










































































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Discrete Maths notes for college students
Typology: Summaries
1 / 89

This page cannot be seen from the preview
Don't miss anything!
Topics to be Covered
Clustering for Data Understanding and Applications (^) Biology: taxonomy of living things: kingdom, phylum, class, order, family, genus and species (^) Information retrieval: document clustering (^) Land use: Identification of areas of similar land use in an earth observation database (^) Marketing: Help marketers discover distinct groups in their customer bases, and then use this knowledge to develop targeted marketing programs (^) City-planning: Identifying groups of houses according to their house type, value, and geographical location (^) Earth-quake studies: Observed earth quake epicenters should be clustered along continent faults (^) Climate: understanding earth climate, find patterns of atmospheric and ocean (^) Economic Science: market research
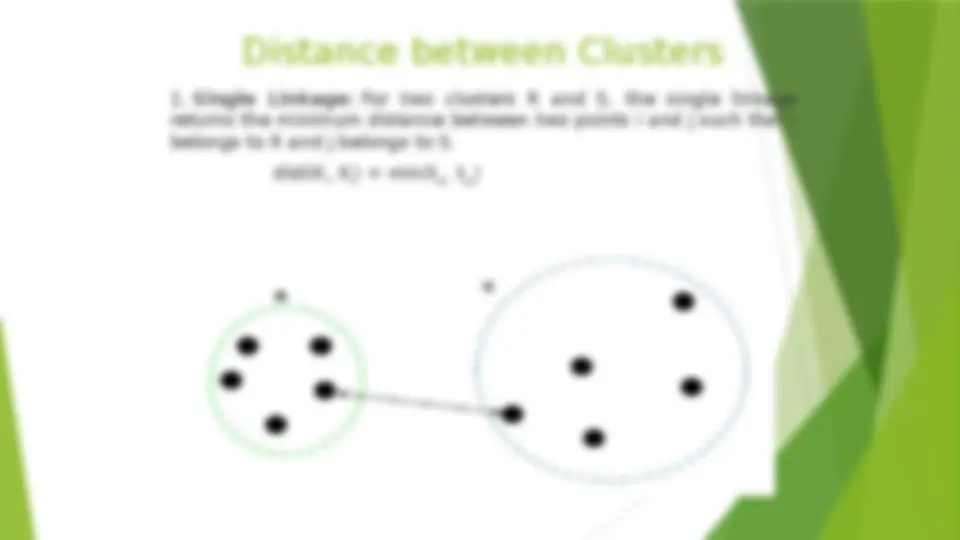
Quality: What Is Good Clustering? A good clustering method will produce high quality clusters (^) high intra-class similarity: cohesive within clusters (^) low inter-class similarity: distinctive between clusters (^) The quality of a clustering method depends on (^) the similarity measure used by the method (^) its implementation, and (^) Its ability to discover some or all of the hidden patterns
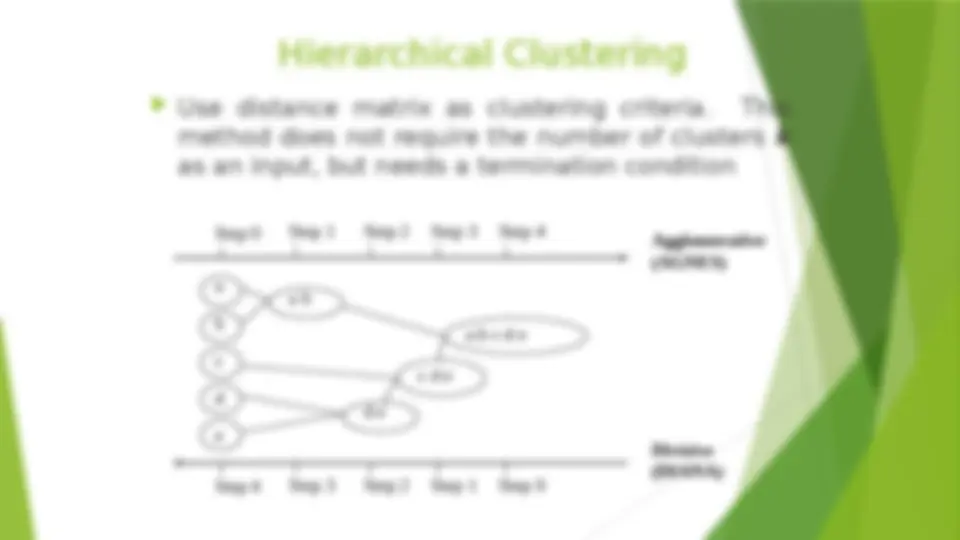
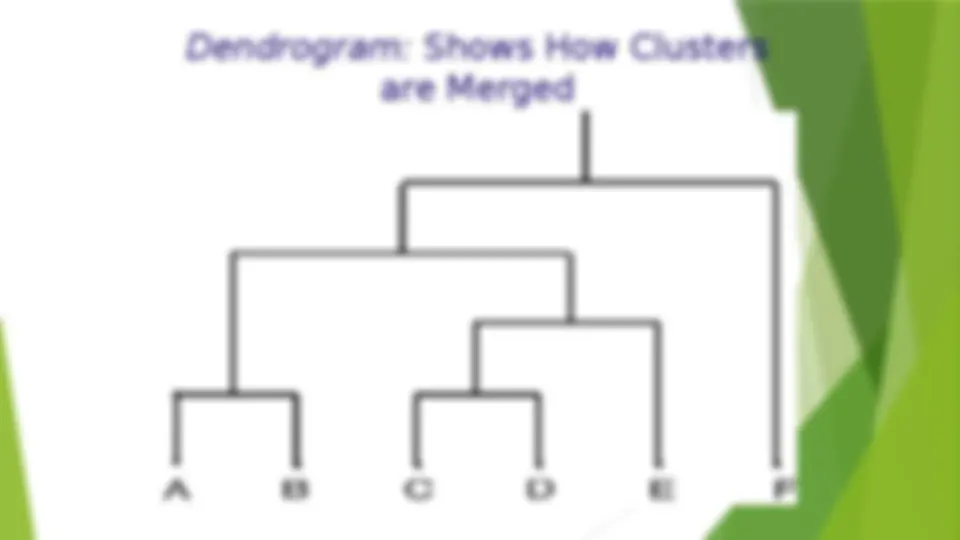
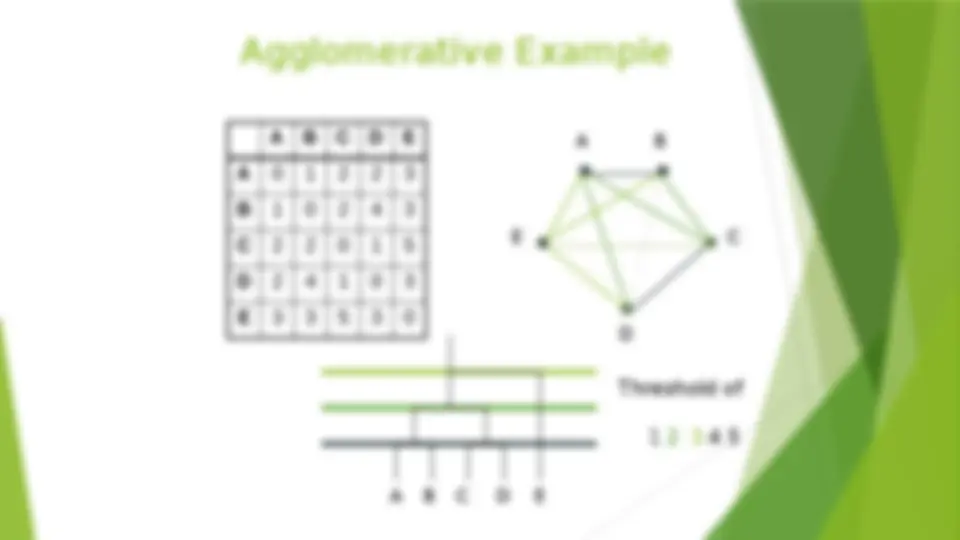
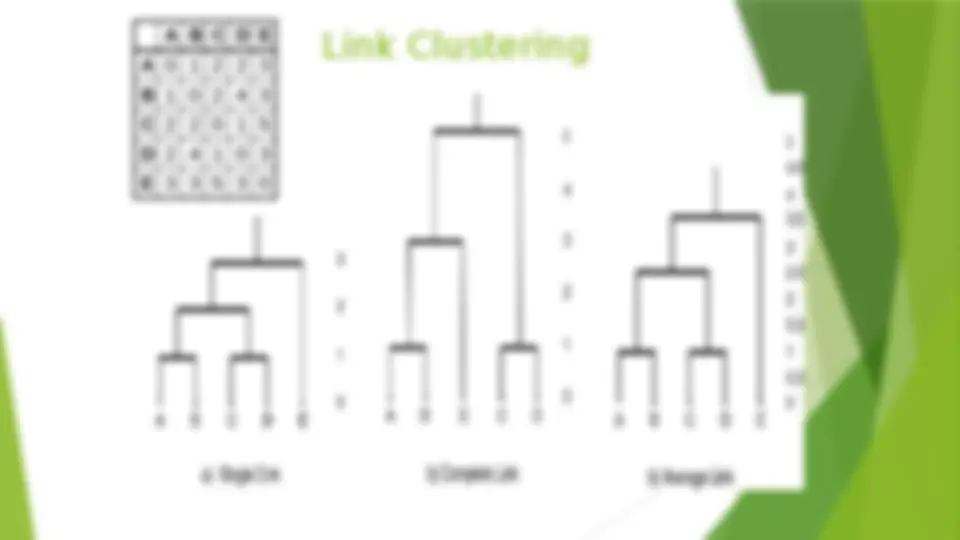
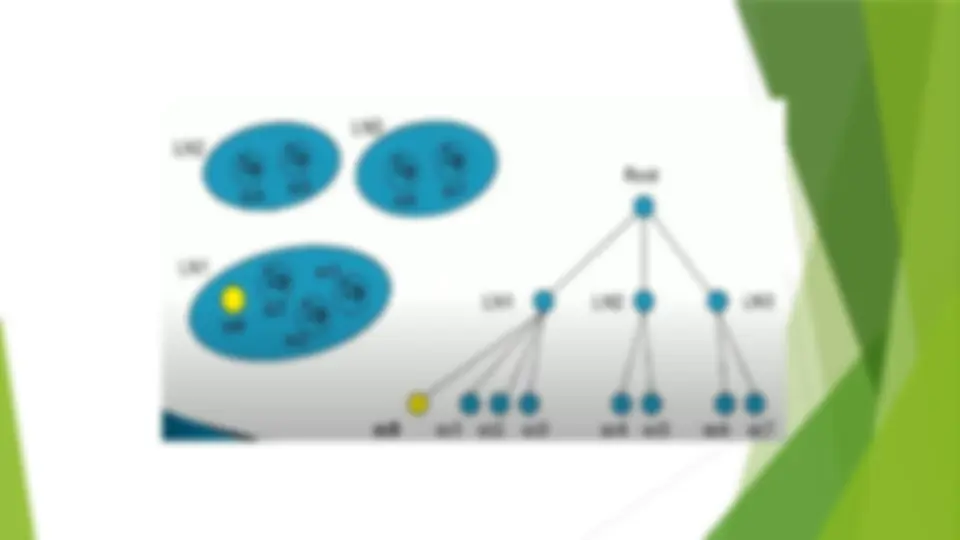
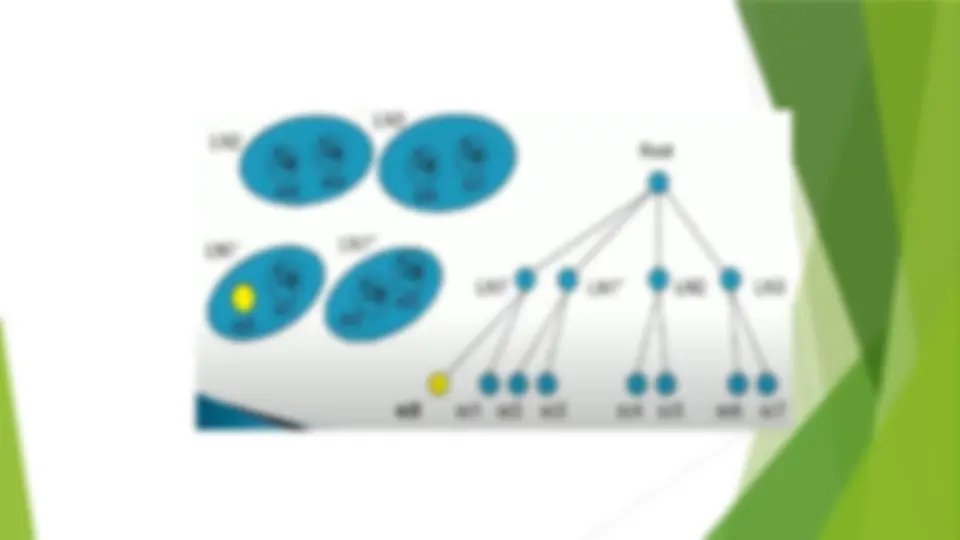
Considerations for Cluster Analysis (^) Partitioning criteria (^) Single level vs. hierarchical partitioning (often, multi-level hierarchical partitioning is desirable) (^) Separation of clusters (^) Exclusive (e.g., one customer belongs to only one region) vs. non-exclusive (e.g., one document may belong to more than one class) (^) Similarity measure (^) Distance-based (e.g., Euclidian, road network, vector) vs. connectivity-based (e.g., density or contiguity) (^) Clustering space (^) Full space (often when low dimensional) vs.
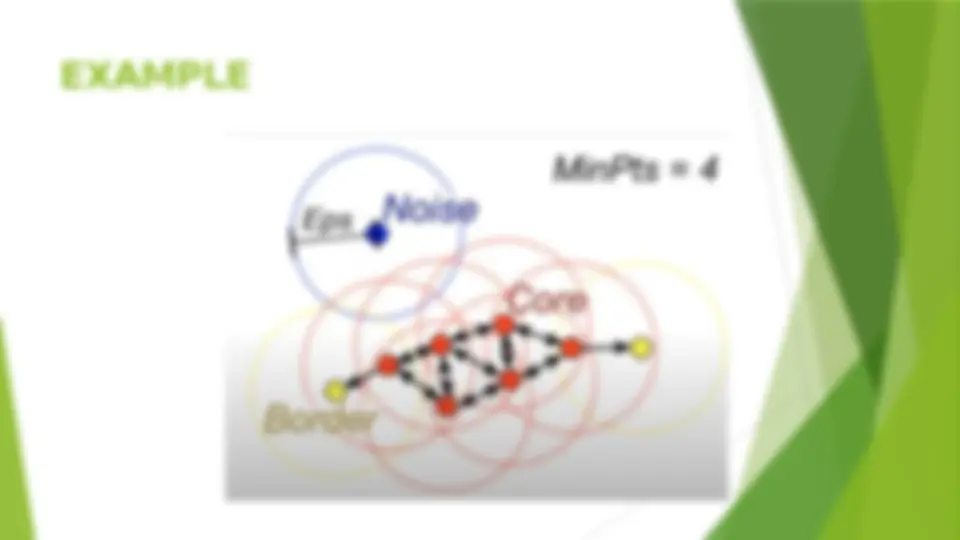
Requirements and Challenges (^) Scalability (^) Clustering all the data instead of only on samples (^) Ability to deal with different types of attributes (^) Numerical, binary, categorical, ordinal, linked, and mixture of these (^) Constraint-based clustering User may give inputs on constraints Use domain knowledge to determine input parameters (^) Interpretability and usability (^) Others (^) Discovery of clusters with arbitrary shape (^) Ability to deal with noisy data
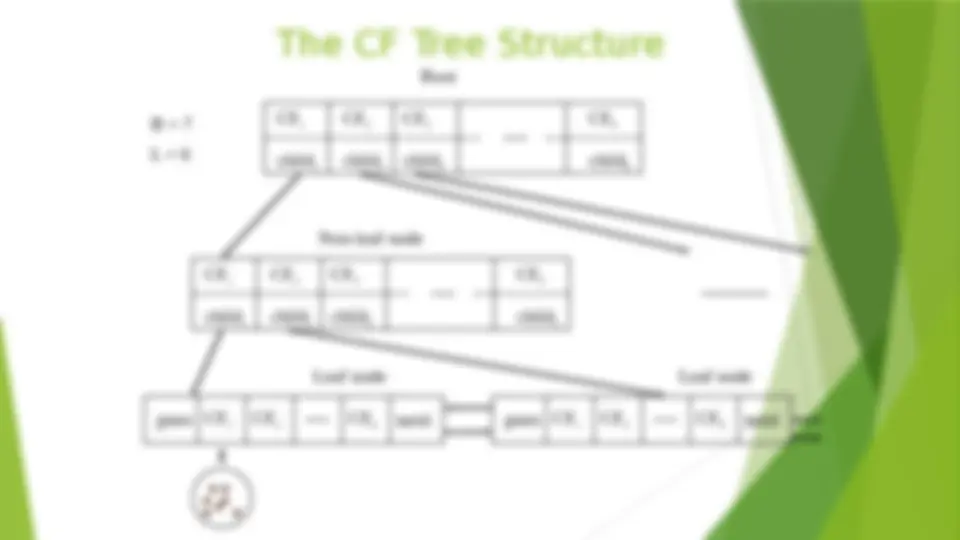
Major Clustering Approaches (II) (^) Model-based: (^) A model is hypothesized for each of the clusters and tries to find the best fit of that model to each other (^) Typical methods: EM, SOM, COBWEB (^) Frequent pattern-based: (^) Based on the analysis of frequent patterns (^) Typical methods: p-Cluster (^) User-guided or constraint-based: (^) Clustering by considering user-specified or application- specific constraints (^) Typical methods: COD (obstacles), constrained clustering (^) Link-based clustering: (^) Objects are often linked together in various ways (^) Massive links can be used to cluster objects: SimRank,
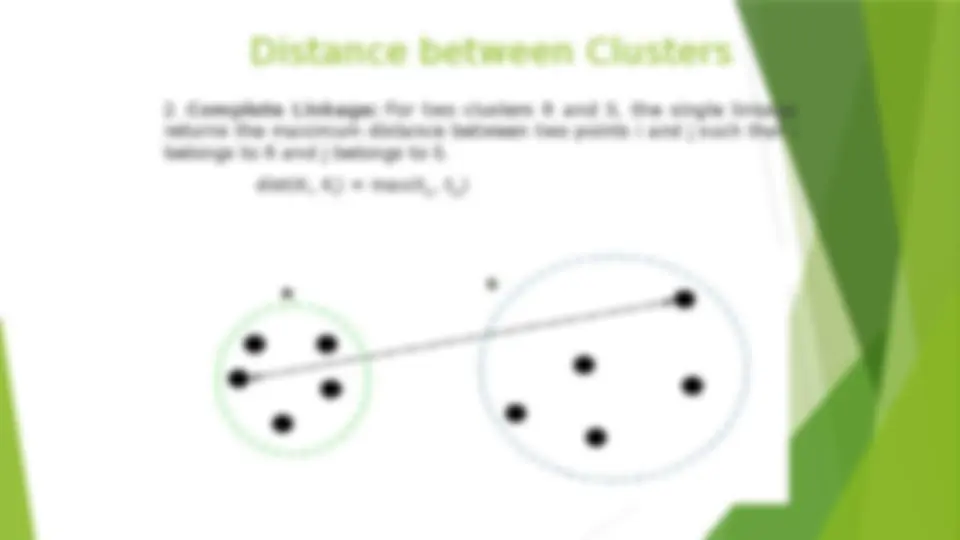
Partitioning Algorithms: Basic Concept (^) Partitioning method: Partitioning a database D of n objects into a set of k clusters, such that the sum of squared distances is minimized (where ci is the centroid or medoid of cluster Ci) (^) Given k , find a partition of k clusters that optimizes the chosen partitioning criterion (^) Global optimal: exhaustively enumerate all partitions (^) Heuristic methods: k-means and k-medoids algorithms (^) k-means : Each cluster is represented by the center of the cluster (^) k-medoids or PAM (Partition around medoids): Each 2 1 ( ) p C i k i E p c i
An Example of K-Means Clustering K= Arbitrarily partition objects into k groups Update the cluster centroids Update the cluster centroids Reassign objects Loop if needed The initial data set (^) Partition objects into k nonempty subsets (^) Repeat (^) Compute centroid (i.e., mean point) for each partition (^) Assign each object to the cluster of its nearest centroid (^) Until no change
ELBOW METHOD-TO FIND BEST K (SUM OF SQUARED ERROR)