review
10 nature genetics supplement • volume
21 • january 1999
Ambitious projects aimed at cloning, mapping and sequencing
the genomes of various organisms, including that of Homo sapi-
ens, have been launched worldwide. In all cases, the fruits of these
labours will provide a solid platform from which to attempt the
larger goal of understanding how genomes result in the organisms
they specify. The success of these international efforts is impres-
sive. So far, complete genomic sequences of 17 organisms, includ-
ing the eukaryote Saccharomyces cerevisiae, have been produced.
The mapping (both genetic and physical) and sequencing phases
of the Human Genome Project are ahead of schedule. Researchers
have catalogued more than 1.1 million expressed sequence tagged
sites (ESTs), corresponding with 52,907 unique human genes1
(www.ncbi.nlm.nih.gov/UniGene). However, the function, ex-
pression and regulation of more than 80% of them has yet to be
fathomed. The next phase of the human genome project will place
strong emphasis on assigning function to these genes.
The ability to identify genes at the nucleic acid level rather than
proceeding from a known protein to its chromosomal counter-
part has prompted efforts to likewise extract functional informa-
tion at the nucleic acid level. Two methods are currently in use.
The ‘sequence’ approach has led to the discovery of a wide variety
of sequence motifs encoding structural domains, such as DNA-
binding and nucleotide-binding domains2, thus providing clues
to gene function. Another route for exploring the function of a
gene is by determining its pattern of expression. The accumula-
tion of expression data has yet to reach the point at which it is
possible to speak of expression motifs, but it does suggest that
this is a plausible outcome of the approach3–5.
Various methods are available for detecting and quantitating
gene expression levels, including northern blots6, S1 nuclease pro-
tection7, differential display8, sequencing of cDNA libraries9,10
and serial analysis of gene expression11 (SAGE). Augmenting this
coterie are two array-based technologies—cDNA and oligonu-
cleotide arrays. These allow one to study expression levels in par-
allel3,12,13, thus providing static information about gene
expression (that is, in which tissue(s) the gene is expressed) and
dynamic information (that is, how the expression pattern of one
gene relates to those of others). The high degree of digital data
extraction and processing of these techniques supports a variety
of samples or experimental conditions.
Although both cDNA and oligonucleotide arrays are capable
of analysing patterns of gene expression, fundamental differences
exist between the methods. Here, we focus primarily on technical
aspects of cDNA microarrays, although some comparison with
the oligonucleotide array (see page 20 of this issue (ref. 14)) will
be made where appropriate.
Principle of method
As reviewed by Ed Southern on page 5 of this issue, hybridization
between nucleic acids (one of which is immobilized on a matrix)
provides a core capability of molecular biology15. This method
provides high sensitivity and specificity of detection as a conse-
quence of exquisite, mutual selectivity between complementary
strands of nucleic acids. Historically, most applications of this
method have employed a single, pure, labelled oligonucleotide or
polynucleotide species in the liquid phase and complex mixtures
of polynucleotides attached to a solid support. Transcript abun-
dance is assayed by immobilizing mRNA or total RNA (elec-
trophoretically separated or in bulk) on membranes and then
incubating w ith a radioactively labelled, gene-specific target. If
multiple RNA samples are immobilized on the same matrix, one
obtains information about the quantity of a particular message
present in each RNA pool.
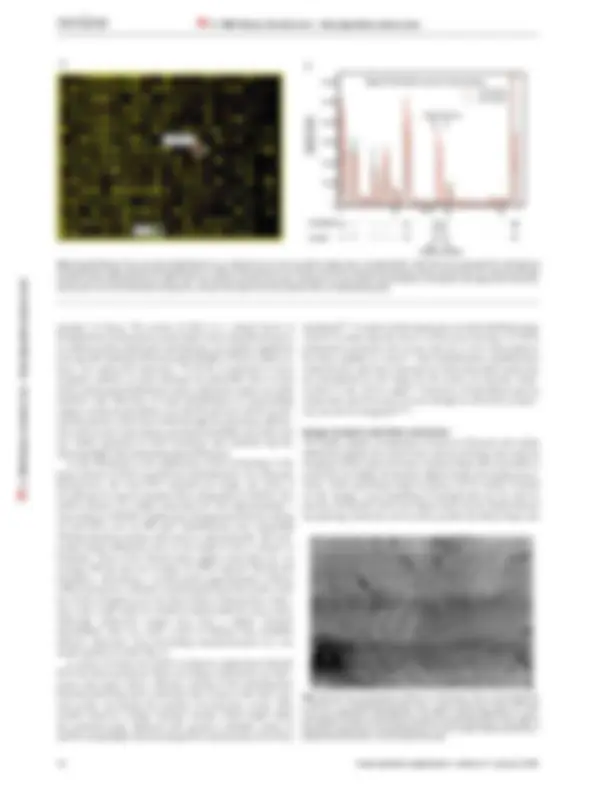
cDNA arrays alter this strategy in several ways (Fig. 1). In an
array experiment, many gene-specific polynucleotides derived
from the 3´ end of RNA transcripts are individually arrayed on a
single matrix. This matrix is then simultaneously probed w ith
fluorescently tagged cDNA representations of total RNA pools
from test and reference cells, allowing one to determine the rela-
tive amount of transcript present in the pool by the type of
fluorescent signal generated. Relative message abundance is
inherently based on a direct comparison between a ‘test’ cell state
and a ‘reference’ cell state; an internal control is thus provided for
each measurement (Fig. 2). The scheme is similar when using
radiolabelled probe, but it is not possible to carry out simultane-
ous hybridization of test and reference samples. In such cases,
serial or parallel hybridization is required, introducing the possi-
bility of higher variability in comparisons of expression level.
The adaptable nature of the fabrication and hybridization
methods allows the technique to be applied widely—the only
limitations are the availability of clones for the solid phase and
the quality of RNA samples derived from the cells (or tissues) to
be compared. This is illustrated by diverse applications that
include: investigating gene expression in the roots and leaves of
Arabidopsis thaliana3, human T cells exposed to phorbol ester12,
rheumatoid arthritis and inflammatory bowel disease16, tumori-
genic versus non-tumorigenic cell lines4, the diauxic shift from
anaerobic to aerobic metabolism in S. cerevisiae5,17 (yeast),
cDNA microarrays are capable of profiling gene expression patterns of tens of thousands of genes in a
single experiment. DNA targets, in the form of 3´ expressed sequence tags (ESTs), are arrayed onto glass
slides (or membranes) and probed with fluorescent- or radioactively-labelled cDNAs. Here, we review
technical aspects of cDNA microarrays, including the general principles, fabrication of the arrays,
target labelling, image analysis and data extraction, management and mining.
Expression profiling using cDNA microarrays
David J. Duggan, Michael Bittner, Yidong Chen, Paul Meltzer & Jeffrey M. Trent
Cancer Genetics Branch, National Human Genome Research Institute, National Institutes of Health,
© 1999 Nature America Inc. • http://genetics.nature.com
© 1999 Nature America Inc. • http://genetics.nature.com