Download Drawing DNA Sequence Networks and more Schemes and Mind Maps History in PDF only on Docsity!
Drawing DNA Sequence Networks
Julia Olivieri
June 21, 2016
Abstract
We explore methods for drawing a graph of DNA sequences on a digital canvas such that the Euclidean distances between sequences on the canvas suggest the distances between the sequences as calculated from pairwise sequence alignment. We use data from three plant taxa, the genus Castilleja as well as the families Caryophyllaceae and Cactaceae, to test our methods. We discuss different possible measures of the cost of a drawing, and analyze heuristic approaches to the problem including random assignment, greedy assignment, the iterated hill-climber, and simulated annealing. We find that our hill-climbing method tends to return superior drawings. Our simulated annealing method also returns drawings with low costs, but in much less time than the hill-climbing method for large datasets.
1 Introduction
1.1 Why visualize DNA sequence similarity?
Today we are facing a huge influx of newly sequenced DNA available to the public for analysis. This has been instrumental in many recent biological advances, from creating flu vaccines to cloning sheep. One particularly fascinating application is the use of DNA sequences to infer evolutionary histories of organisms, including how recently different species diverged from a common ancestor.
These relationships are usually inferred by gathering DNA sequences for the groups in ques- tion and determining the most likely chain of events that could give rise to the sequences, creating a phylogeny. Then the phylogeny is displayed with a bifurcating phylogenetic tree.
Phylogenetic trees provide useful information about relationships among sister groups, but it would be valuable to have other strategies for portraying connections among sequences.
For one thing, phylogenetic trees far from portray the whole story. True trees of life often aren’t strictly bifurcating: events such as hybridization and horizontal gene transfer can cause the true relationships to be more net-like. Also, finding alternate ways of portray- ing connections among DNA sequences visually could encourage new perspectives on the data.
There have been some studies that analyze population graphs of species and some that attempt to portray individual DNA sequences visually [1, 2]. However, we have not found any research attempting to graphically represent DNA sequence networks using the problem construction we are investigating here. We will explore different ways of representing DNA sequences on a canvas in a way that suggests relative differences among the DNA sequences. With so much new information, new ways to process and understand it are important.
1.2 Data sets
We choose three plant groups to use as case studies. Plants often have more entangled evolutionary histories than animals due to the rampancy of genome duplications and hy- bridization between taxa.
Castilleja
As botanist Harold William Rickett put it, “The genus Castilleia^1 is one of those that make botanists wish they had embraced some easy branch of science such as theoretical physics” [6]. It is in the Orobanchaceae family, which includes mostly herbaceous parasitic plants. This family is the largest and most diverse of all parasitic angiosperms (flowering plants), so understanding its phylogeny could throw light on which factors made it so successful [3]. Also, because the evolutionary history of Castilleja is so convoluted we may benefit from alternate methods of analysis to provide us with a clearer picture of its ancestral relationships. We have 19 sequences in our Castilleja dataset. See [3] for a phylogenetic tree.
Caryophyllales
This plant order accounts for 6% of angiosperm diversity, with about 11510 species across 34 families. This order originated between 67 and 121 million years ago, and contains species that span all seven continents and all terrestrial ecosystems. The amazing diversity of plants in this order makes it fascinating to study their phylogenetic history [7].
We chose two families from this plant order to include as datasets, Caryophyllaceae and and Cactaceae. Caryophyllaceae contains mostly small herbaceous plants which have com- plex morphological differences, making it difficult to determine the relationships between
(^1) alternative spelling, genus names are italicized
2 Graph Drawing
2.1 Formulation of the problem
We can represent DNA sequences as nodes in a weighted complete graph G. Let S be the set of DNA sequences, let |S| = n, and let the elements of S be s 1 ,... , sn. If si, sj ∈ S, let the weight wij of the edge sisj be defined as the cost of an optimal alignment of the two sequences, calculated as shown above (note that wij = wji).
(a) (b)
Figure 1: It is possible to place a sequence in any area that is white, and impossible to place a sequence in any area that is black. (a) In the continuous version all placements on the canvas are possible. (b) An example of the discrete case described above with l = 8.
Points
We have a square digital canvas that has height and width l. We will define the bottom left corner of the canvas to be (0, 0) and the top right corner to be (l, l). Let P be the set of possible point locations (points for short) on the canvas. These will be the places where we can draw nodes representing sequences in S. For p ∈ P , let (px, py) specify the point’s x- and y-coordinates on the canvas. Then we can define P continuously as
P = {(x, y) | 0 ≤ x ≤ l, 0 ≤ y ≤ l}
as shown in Figure 1a. However, it will be useful for us to consider discrete subsets of the continuous case. For example, we can consider the case where
P = {(x, y) | 0 ≤ x ≤ l, 0 ≤ y ≤ l, x, y ∈ Z}
as shown in Figure 1b.
Drawing
Let D be an injective mapping from S to P such that D(si) ∈ P , where D(si) denotes the point where we will draw si. Let dij be the Euclidean distance between D(si), D(sj ) ∈ P , so dij =
(D(si)x − D(sj )x)^2 + (D(si)y − D(sj )y)^2.
Our goal is to draw all the elements of S on the canvas such that the Euclidean distance between D(si) and D(sj ) ∈ P is in accordance with wij (up to scale). Preferably we would find a drawing that could be scaled such that wij = dij for all si, sj ∈ S. This would be called the ideal drawing I.
We know Euclidean distances satisfy the triangle inequality. One question immediately comes to mind: do the weights?
Claim 1 Weights on G obey the triangle inequality.
Proof. Let si, sj , sk ∈ S. Then we can change wij nucleotides of sequence si to make it identical to sj. We also know that we can make wjk changes to sj to make it identical to sk. Therefore we can transform si into sj and then into sk in at most wij + wjk nucleotide substitutions. Therefore wik ≤ wij + wjk, so weights on G obey the triangle inequality.
So we can see that the weights satisfy the triangle inequality. Does this mean that we will be able to draw all of our graphs ideally?
Claim 2 An ideal placement does not always exist.
Proof. Let’s look at a simple example. Let’s say we have the following sequences:
- AAAAA
- ATATA
- TTTTT
- AAATT
Using a substitution penalty of σ = 1 and a gap penalty of g = 2 we get the weight matrix:
W =
1 2 3 4 1 0 2 5 2 2 2 0 3 2 3 5 3 0 3 4 2 2 3 0
in our problem a higher weight means the sequences should be further apart. Also, our weights obey the triangle inequality, which isn’t guaranteed for flow. Additionally, we allow more points than sequences (analogous to having more locations than facilities in the QAP).
In 1998, it was impossible to solve the QAP to optimality within reasonable time limits for cases larger than n = 20. This was at a time when much progress had been made on other NP complete problems: the TSP could be solved with thousands of cities, and the maximum clique problem could be solved on graphs with thousands of vertices and millions of edges [10]. Even as recently as 2013 problems with n > 35 can’t be solved within reasonable computational time, and even finding an approximate solution within some constant factor of the optimal solution cannot be completed in polynomial time unless P=NP. This holds true even when the values obey the triangle inequality. In fact, even finding local optima is nontrivial [11].
Therefore, we need a different approach to solve our problem. We will use heuristic methods to approach optimal solutions.
2.3 Point placement
Our problem involves deciding where to place points on the canvas. By limiting the size of the possible point placements P (while always ensuring that |P | ≥ n) we limit our options, making the problem more tractable.
This means that we must find some method of choosing the elements of P. Figure 1b shows one method. We experimented with several others. Each exhibits different costs, as well as different aesthetics (see Figure 4). For consistency we chose to use the same point configuration for all of our images here. We chose the circle formation because it avoids the possibility of edges running over points that they don’t connect, which can be misleading.
2.4 Determining Cost
We want to find a drawing that approximates the ideal drawing. But what do we mean by “approximates the ideal drawing”? How can we tell if one drawing is closer to the ideal than another? To accomplish this we need some measure of the distance of a drawing from the ideal, or the cost of a drawing.
Figure 3: Several possible point placements, shown with both 16 and 100 nodes: random, square grid, skew grid, circle, multiple circles, skew multiple circles.
2.4.1 Euclidean cost
One possible measure of cost calculates the difference between the Euclidean distance between each pair of nodes on the canvas and the weight of each pair of nodes on the complete graph.
We can formulate this measurement as
C(D) =
si,sj ∈S
|kdij − wij |
where k = max(wij )/
2 l. Dividing the maximum weight on an edge of G by the maximum distance between two points on the canvas gives us a scaling factor that makes distances comparable to weights. We can also adapt this cost more specifically to various point
2.4.3 Flow cost
This cost is informed by the QAP formulation. Instead of measuring based on nucleotide differences we can use nucleotide similarities. If this information is not readily available we can approximate it by taking the average length of our sequences L. Then for si, sj ∈ S the number of nucleotides in agreement between the two sequences, aij , is approximately L − wij.
Now, the higher aij is, the closer we want si and sj. Therefore we can calculate
C(D) =
si,sj ∈S
dij aij.
Minimizing this cost measure encourages sequences that have more similarities to be closer together.
2.4.4 Cost choice
We report the same measure of cost for each image so that the costs can be directly compared. We chose the ordering cost because we are interested in the relative rather than absolute correct positioning. Also, the ordering cost yields the smallest values, so they are somewhat easier to understand and compare.
2.5 Heuristic methods
Given an l × l canvas, to find the optimal placement we might first think to try every combination of placing each s ∈ S at each point in P and comparing the costs. However, if |S| = n and |P | = m with n ≤ m we can see that the number of possibilities is
m! (m − n)!
If m = n = 13 there are already 6, 227 , 020 , 800 possible placements. We need a different approach if we are to use sets S of nontrivial size.
Because we cannot feasibly analyze every possible drawing given nontrivial sets S and P , we need a method to help us decide which drawings to analyze to give us close-to-optimal solutions. We turn to heuristic algorithms. Results of these methods are displayed in Table 1 and Figures 6, 7, and 8.
2.5.1 Random assignment
We can search indiscriminately through the space of drawings by choosing many random drawings and recording the drawing with the lowest cost. One run of the random assign- ment procedure consists of assigning each s ∈ S to a p ∈ P that has yet to be assigned to a sequence, creating drawing D. We then save the cost of D. We perform some predeter- mined number of runs r, each time calculating the cost and saving any D with a minimum cost.
This method does not retain any information from one run to the next, so it is truly a blind search. Assuming there is only one optimal solution, the chance of landing on it is
(|P | − n)! |P |!
)r .
This means that if n = |P | = 10 and r = 100000, there is only about a 2.72% chance of obtaining the optimal solution (assuming there is one optimum). However, a benefit of this method is that the program doesn’t get bogged down in any local optima.
2.5.2 Greedy assignment
The idea of this method is to assign one sequence at a time to its ‘best’ placement on the canvas.
For one run we start by randomly choosing an order for the elements in S. Assume si is at the ith place in this order. Then we randomly choose D(s 1 ) from P. We can then calculate the Euclidean cost of the single node placement of s 2 at p for each p ∈ P that has not yet been assigned a sequence. We then let D(s 2 ) equal the p ∈ P for which the Euclidean cost of the sequence was smallest (if there are multiple of these points, choose one randomly). We repeat this procedure for the remaining sequences.
2.5.3 Iterated hill-climber
Hill-climbing algorithms search a neighborhood of solutions that are close to the current solution in some way and find the most optimal solution in that neighborhood [12]. They are iterative methods, so the process is repeated until a local optimum is found.
A 2-swap of si and sj is a switch from the current map D to a new map D′^ for which D′(si) = D(sj ) and D′(sj ) = D(si) for some si, sj ∈ S, and D′(sk) = D(sk) for all other sk ∈ S.
In the simulated annealing procedure, we choose some temperature T > 1, ratio q ∈ (0, 1), and number of runs r. We start with a random drawing D. The cost of our current drawing is cur. Then we perform a 2-swap and find the cost of D′, new. If new is the lowest cost we have calculated so far we save new as opt and D′^ as optD. If the new cost is less than our current cost cur, we save it as cur and D′^ becomes our current drawing. If not, we choose a random b ∈ [0, 1). Then if
b < e(cur−new)/T
D′^ still becomes our current drawing. Otherwise, we maintain D as our current draw- ing.
Note that cur −new ≤ 0, because the new cost must be greater than or equal to the current cost (otherwise we would have automatically accepted it).
After we’ve done this r times, we set T equal to qT and perform the procedure again. We continue until T ≤ 1. Then we return optD.
We settled on T = 100 and q = 0.75 for our datasets because they resulted in drawings of comparable cost to those generated by the hill-climbing method, but still allowed the procedure to finish in a reasonable amount of time. Adjusting the initial value of T and the value of q could yield better drawings, but could also take more time.
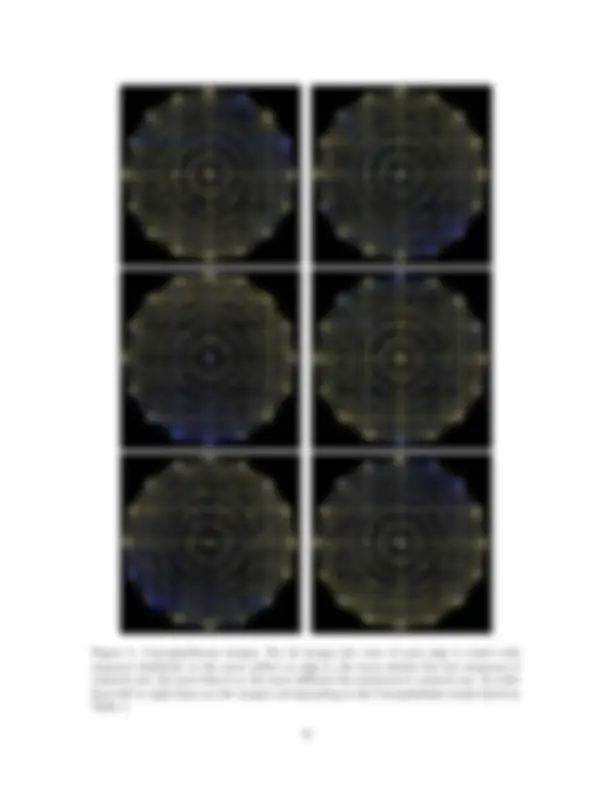
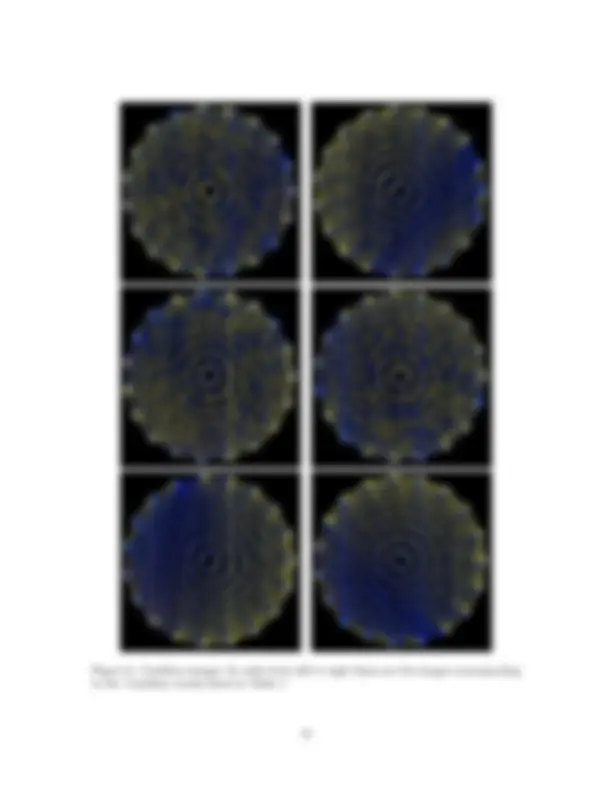
Figure 5: Caryophyllaceae images: For all images the color of each edge is scaled with sequence similarity, so the more yellow an edge is, the more similar the two sequences it connects are; the more blue it is, the more different the sequences it connects are. In order from left to right these are the images corresponding to the Caryophyllales results listed in Table 1.
Figure 7: Cactaceae images: Not all edges are shown in these drawings; only those with a number of nucleotide differences less than or equal to the maximum number of differences divided by 5. This is to avoid many edges being completely covered up. In order from left to right these are the images corresponding to the Cactaceae results listed in Table 1.
Conclusion
We have now tried several methods for creating drawings of sets of DNA sequences. The question remains: which of the methods we have tried is best? The answer is not completely straightforward. Although the hill-climber consistently generated drawings with the lowest costs, we are also interested in differences in runtime that make some methods more feasible than others. See Table 1 for a breakdown of our results (the images corresponding to each of these results can be found in Figures 6, 7, and 8).
Dataset Result # Method Runs Cost Runtime (sec) 1 random 1 1256 0. 2 random 10000 966 22. Caryophyllaceae 3 greedy 1 1004 0. 4 greedy 10000 986 38. 5 hill climbing 10 856 31. 6 simulated annealing 1000 858 35. 7 random 1 1958 0. 8 random 10000 1522 32. Castilleja 9 greedy 1 2100 0. 10 greedy 10000 1430 59. 11 hill climbing 10 1164 78. 12 simulated annealing 1000 1180 53. 13 random 1 176386 11. 14 random 10000 164250 1304. Cactaceae 15 greedy 1 134830 8. 16 greedy 1000 170238 312. 17 hill climbing 1 96476 39303. 18 simulated annealing 1000 99678 2098.
Table 1: Comparison of heuristic methods.
For results 3, 9, and 15 we didn’t use a random ordering: instead, we used the order the sequences appeared on the phylogenetic tree.
For the small datasets, Caryophyllaceae and Castilleja, the greedy method in results 4 and 10 barely outperformed the random method in results 2 and 8, with slightly lower costs that took about double the time. The hill-climbing and simulated annealing methods performed best, both yielding comparable costs and runtimes. Tweaking the parameters T and q, as well as the number of runs, for the simulated annealing method could yield superior results within a reasonable amount of time. However, strictly from our results here the hill climbing and simulated annealing approaches both seem viable for creating images of small datasets. In both of these datasets the ranges of costs are relatively small,
References
[1] Rodney J. Dyer and John D. Nason. Population graphs: the graph theoretic shape of genetic structure. Molecular Ecology, 13:1713–1727, 2004. [2] Ashesh Nandy, Marissa Harle, and Subhash C. Basak. Mathematical descriptors of DNA sequences: development and applications. Archive of Organic Chemistry, 9:211– 238, 2006. [3] Jonathan R. Bennett and Sarah Mathews. Phylogeny of the parasitic plant fam- ily Orobanchaceae inferred from phytochrome A. American Journal of Botany, 93(7):1039–1051, 2006. [4] Simone Fior, Per Ola Karis, Gabriele Casazza, Luigi Minuto, and Francesco Sala. Molecular phylogeny of the Caryophyllaceae (Caryophyllales) inferred from chloroplast matK and nuclear rDNA ITS sequences. American Journal of Botany, 93(3):399–411,
[5] Reto Nyffeler. Phylogenetic relationships in the cactus family (Cactaceae) based on evidence from trnK/matK and trnL-trnF sequences. American Journal of Botany, 89(2):312–326, 2002. [6] Harold William Rickett. Wild Flowers of the United States, volume 1. Hinkhouse Inc, New York, New York, 1966. [7] Samuel F. Brockington, Ya Yang, Fernando Gandia-Herrero, Sarah Covshoff, Ju- lian M. Hibberd, Rowan F. Sage, Gane K. S. Wong, Michael J. Moore, and Stephen A. Smith. Lineage-specific gene radiations underlie the evolution of novel betalain pig- mentation in Caryophyllales. New Phytologist, 207(4):1170–1180, 2015. [8] National Library of Medicine. BLAST ©R, 2016. http://blast.ncbi.nlm.nih.gov /Blast.cgi. [9] Istv´an Mikl´os. Introduction to Algorithms in Bioinformatics. Budapest, Hungary,
- http://www.renyi.hu/ miklosi/AlgorithmsOfBioinformatics.pdf.
[10] Eranda C¸ ela. The Quadratic Assignment Problem: Theory and Algorithms. Springer Science+Business Media, B.V., Dordrecht, Holland, 1998.
[11] Rainer E. Burkard. Handbook of Combinatorial Optimization. Springer Reference, Media, New York, 2013.
[12] Zbigniew Michalewicz and David B. Fogel. How to Solve it: Modern Heuristics. Springer, Berlin, Germany, 2002.
Apendix 1: Terminology
term definition
- the gap symbol C(D) the cost of drawing D D an injective map from S to P (a drawing of S on the canvas) D(si) the element of P that D maps si to dij the Euclidean distance between D(si) and D(sj ) G the complete graph with sequences as nodes and wij as the weight on edge sisj g the gap penalty (σ < g) I ideal drawing: injective map from S onto P for which wij = dij k max(wij )/
2 l l side length of canvas m |P | n |S| P the set of points on the canvas available for assignment px for p ∈ P , this is the x coordinate of the position on the canvas py for p ∈ P , this is the y coordinate of the position on the canvas q the ratio for simulated annealing, q ∈ [0, 1) r the number of runs for a heuristic method S the set of DNA sequences si an element of S σ the substitution penalty (σ < g) T the temperature for simulated annealing, T > 1 wij the cost of the alignment of si and sj