



Distributed Databases
Docsity.com











Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of Advanced Database System are Types Supported, Simple Data Model, Concurrency Control Two, Continuously Adaptive, Cost-Based Optimization, Data Access From Disks, Data Warehousing. Main points of this lecture are: Distributed Databases, Distributed Data Independence, Distributed Transaction Atomicity, Logical Data Independence Principles, Data is Located, Accessing Multiple, Homogeneous, Types of Distributed Databases, Heterogeneous, Different Sites
Typology: Slides
1 / 20

This page cannot be seen from the preview
Don't miss anything!
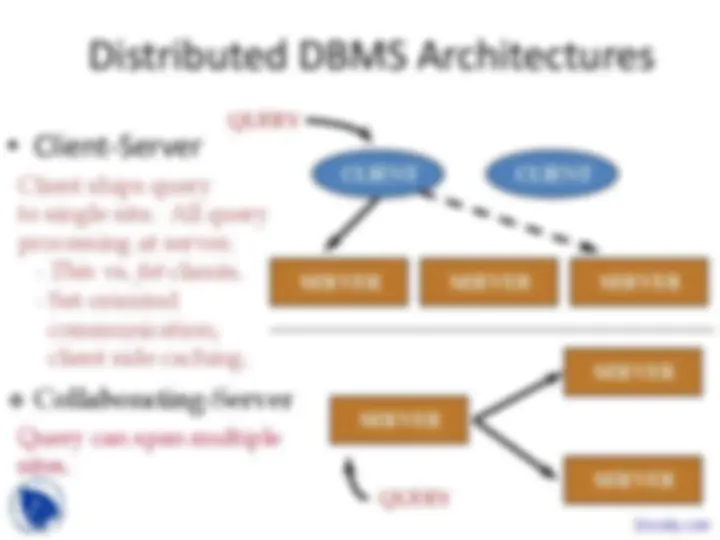
Collaborating-Server
CLIENT CLIENT
SERVER SERVER SERVER
QUERY
SERVER
SERVER
QUERY^ SERVER
Client ships query to single site. All query processing at server.
Query can span multiple sites.
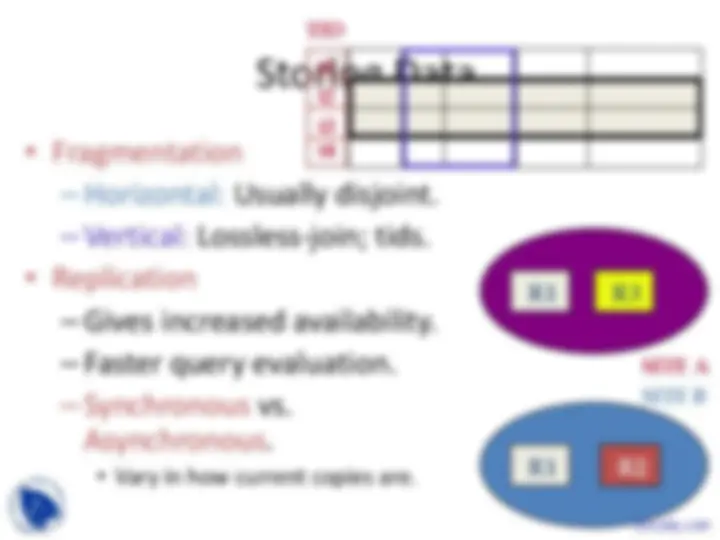
TID t t t t
R
R1 R
R
SITE A SITE B
SELECT AVG(S.age) FROM Sailors S WHERE S.rating > 3 AND S.rating < 7
Sailors Reserves
LONDON PARIS
500 pages 1000 pages
Sailors Reserves
LONDON PARIS
500 pages 1000 pages
Centralized (send all local graphs to one site);
Hierarchical (organize sites into a hierarchy and send local graphs to parent in the hierarchy);
Timeout (abort Xact if it waits too long). Docsity.com