machines (VMs) that run Apache Spark workloads. Cluster Lifecycle in Azure:
- User Creates a Cluster : o A cluster is requested via the Databricks UI, API, or Jobs.
- Azure Spins Up Virtual Machines : o Based on the VM type and size selected, Azure provisions Virtual Machines (VMs) in your subscription. o VMs are deployed in Azure Kubernetes Service (AKS) or Virtual Machine Scale Sets (VMSS).
- Databricks Installs Apache Spark : o The required Spark binaries and dependencies are installed on the nodes.
- Cluster Execution & Auto-Scaling : o Databricks dynamically scales the cluster (adds/removes worker nodes) based on workload demand.
- Cluster Termination : o When not in use, clusters auto-terminate to save costs. Key Cluster Components in Azure:
- Driver Node → Manages cluster execution & distributes tasks.
- Worker Nodes → Execute Spark computations in parallel.
- Databricks Runtime (DBR) → Optimized version of Apache Spark. 3. What is Databricks Managed Resource Group?
When you create an Azure Databricks workspace, Azure automatically creates a dedicated Managed Resource Group in your subscription. Purpose of Managed Resource Group: Contains all the Azure infrastructure needed for Databricks. Manages Networking, Storage, and Compute resources for Databricks. Azure manages this group; users shouldn’t modify or delete it manually. Key Resources Inside Managed Resource Group:
- Azure Virtual Machines (for Databricks Clusters)
- Databricks Virtual Network (VNet) (Handles cluster networking)
- Public IPs & Network Interfaces (For cluster communication)
- Databricks Storage Container (For DBFS - Databricks File System) 4. How Databricks Manages Compute in Azure? Databricks manages compute by dynamically provisioning and managing Azure Virtual Machines (VMs) for data processing. How Compute is Managed? Elastic Clusters : Databricks automatically provisions, scales, and terminates VMs based on workload demand. Spot Instances (Low-Cost VMs) : Uses Azure Spot VMs to reduce compute costs. Databricks Auto-scaling : Dynamically adds/removes worker nodes to handle varying workloads. High Availability : Distributes workloads across multiple Azure Availability Zones for fault tolerance. Compute Modes in Azure Databricks: Mode Description Use Case Standard Clusters Manual or auto-scaling clusters Ad-hoc queries, ETL jobs High Concurrency Clusters Optimized for multiple users Shared analytics, BI tools Job Clusters Created for a single job, auto- terminates Automated ETL jobs, ML training
- A Managed Resource Group is created to handle all Azure resources securely.
- Compute is managed efficiently through elastic clusters, Spot VMs, and high availability features.
- Managed Storage Containers store data, logs, and tables, providing a unified file system for analytics. Databricks Unity Catalog: A Complete Guide Databricks Unity Catalog is a unified data governance solution that provides fine-grained access control, metadata management, and lineage tracking across multiple clouds and data sources. It simplifies governance for structured, semi-structured, and unstructured data. 1. What is Unity Catalog? Unity Catalog is Databricks’ centralized data governance layer that enables: Fine-grained access control : Row/column-level security for users and groups. Data Lineage : Tracks end-to-end lineage for all assets in Databricks. Multi-cloud support : Works across AWS, Azure, and Google Cloud. Cross-workspace data sharing : Securely share data across multiple workspaces. Three-level namespace : Organizes data into Catalog → Schema → Tables. Why Use Unity Catalog?
- Ensures data security with centralized policy enforcement.
- Reduces compliance risks with audit logs and lineage tracking.
- Provides a unified interface for managing data across cloud platforms. 2. What is Metastore? How Databricks Governance Works? Metastore in Unity Catalog
- The Metastore is a top-level governance layer in Unity Catalog.
- It acts as a central metadata repository that stores information about catalogs, schemas, tables, and permissions.
- A single Metastore can be shared across multiple Databricks workspaces. Databricks Governance Model Access Control via Unity Catalog
- Users, groups, and service principals are assigned roles & permissions (Owner, Editor, Viewer).
- Fine-grained controls allow table, column, or row-level access policies. Data Lineage & Audit Logs
- Tracks lineage across ETL jobs, queries, and notebooks.
- Logs user activity for compliance & auditing. Secure Data Sharing
- Enables cross-workspace and cross-cloud data sharing without data duplication. 3. What is a Catalog in Databricks? A Catalog is the top-level container for organizing data within Unity Catalog.
- It acts as a collection of schemas and tables.
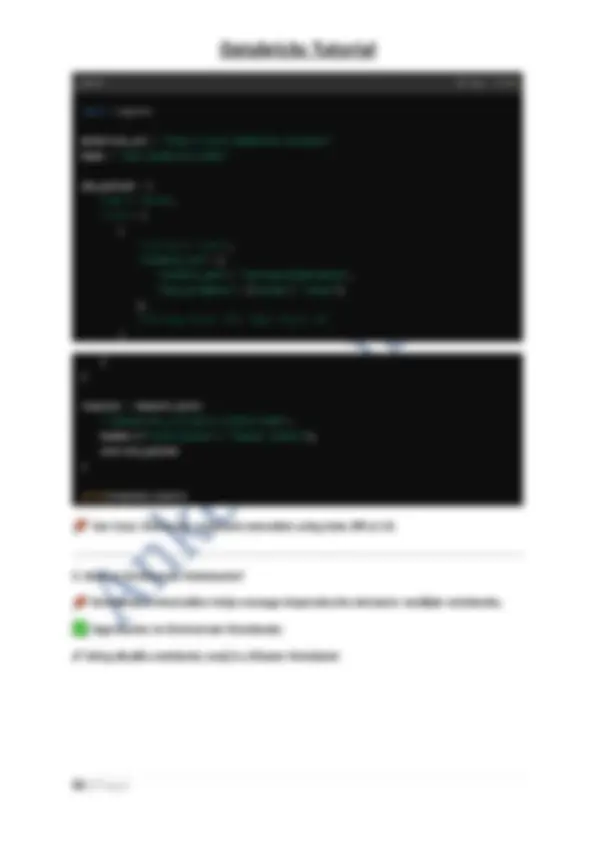
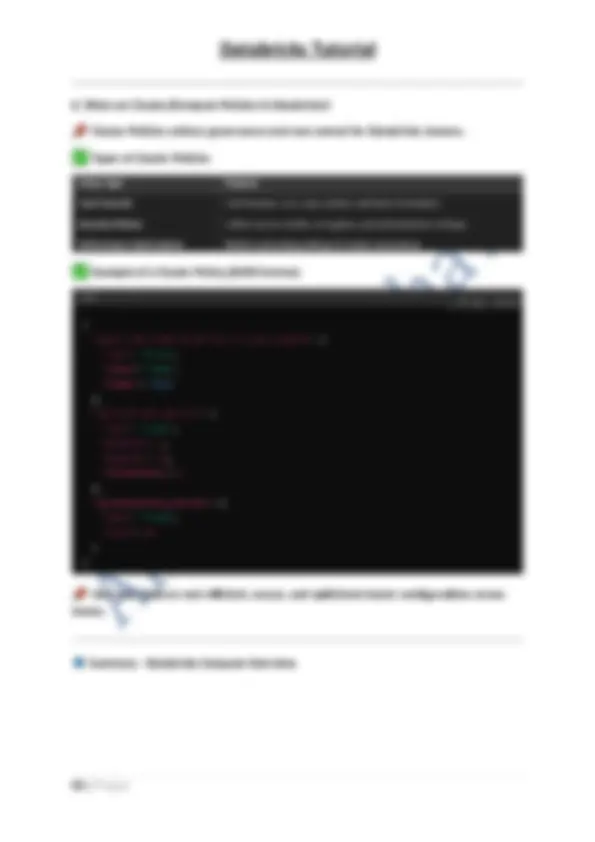
- A Catalog provides governance policies that define access at schema and table levels. Example: Sql CREATE CATALOG sales_data; USE CATALOG sales_data;
- Here, sales_data is a catalog that can contain multiple schemas (like transactions, customers). Hierarchy in Unity Catalog Metastore → Catalog → Schema (Database) → **Tables & Views
- What is Unity Catalog Data Governance Object Model?** The Unity Catalog Data Governance Model defines how objects are structured, governed, and secured in Databricks. Key Objects in Unity Catalog:
Conclusion
- Unity Catalog provides centralized governance, security, and data lineage in Databricks.
- Metastore is the top-level metadata repository , ensuring secure access to data.
- Catalogs organize schemas and tables , following a three-level namespace.
- Governance in Unity Catalog enforces fine-grained security policies for structured and unstructured data. Databricks: Hive Metastore, Tables, Views, and DBFS Databricks integrates with the Hive Metastore to manage metadata for databases, tables, and views. It provides managed and external tables for storing structured data, with different storage and governance models. Let's explore these concepts in a structured way. 1. What is Hive Metastore Catalog in Databricks? Hive Metastore in Databricks
- The Hive Metastore is a centralized metadata repository that keeps track of databases, tables, schemas, and views.
- It stores information about where data is stored (storage location), table schema (columns, data types), and permissions.
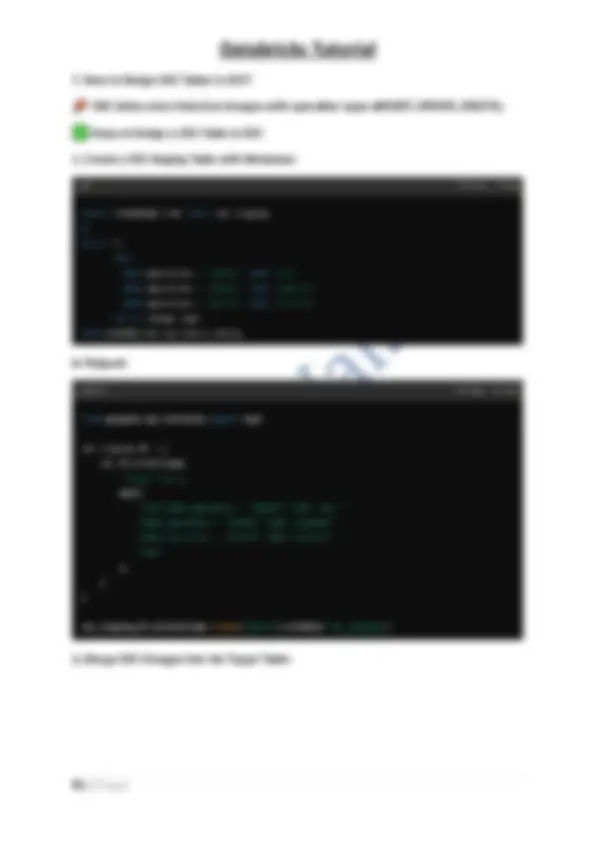
- In Databricks , the Hive Metastore is used by default to manage tables when Unity Catalog is not enabled. Key Features of Hive Metastore: Supports both managed and external tables. Stores metadata in a MySQL, PostgreSQL, or other relational database. Allows SQL-based metadata queries (SHOW TABLES, DESCRIBE TABLE). **Example: Checking Metadata in Hive Metastore
- What is a Managed Table?**
A Managed Table (also called an Internal Table ) is a table fully controlled by Databricks.
- Databricks manages both metadata and data storage.
- When a Managed Table is dropped, both the table and underlying data are deleted. Creating a Managed Table:
- Data is stored in the default location in DBFS (Databricks File System).
- Deleting the table removes both the metadata and data. Best Used When: ✔ You want Databricks to manage data storage automatically. ✔ You don’t need external storage management (like S3, ADLS, or GCS). 3. What is an External Table? An External Table in Databricks stores metadata in the Hive Metastore , but the actual data remains in an external storage system (like S3, ADLS, or GCS). Key Characteristics: Metadata is managed by Databricks , but data remains in external storage. Dropping the table only removes metadata ; the data remains untouched. Commonly used for data lakes, external data sources, or cross-platform access. Creating an External Table in Databricks:
- The table's metadata is stored in Hive Metastore.