Download Hashing - Programming Languages and Techniques II - Lecture Slides and more Slides Programming Languages in PDF only on Docsity!
Hashing
docsity.com
Searching
Consider the problem of searching an array for a given
value
If the array is not sorted, the search requires O(n) time
If the value isn’t there, we need to search all n elements If the value is there, we search n/2 elements on average
If the array is sorted, we can do a binary search
A binary search requires O(log n) time About equally fast whether the element is found or not
It doesn’t seem like we could do much better
How about an O(1), that is, constant time search? We can do it if the array is organized in a particular way
docsity.com
Example (ideal) hash function
Suppose our hash function
gave us the following values:
hashCode("apple") = 5 hashCode("watermelon") = 3 hashCode("grapes") = 8 hashCode("cantaloupe") = 7 hashCode("kiwi") = 0 hashCode("strawberry") = 9 hashCode("mango") = 6 hashCode("banana") = 2
kiwi
banana
watermelon
apple
mango
cantaloupe
grapes
strawberry
docsity.com
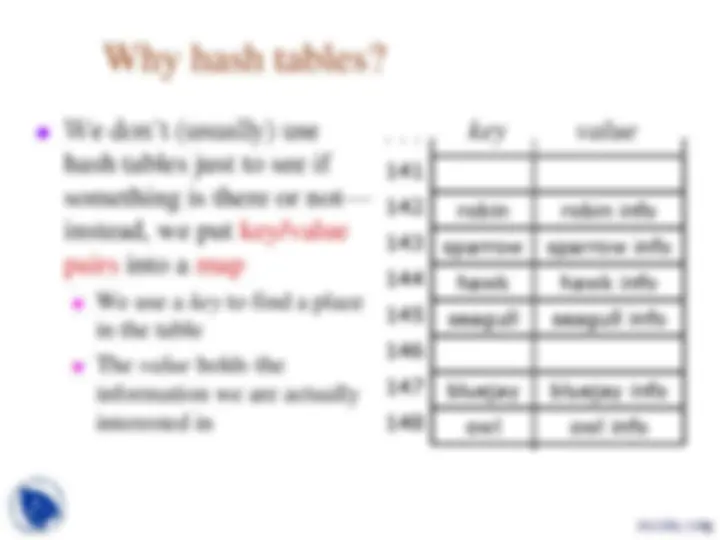
Why hash tables?
We don’t (usually) use
hash tables just to see if
something is there or not—
instead, we put key / value
pairs into a map
We use a key to find a place
in the table
The value holds the
information we are actually
interested in
robin sparrow hawk seagull
bluejay owl
robin info sparrow info hawk info seagull info
bluejay info owl info
key value
docsity.com
Example imperfect hash function
Suppose our hash function gave
us the following values:
hash("apple") = 5 hash("watermelon") = 3 hash("grapes") = 8 hash("cantaloupe") = 7 hash("kiwi") = 0 hash("strawberry") = 9 hash("mango") = 6 hash("banana") = 2 hash("honeydew") = 6
kiwi
banana
watermelon
apple
mango
cantaloupe
grapes
strawberry
• Now what?
docsity.com
Collisions
When two values hash to the same array location,
this is called a collision
Collisions are normally treated as “first come, first
served”—the first value that hashes to the location
gets it
We have to find something to do with the second and
subsequent values that hash to this same location
docsity.com
Insertion, I
Suppose you want to add
seagull to this hash table
Also suppose:
hashCode(seagull) = 143
table[143] is not empty
table[143] != seagull
table[144] is not empty
table[144] != seagull
table[145] is empty
Therefore, put seagull at
location 145
robin
sparrow
hawk
bluejay
owl
seagull
docsity.com
Searching, I
Suppose you want to look up
seagull in this hash table
Also suppose:
hashCode(seagull) = 143
table[143] is not empty
table[143] != seagull
table[144] is not empty
table[144] != seagull
table[145] is not empty
table[145] == seagull!
We found seagull at location
robin
sparrow
hawk
bluejay
owl
seagull
docsity.com
Insertion, II
Suppose you want to add
hawk to this hash table
Also suppose
hashCode(hawk) = 143
table[143] is not empty
table[143] != hawk
table[144] is not empty
table[144] == hawk
hawk is already in the table,
so do nothing
robin
sparrow
hawk
seagull
bluejay
owl
docsity.com
Insertion, III
Suppose:
You want to add cardinal to
this hash table
hashCode(cardinal) = 147
The last location is 148
147 and 148 are occupied
Solution:
Treat the table as circular; after
148 comes 0
Hence, cardinal goes in
location 0 (or 1, or 2, or ...)
robin
sparrow
hawk
seagull
bluejay
owl
docsity.com
Efficiency
Hash tables are actually surprisingly efficient
Until the table is about 70% full, the number of
probes (places looked at in the table) is typically
only 2 or 3
Sophisticated mathematical analysis is required to
prove that the expected cost of inserting into a hash
table, or looking something up in the hash table, is
O(1)
Even if the table is nearly full (leading to long
searches), efficiency is usually still quite high
docsity.com
Solution #2: Rehashing
In the event of a collision, another approach is to rehash: compute
another hash function
Since we may need to rehash many times, we need an easily computable sequence of functions
Simple example: in the case of hashing Strings, we might take the
previous hash code and add the length of the String to it
Probably better if the length of the string was not a component in computing the original hash function
Possibly better yet: add the length of the String plus the number
of probes made so far
Problem: are we sure we will look at every location in the array?
Rehashing is a fairly uncommon approach, and we won’t pursue
it any further here
docsity.com
The hashCode function
public int hashCode() is defined in Object
Like equals, the default implementation of
hashCode just uses the address of the object—
probably not what you want for your own objects
You can override hashCode for your own objects
As you might expect, String overrides hashCode
with a version appropriate for strings
Note that the supplied hashCode method does not
know the size of your array —you have to adjust
the returned int value yourself
docsity.com
Writing your own hashCode method
A hashCode method must:
Return a value that is (or can be converted to) a legal
array index
Always return the same value for the same input
It can’t use random numbers, or the time of day
Return the same value for equal inputs
Must be consistent with your equals method
It does not need to return different values for
different inputs
A good hashCode method should:
Be efficient to compute
Give a uniform distribution of array indices
Not assign similar numbers to similar input values
docsity.com