Download Data Mining Lecture 1: Introduction to Data Warehousing, Filtering, and Mining and more Summaries Data Mining in PDF only on Docsity!
Data Warehousing, Filtering, and Mining
Lecture 1
- (^) Course syllabus
- Overview of data warehousing and mining Lecture slides modified from: - (^) Jiawei Han (http://www-sal.cs.uiuc.edu/~hanj/DM_Book.html) - (^) Vipin Kumar (http://www-users.cs.umn.edu/~kumar/csci5980/index.html) - (^) Ad Feelders (http://www.cs.uu.nl/docs/vakken/adm/) - (^) Zdravko Markov (http://www.cs.ccsu.edu/~markov/ccsu_courses/DataMining-1.html)
Course Syllabus
Meeting Days: Tuesday, 4:40P - 7:10P, TL Instructor: Slobodan Vucetic, 304 Wachman Hall, [email protected], phone: 204-5535, www.ist.temple.edu/~vucetic Office Hours: Tuesday 2:00 pm - 3:00 pm; Friday 3:00-4:00 pm; or by appointment. Objective: The course is devoted to information system environments enabling efficient indexing and advanced analyses of current and historical data for strategic use in decision making. Data management will be discussed in the content of data warehouses/data marts; Internet databases; Geographic Information Systems, mobile databases, temporal and sequence databases. Constructs aimed at an efficient online analytic processing (OLAP) and these developed for nontrivial exploratory analysis of current and historical data at such data sources will be discussed in details. The theory will be complemented by hands-on applied studies on problems in financial engineering, e-commerce, geosciences, bioinformatics and elsewhere. Prerequisites: CIS 511 and an undergraduate course in databases.
Course Syllabus
Late Policy and Academic Honesty: The projects and homework assignments are due in class, on the specified due date. NO LATE SUBMISSIONS will be accepted. For fairness, this policy will be strictly enforced. Academic honesty is taken seriously. You must write up your own solutions and code. For homework problems or projects you are allowed to discuss the problems or assignments verbally with other class members. You MUST acknowledge the people with whom you discussed your work. Any other sources (e.g. Internet, research papers, books) used for solutions and code MUST also be acknowledged. In case of doubt PLEASE contact the instructor. Disability Disclosure Statement Any student who has a need for accommodation based on the impact of a disability should contact me privately to discuss the specific situation as soon as possible. Contact Disability Resources and Services at 215-204-1280 in 100 Ritter Annex to coordinate reasonable accommodations for students with documented disabilities.
Motivation:
“Necessity is the Mother of Invention”
- (^) Data explosion problem
- (^) Automated data collection tools and mature database technology lead to tremendous amounts of data stored in databases, data warehouses and other information repositories
- (^) We are drowning in data, but starving for knowledge!
- (^) Solution: Data warehousing and data mining
- (^) Data warehousing and on-line analytical processing
- (^) Extraction of interesting knowledge (rules, regularities, patterns, constraints) from data in large databases
Why Mine Data? Scientific Viewpoint
- (^) Data collected and stored at
enormous speeds (GB/hour)
- (^) remote sensors on a satellite
- (^) telescopes scanning the skies
- (^) microarrays generating gene expression data
- (^) scientific simulations generating terabytes of data
- (^) Traditional techniques infeasible for raw
data
- (^) Data mining may help scientists
- (^) in classifying and segmenting data
- (^) in Hypothesis Formation
What Is Data Mining?
- (^) Data mining (knowledge discovery in databases):
- (^) Extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) information or patterns from data in large databases
- (^) Alternative names and their “inside stories”:
- (^) Data mining: a misnomer?
- (^) Knowledge discovery(mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, business intelligence, etc.
Data Mining: Classification Schemes
- (^) Decisions in data mining
- (^) Kinds of databases to be mined
- (^) Kinds of knowledge to be discovered
- (^) Kinds of techniques utilized
- (^) Kinds of applications adapted
- (^) Data mining tasks
- (^) Descriptive data mining
- (^) Predictive data mining
Decisions in Data Mining
- (^) Databases to be mined
- (^) Relational, transactional, object-oriented, object-relational, active, spatial, time-series, text, multi-media, heterogeneous, legacy, WWW, etc.
- (^) Knowledge to be mined
- (^) Characterization, discrimination, association, classification, clustering, trend, deviation and outlier analysis, etc.
- (^) Multiple/integrated functions and mining at multiple levels
- (^) Techniques utilized
- (^) Database-oriented, data warehouse (OLAP), machine learning, statistics, visualization, neural network, etc.
- (^) Applications adapted
- (^) Retail, telecommunication, banking, fraud analysis, DNA mining, stock market analysis, Web mining, Weblog analysis, etc.
Classification: Definition
- (^) Given a collection of records ( training set )
- (^) Each record contains a set of attributes , one of the attributes is the class.
- (^) Find a model for class attribute as a function of
the values of other attributes.
- (^) Goal: previously unseen records should be
assigned a class as accurately as possible.
- (^) A test set is used to determine the accuracy of the model. Usually, the given data set is divided into training and test sets, with training set used to build the model and test set used to validate it.
Classification Example
Tid Refund^ Marital Status Taxable Income Cheat 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes 10 categorical categorical continuous class Refund Marital Status Taxable Income Cheat No Single 75K? Yes Married 50K? No Married 150K? Yes Divorced 90K? No Single 40K? No Married 80K? 10 Test Set Training Set Model Learn Classifier
Classification: Application 2
- (^) Fraud Detection
- (^) Goal: Predict fraudulent cases in credit card
transactions.
- (^) Approach:
- (^) Use credit card transactions and the information on its account-holder as attributes. - (^) When does a customer buy, what does he buy, how often he pays on time, etc
- (^) Label past transactions as fraud or fair transactions. This forms the class attribute.
- (^) Learn a model for the class of the transactions.
- (^) Use this model to detect fraud by observing credit card transactions on an account.
Classification: Application 3
- (^) Customer Attrition/Churn:
- (^) Goal: To predict whether a customer is likely to be lost
to a competitor.
- (^) Approach:
- (^) Use detailed record of transactions with each of the past and present customers, to find attributes. - (^) How often the customer calls, where he calls, what time-of-the day he calls most, his financial status, marital status, etc.
- (^) Label the customers as loyal or disloyal.
- (^) Find a model for loyalty.
Classifying Galaxies
Early Intermediate Late Data Size:
- (^) 72 million stars, 20 million galaxies
- (^) Object Catalog: 9 GB
- (^) Image Database: 150 GB Class:
- (^) Stages of Formation Attributes: - (^) Image features, - (^) Characteristics of light waves received, etc.
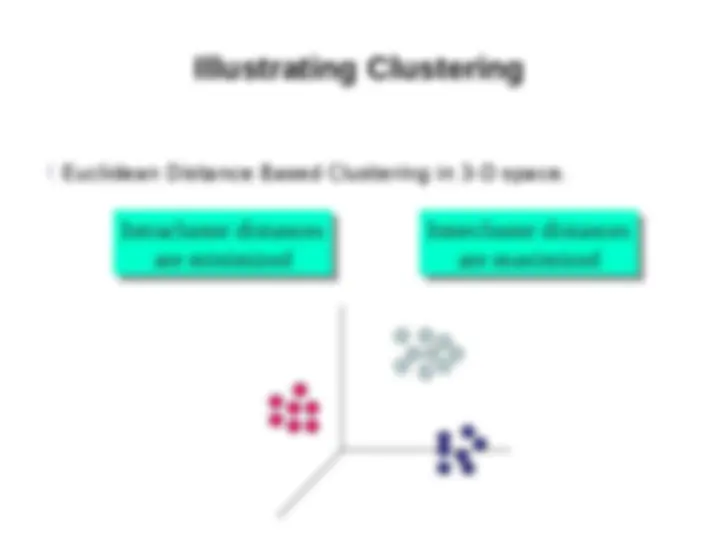
Clustering Definition
- (^) Given a set of data points, each having a set of
attributes, and a similarity measure among them,
find clusters such that
- (^) Data points in one cluster are more similar to one
another.
- (^) Data points in separate clusters are less similar to
one another.
- (^) Similarity Measures:
- (^) Euclidean Distance if attributes are continuous.
- (^) Other Problem-specific Measures.