Download DSA Assignment 1 - BTEC and more Study Guides, Projects, Research Data Structures and Algorithms in PDF only on Docsity!
PROGRAM TITLE: BTEC-COMPUTING ( Software Engineering) UNIT TITLE: Data Structure and Algorithm ASSIGNMENT NUMBER: 01 ASSIGNMENT NAME: Optimum Cargo Ship Routing (OASR) SUBMISSION DATE: 29/10/ DATE RECEIVED: 29/10/ TUTORIAL LECTURER: Nguyen Ngoc Tan WORD COUNT: 5047 STUDENT NAME: Đào Hà Dương STUDENT ID: BKC MOBILE NUMBER: +84 867671512
Summative Feedback:
- I. Introduction........................................................................... Table of Contents
- II. Theoretical Basis...................................................................
- Data Structure and Algorithm..............................................
- a. Data Structures................................................................
- b. Algorithm........................................................................
- c. The importance of data structures and algorithms.............
- d. Abstract Data Type (ADT).................................................
- e. Queue.............................................................................
- f. Stack..............................................................................
- g. First in First out (FIFO)...................................................
- h. Shortest path algorithm analysis.....................................
- orientation offering a justification for the view.................... i. Discuss the view that imperative ADTs are a basis for object
- structures.......................................................................... j. Benefits of using implementation independent data
- Design Specification..........................................................
- a. What is Specification and Description Language?.............
- b. Organization of SDL........................................................
- SDL Behavior..................................................................... c. Specify the abstract data type for a software stack using
- Error handling..................................................................
- a. What is error handling testing?.......................................
- b. Objective of error handling testing..................................
- c. Avantages......................................................................
- d. Disadvantages..............................................................
- The effectiveness of data structures and algorithms...........
- a. Why performance analysis?.............................................
- b. What is Asymptopic Analysis? Asymptopic Notation?........
- c. Compare the performance of two sorting algorithms........
- of time and space trade-off?............................................... d. What do you understand by time and space trade-off? Type
- III. Implementation..................................................................
- Evaluate the complexity of an implemented ADT.................
- Source code and evidence (result).....................................
- IV. Reference..........................................................................
- Figure 1: Example Stack implementation.................................... Figure of Content
- Figure 2: Queue........................................................................
- Figure 3: Graph G....................................................................
- Figure 4: Step 1......................................................................
- Figure 5: Step 2......................................................................
- Figure 6: Step 3......................................................................
- Figure 7: Step 4......................................................................
- Figure 8: Step 5......................................................................
- Figure 9: Step 6......................................................................
- Figure 10: Step 7.....................................................................
- Figure 11: Step 8.....................................................................
- Figure 12: Step 9.....................................................................
- Figure 13: Symbol SDL.............................................................
- Figure 14: Example BigO..........................................................
- Figure 15: Example Omega......................................................
- Figure 16: Example Theta........................................................
- Figure 17: Compare Sort..........................................................
b. Algorithm Define An algorithm is a method consisting of steps that determines a set of statements to be executed in a certain order in order to achieve a desired output. Algorithms are often created independently of programming languages, which means that an algorithm can be implemented in many different programming languages. Types of Algorithm There are several types of algorithms available. Some important algorithms are: Search Algorithm: Search for a unit of data in a data structure. Sort Algorithm: Sort the data units in a certain order. Insert Algorithm: Inserts data into a data structure. Update Algorithm: Updates an existing data unit in a data structure. Delete Algorithm: Deletes an existing data unit from a data structure. Not all methods can be called an algorithm, to ensure a complete algorithm we need to ensure that it includes the following characteristics: Clarity: Every step, input and output must be clear. Input: An algorithm must have a well-defined input. Output: An algorithm must have one or more well-defined outputs. Finitude: The algorithm must terminate after a finite number of steps. Feasibility: Can be done and deliver results. Independence: An algorithm must have step-by-step instructions, independent of any programming language. c. The importance of data structures and algorithms We can see not only programming languages like Java, PHP, Python, etc., but no matter what language you use, you need to know about data structures and algorithms to solve problems. Language is just a tool, data structures and algorithms are methods. Therefore, data structures and algorithms play a very important role in programming. The subject of data structures and algorithms plays a very important role It is a fact that in the recruitment process, one of the first factors employers consider is your skills in data structures and algorithms, and then the programming languages you can use.. And of course, you will have to master both factors above to be able to meet the requirements of the job. Therefore, learning data structures and algorithms is extremely important in these fields. In the future, in addition to writing code, you can also become a software designer or team leader of project management if you persevere in practice and constantly improve your skills. d. Abstract Data Type (ADT) Define Abstract Data type (ADT) is a type (or class) for objects whose behaviors is defined by a set of value and a set of operations. The definition of ADT only mentions what operations are to be performed but not how these operations will be implemented. It does not specify how datawill be organized in memory and what algorithms will be used for implementing the operations. It is called “abstract” because it gives an
implementation-independent view. The process of providing only the essentials and hiding the details is known as abstraction. The advantages of encapsulation and information hiding when using an ADT. Encapsulation and information hiding are key concepts used in object-oriented programming. Information hiding means separating the description of how to use a class from the implementation details. The idea of information hiding is that a programmer will be able to use a class we write without needing to know how the methods are implemented. All the programmer needs to know is what they provide to the class, and what they get in return. This keeps the amount of information needed to use a class minimal, meaning in turn that applying our classes is easier to do. Encapsulation means grouping software into units in such a way that it is easy to use with well-defined simple interfaces. Encapsulation and information hiding are related to each other, since both have a goal of making classes easier to use. The way that we make classes easy to use is by hiding the details of the implementation. This, in turn, makes the interfaces that face the user easier to understand. Hiding details from the user of a class can be done with scope. When we have publically scoped variables and functions, anything outside a class can access them. If we want to hide variables and functions, we simply make them private scope instead. When we are implementing encapsulation, we will typically make all property variables private, and define public methods to be able to set and get their values, known as accessor and mutator methods. As an example, let’s take a look at a typical Stack implementation. Figure 1 : Example Stack implementation
isEmpry(): This is used to check whether queue is empty or not size(): this function is used to get number of elements present into the queue f. Stack Define A stack is an associate ordered a set of components, only one of that (last added) are often accessed at a time. The point of access is named the highest of the stack. The number of components within the stack, or length of the stack, is variable. Items could solely be side to or deleted from the highest of the stack. For this reason, a stack is additionally referred to as a pushdown list or a last-in-first-out (LIFO) list. The operations of Queue ADT push(): Add an element to the top of a stack pop(): Remove an element from the top of a stack isEmpty(): Check if the stack is empty isFull(): Check if the stack is full peek(): Get the value of the top element without removing it The operations of a memory stack and how it is used to implement function calls in a computer. Any modern computer environment uses a stack as the primary memory management model for a running program. Whether it’s native code (x86, Sun, VAX) or JVM, a stack is at the center of the run-time environment for Java, C++, Ada, FORTRAN, etc. The discussion of JVM in the text is consistent with NT, Solaris, VMS, Unix runtime environments. Each program that is running in a computer system has its own memory allocation containing the typical layout as shown below: g. First in First out (FIFO)
Define FIFO is an abbreviation for first in, first out. It is a method for handling data structures where the first element is processed first and the newest element is processed last. Example of FIFO Queue Create a queue of 10 elements from 0 to 9. Then remove the first element then define the first and last element after that QueueExample.java package FIFOQueue; import java.util.LinkedList; import java.util.Queue; public class QueueExample { public static void main(String[] args) { Queue q = new LinkedList<>(); // Adds elements {0, 1, 2, 3,...,9} to // the queue for (int i = 0; i < 10; i++) q.add(i); System.out.println("Elements of queue "
- q); // To remove the head of queue. int removedele = q.remove(); System.out.println("removed element-"
- removedele); System.out.println(q); int head = q.peek(); System.out.println("head of queue-"
- head); int size = q.size(); System.out.println("Size of queue-"
- size); } } Result Elements of queue [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] removed element- [1, 2, 3, 4, 5, 6, 7, 8, 9]
Figure 5 : Step 2 After considering all vertices, we choose vertex 2 with the smallest distance and record it for further consideration. Continue to consider adjacent vertices of 2 as vertices 4 and 5 with the above principle. Considering vertex 4, the distance from the original vertex to vertex 4 will be equal to the distance from the original vertex to vertex 2 plus the distance from 2 to 4. That is, 2.0+0.6=2.6 so we record the distance at vertex 4 is (2.6, 2). Consider the same for vertex 5. Figure 6 : Step 3 At this point, we can choose the vertex 3 with the smallest distance, considering that the adjacent vertex of vertex 3 is vertex 5. The distance from the origin to vertex 5: 2.1+2.5=4.6 is larger than the current recorded distance. received, so the value at vertex 5 remains unchanged.
Figure 7 : Step 4 The vertex 1 is the next selected vertex, considering the adjacent vertex of 1 is vertex
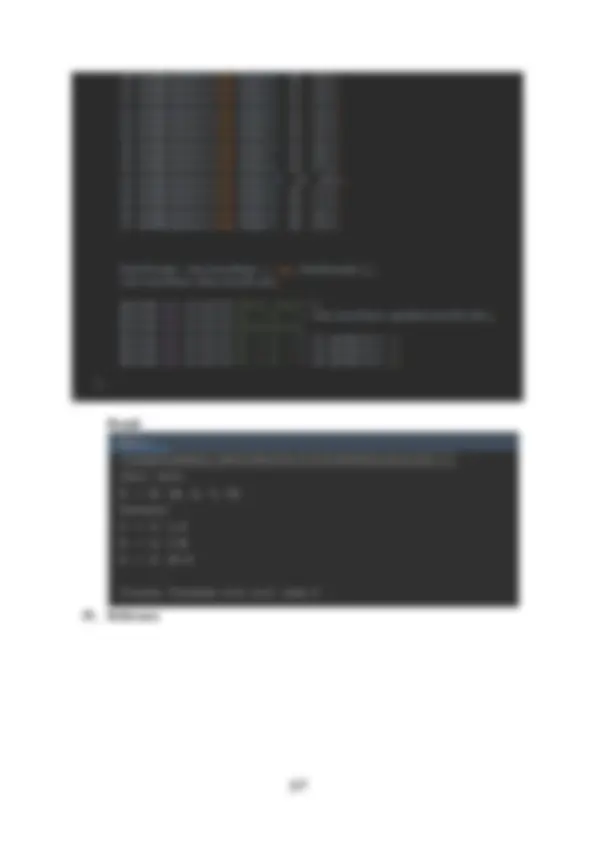
- The distance from the original vertex is not less than the current distance, so we do not update anything at this vertex. Figure 8 : Step 5 After reviewing, we choose vertex 4 as the next vertex. We update the new value for vertex 6.
Figure 11 : Step 8 Select the vertex with the smallest distance as vertex 7. Figure 12 : Step 9 The algorithm terminates when the minimum distance is selected for all vertices. i. Discuss the view that imperative ADTs are a basis for object orientation offering a justification for the view. ADT allows creation of instances with well-defined properties and behavior.
Abstraction allows one to collect instances of entities into groups in which their common attributes need to be considered. Data abstraction is an encapsulation of a data type and the subprograms that provide the operations for that type. In object-orientation, ADTs may be referred to as classes. Therefore, a class defines properties of objects which are the instances in an object-oriented environment. Programs can declare instances of that ADT, called an object. Object-oriented programming is based on this concept. j. Benefits of using implementation independent data structures. The three benefits of using implementation independent data structure(abstract data structure)- Efficient memory use: By the efficient use of data structure the uses of memory can be optimized. If the size of data is not sure then we can use linked list vs array data structure. If there is no more use of memory, then it can release. Re usability: It can be reused, once we implemented a particular data structure, we can use it any other place. The implementation of the data structure can be compiled into libraries which can be used by different clients. Abstraction: Data structures serves as the basis of abstract data types, the data structure defines the physical forms of ADT(Abstract Data Type).
2. Design Specification a. What is Specification and Description Language? Specification and Description Language (SDL) is a standardized language used for the description system architecture, behaviour of system components. SDL is based on experience within the telecommunications industry in describing systems as communicating state machines. It is developed and maintained by ITU-T as ITU Recommendation Z.100. The latest version of the standard was published in 2016. Due to its suitability for real-time, stimulus-response systems, SDL has been used extensively within the telecommunications industry by both standards makers and manufacturers. SDL has also been used as a real-time design language outside the communications industry. Started as an informal drawing technique SDL has evolved to a full-blown visual and precise language, equally applicable to specification tasks and design activities. SDL is intuitive and helps in visualizing relationships, thanks to its simple conceptual basis (communicating extended finite state machines), and its graphical representation. The graphical abstractions that originally led to its popularity when used informally are
3. Error handling a. What is error handling testing? The purpose of error handling testing, a sort of software testing, is to determine whether the system is capable of handling potential future mistakes. Generally speaking, testers and developers work together to carry out this kind of testing. Testing for error handling places equal emphasis on identifying errors and addressing exceptions. Steps involved in the Error Handling testing: Test Environment Set Up Test Case Generation Test Case Execution Result and Analysis Re-test b. Objective of error handling testing to evaluate the system's error handling capacity. to inspect the highest soak point in the system. to ensure that faults can be handled correctly by the system going forward. to enable exception handling within the system. c. Avantages It aids in the development of software that can handle errors. It makes the software adaptable to any situation. It refines the software's method for handling exceptions. The software maintenance is beneficial. d. Disadvantages Due to the involvement of the testing and development teams, it is expensive. The testing activities require a lot of time. 4. The effectiveness of data structures and algorithms a. Why performance analysis? Usually, when solving a problem, we always tend to choose the "best" solution. But what is "good"? In mathematics, a "good" solution can be a short, concise, or criterion-based solution that uses easy-to-understand knowledge. As for algorithms in Informatics, it is based on the following two criteria: The algorithm is simple, easy to understand, easy to install.
Algorithm efficiency: Based on two factors that are the execution time of the algorithm (also known as algorithm complexity) and the amount of memory required to store the data. However, in the current context when computers have very large storage capacity, the factor that we need to pay more attention to is algorithmic complexity. b. What is Asymptopic Analysis? Asymptopic Notation? Define Asymptopic Asymptotic analysis of an algorithm refers to defining the mathematical boundation/framing of its run-time performance. Using asymptotic analysis, we can very well conclude the best case, average case, and worst case scenario of an algorithm. Asymptotic analysis is input bound i.e., if there's no input to the algorithm, it is concluded to work in a constant time. Other than the "input" all other factors are considered constant. Asymptotic analysis refers to computing the running time of any operation in mathematical units of computation. For example, the running time of one operation is computed as f(n) and may be for another operation it is computed as g(n2). This means the first operation running time will increase linearly with the increase in n and the running time of the second operation will increase exponentially when n increases. Similarly, the running time of both operations will be nearly the same if n is significantly small. Usually, the time required by an algorithm falls under three types − Best Case − Minimum time required for program execution. Average Case − Average time required for program execution. Worst Case − Maximum time required for program execution. Asymtopic Natione Following are the commonly used asymptotic notations to calculate the running time complexity of an algorithm. Big Oh Notation, Ο The notation Ο(n) is the formal way to express the upper bound of an algorithm's running time. It measures the worst case time complexity or the longest amount of time an algorithm can possibly take to complete.