


Decision tree learning
Sunita Sarawagi
IIT Bombay
http://www.it.iitb.ac.in/~sunita


























































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Decision Tree Classifiers lecture notes. CS 419
Typology: Lecture notes
1 / 67

This page cannot be seen from the preview
Don't miss anything!
Sunita Sarawagi
IIT Bombay
http://www.it.iitb.ac.in/~sunita
rules
works well on noisy data.
one or more attributes and leaf nodes are predicted
class labels.
Salary < 1 M
Prof = teaching
Good
Age < 30
Bad Bad
Good
age income student credit_rating buys_computer
<=30 high no fair no
<=30 high no excellent no
30…40 high no fair yes
40 medium no fair yes
40 low yes fair yes
40 low yes excellent no
31…40 low yes excellent yes
<=30 medium no fair no
<=30 low yes fair yes
40 medium yes fair yes
<=30 medium yes excellent yes
31…40 medium no excellent yes
31…40 high yes fair yes
40 medium no excellent no
Outlook Temperature Humidity Windy Play?
sunny hot high false No
sunny hot high true No
overcast hot high false Yes
rain mild high false Yes
rain cool normal false Yes
rain cool normal true No
overcast cool normal true Yes
sunny mild high false No
sunny cool normal false Yes
rain mild normal false Yes
sunny mild normal true Yes
overcast mild high true Yes
overcast hot normal false Yes
rain mild high true No
Note:
Outlook is the
Forecast,
no relation to
Microsoft
email program
overcast
high normal false
true
sunny
rain
No Yes No Yes
Yes
Outlook
Humidity
Windy
Gen_Tree (Node, data)
make node a leaf?
Yes
Stop
Find best attribute and best split on attribute
Partition data on split condition
For each child j of node Gen_Tree (node_j, data_j)
Selection
criteria
k
i
i i
1
k
i
i
1
2
0
p
1
1
Entropy
r
j
j
j
r
1
1
1
0
Gini
1
S
K= 2, |S| = 100, p
1
= 0.6, p
2
= 0.
E(S) = -0.6 log(0.6) - 0.4 log (0.4)=0.
S
1
S
2
| S
1
| = 70, p
1
= 0.8, p
2
= 0.
E(S
1
) = -0.8log0.8 - 0.2log0.2 = 0.
| S
2
| = 30, p
1
= 0.13, p
2
= 0.
E(S
2
) = -0.13log0.13 - 0.87 log 0.87=.
Information gain: E(S) - (0.7 E(S
1
) + 0.3 E(S
2
) ) =0.
Outlook Temperature Humidity Windy Play?
sunny hot high false No
sunny hot high true No
overcast hot high false Yes
rain mild high false Yes
rain cool normal false Yes
rain cool normal true No
overcast cool normal true Yes
sunny mild high false No
sunny cool normal false Yes
rain mild normal false Yes
sunny mild normal true Yes
overcast mild high true Yes
overcast hot normal false Yes
rain mild high true No
info([2,3]) entropy(2/5,3/5) 2 / 5 log( 2 / 5 ) 3 / 5 log( 3 / 5 ) 0. 971 bits
info([4,0]) entropy(1,0) 1 log( 1 ) 0 log( 0 ) 0 bits
info([3,2]) entropy(3/5,2/5) 3 / 5 log( 3 / 5 ) 2 / 5 log( 2 / 5 ) 0. 971 bits
Note: log(0) is
not defined, but
we evaluate
0*log(0) as zero
info([3,2], [4,0],[3,2]) ( 5 / 14 ) 0. 971 ( 4 / 14 ) 0 ( 5 / 14 ) 0. 971
0. 693 bits
witten&eibe
0. 247 bits
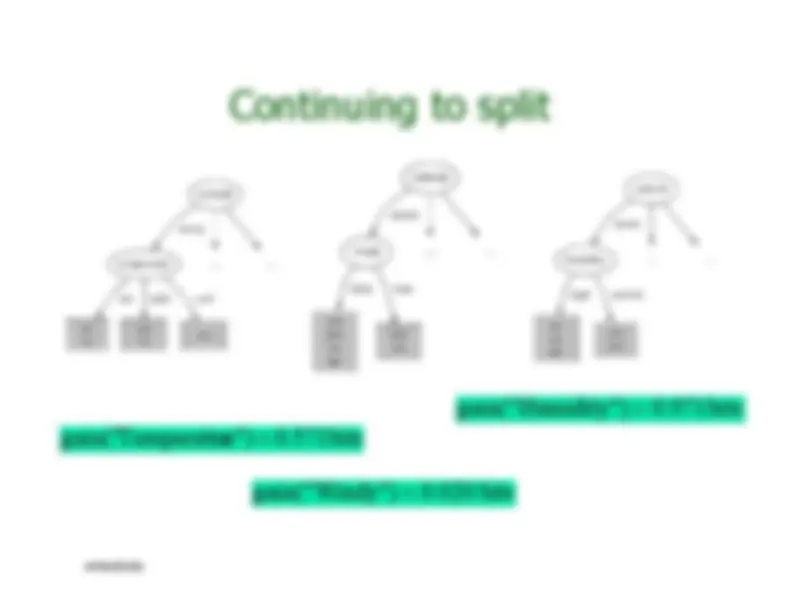
gain("Outlook" ) 0. 247 bits
gain("Temperatur e") 0. 029 bits
gain(" Humidity") 0. 152 bits
gain(" Windy") 0. 048 bits
witten&eibe