


Operating Systems
Operating Systems
CMPSC 473
CMPSC 473
File System
File System
Implementation
Implementation
April 10, 2008 - Lecture
April 10, 2008 - Lecture
21
21
Instructor: Trent Jaeger
Instructor: Trent Jaeger


























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
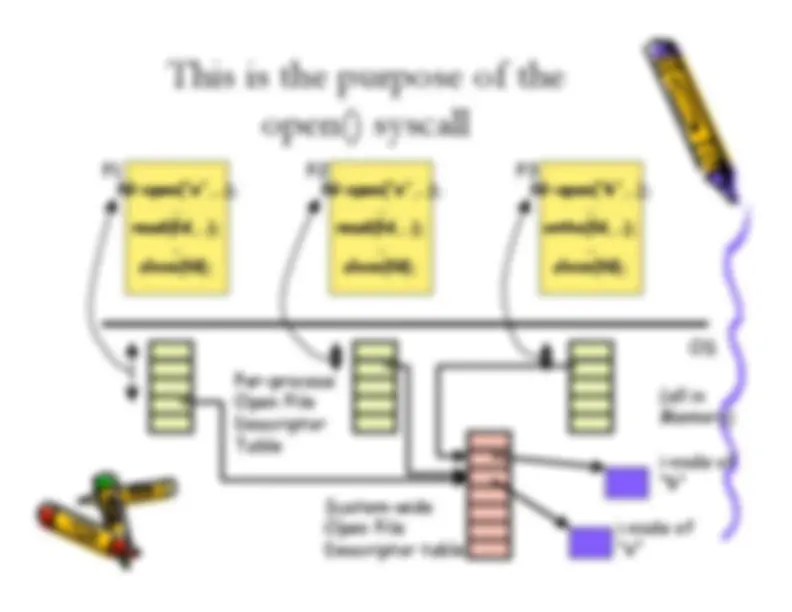
An in-depth look into the implementation of file systems, focusing on how to find and access file blocks in dos and unix systems. It also covers file system optimizations such as caching and free-space management. Examples and explanations of various file system concepts.
Typology: Study notes
1 / 34

This page cannot be seen from the preview
Don't miss anything!
Accessing a file block in DOS \a\b\c
Accessing a file block in UNIX /a/b/c
12
30
30
12
18