



Hash Tables
15-121 Fall 2020
Margaret Reid-Miller





















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The concept of hash tables and maps, which are tables of (key,value) pairs indexed by unique keys. It covers the advantages and disadvantages of using TreeSet and TreeMap, which are classes that implement a sorted Set and Map respectively. The document also explains the use of a balanced binary search tree called a red-black tree, and the concept of hash functions and collisions. It provides examples of hash functions for integers and strings. from a Fall 2020 course (15121) taught by Margaret Reid-Miller.
Typology: Lecture notes
1 / 30

This page cannot be seen from the preview
Don't miss anything!
(sometimes called a bag) A set is “bag” of objects
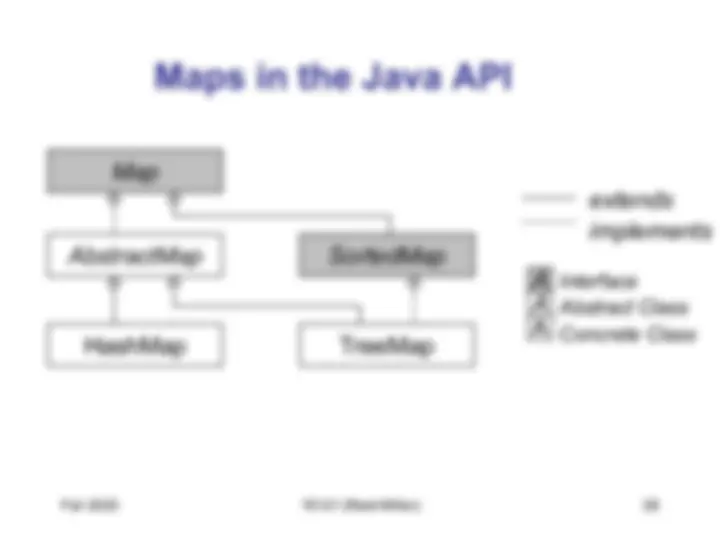
(also called dictionary or associative array)
Name Section Tom A Fred B Dave A Sally C
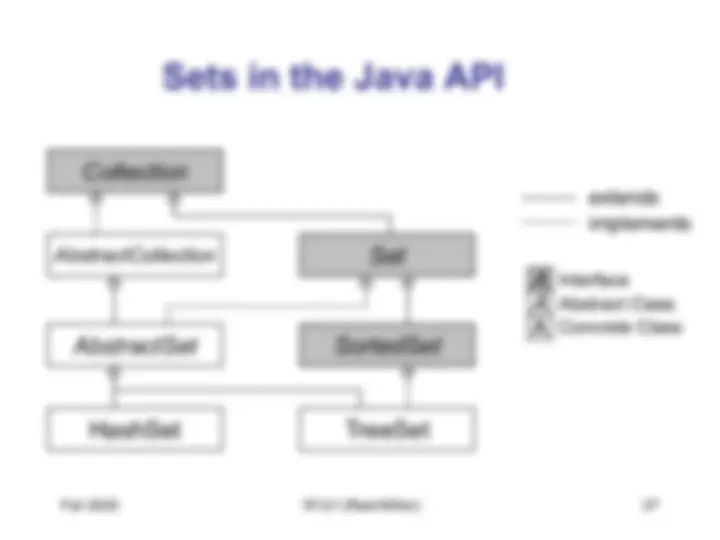
Both TreeSet & TreeMap use a balanced binary search tree called a “red-black tree". Red-Black balanced binary search trees:
Worst case O(log n) time! Great! We’re done! The course is over! Yay! Unless…
Use the student id as the index into a really big array: contains: O(1), add: O(1), remove: O(1). Yay!!! Problem: 0 1 … 151212018 à id: 151- 21 - 2018 name: Dave … 999999999 Memory hog: The range of student id values is independent on the number of students (size of the set).
Key Idea: Use the key to compute an index into a moderate size array.
birthday:
1. Open Addressing (topic for 15 - 451) 2. Separate chaining – Each index of array contains all the elements that hash to that index (called a bucket ) What data structure should we use to maintain a bucket?
Separate Chaining using a linked list 10 … Dave … Tom … Sue 65 null null null null null
What is the worst-case runtime for contains, add, remove? O(n) – all the keys hash to the same index What is the best-case runtime? O(1) – only a few keys map to any one index What is the expected runtime? O(1) – assuming the hash function is good, and the hash table is not too full
Load Factor: (number of elements) / (length of array) What is the expected size of a bucket? The load factor What is a good load factor? A small constant so that the linked list stay short, even the longest ones. Java uses a default value of 0. Can the load factor be larger than 1? Yes