Download Hierarchical Clustering Algorithms-Recognizing Patterns and Classifying Them-Lecture Slides and more Slides Pattern Classification and Recognition in PDF only on Docsity!
1
HIERARCHICAL CLUSTERING ALGORITHMS
They produce a hierarchy of (
hard
) clusterings
instead of a single clustering.
Applications in:
Social sciences
Biological taxonomy
Modern biology
Medicine
Archaeology
Computer science and engineering
2
Let
X=
{x
,…,x 1
},N
x^ i
[x
,…,xi^1
]il
T.
Recall that:
In hard clustering each vector belongs exclusively to a singlecluster.
An
m
-(hard) clustering of
X
,^
, is a partition of
X
into
m
sets
(clusters)
C
,…,C 1
m^
, so that:
{C
, jj
,…m
Definition: A clustering
1
containing
k
clusters is said to be
nested in the clustering
2
containing
r
k)
clusters, if each
cluster in
is a subset of a cluster in 1
We write
2
m
i
C
i^
,..., 2 , 1
,^
X
C U
i m i
^1
m j i j i C C
i^
,..., (^2) , 1
, ,
,^
4
AGGLOMERATIVE ALGORITHMS
Let
g
(C
,Ci
)j
a proximity function between two clusters
of
X.
Generalized Agglomerative Scheme (GAS)
Initialization
x^1
{x
}}N
•^
t=
Repeat
•^
t=
t+
C
,Ci
)^ j
in
t-
such that
C
=q
C
i
C
and producej
=(t
t-
C
,Ci
})j
{C
}q
Until all vectors lie in a single cluster.
function
sim a is g if
C C g
function
disim a is g if
C C g C C g
s r
sr
s r
sr
j i^
.
), , (
max
.
), , (
min
) , (
, ,
5
Remarks:
•^
If two vectors come together into a single cluster at level
t
of the hierarchy, they will remain in the same cluster for allsubsequent clusterings. As a consequence, there is no wayto recover a “poor” clustering that may have occurred in anearlier level of hierarchy.
-^
Number of operations:
O
(N
7
Threshold dendrogram (or dendrorgram): It is an effective way ofrepresenting the sequence of clusterings which are produced by anagglomerative algorithm.In the previous example, if
is employed as the distance
measure between two sets and the Euclidean one as the distancemeasure between two vectors, the following series of clusteringsare produced:
) , ( min
j i
ss^
C C
d
x^1
x^2
x^3
x^4
x^5
{{
},{
},{
},{
},{
}}
x^
x^
x^
x^
x
1
2
3
4
5
{{
,^
},{
},{
},{
}}
x x
x^
x^
x
1
2
3
4
5
{{
,^
},{
},{
,^
}}
x x
x^
x x
1
2
3
4
5
{{
,^
},{
,^
,^
}}
x x
x x x
1
2
3
4
5
{{
,^
,^
,^
,^
}}
x x x x x^1
2
3
4
5
8
Proximity (dissimilarity or dissimilarity) dendrogram:
A dendrogram that
takes into account the level of proximity (dissimilarity or similarity) wheretwo clusters are merged for the first time.
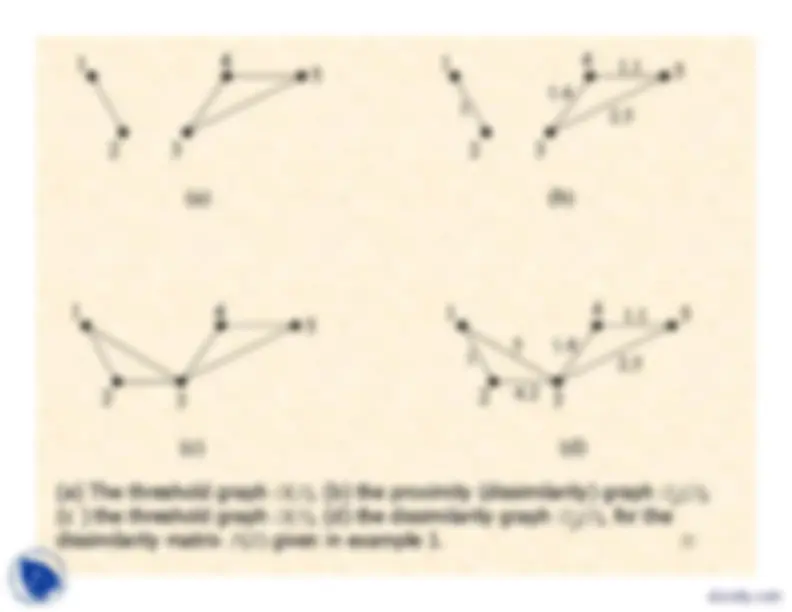
Example 2: In terms of the previous example, the proximity dendrogramsthat correspond to
P
X
)^
and
P
(X
)^
are
Remark: One can readily observe the level in which a cluster is formedand the level in which it is absorbed in a larger cluster (indication of thenatural clustering).
(^1) 0.90.80.70.60.50.40.30.20.1^0 Similarity scale
x^1
x^2
x^3
x^4
x^5
(^012345678910) Dissimilarity scale
x^1
x^2
x^3
x^4
x^5
(a)
(b)
10
-^
A number of distance functions comply with the following update equation
d(
C
,Cq
)=s
ai
d(
C
,Ci
)+s
aj
(d
(C
,Cj
)+s
bd
(C
,Ci
)+j
c|d
(C
,Ci
)-s
d(
C
,Cj
)|s
Algorithms that follow the above equation are:
Single link (SL) algorithm (
a^ i
=1/
, aj
=1/
, b
=
, c
=-1/
). In this case
d(
C
,Cq
)=s
min
{d
(C
,Ci
), ds
(C
,Cj
)}s
Complete link (CL) algorithm (
a^ i
=1/
, a
=1/2j
, b
=
, c
=1/
). In this case
d(
C
,Cq
)=s
max
{d
(C
,Ci
), ds
(C
,Cj
)}s
Remarks:•
Single link forms clusters at low dissimilarities while complete link formsclusters at high dissimilarities.
-^
Single link tends to form elongated clusters (
chaining effect ) while complete
link tends to form compact clusters.
-^
The rest algorithms are compromises between these two extremes.
11
Example:
(a)
The data set
X
.
(b) The single linkalgorithm dissimilaritydendrogram.(c) The complete linkalgorithm dissimilaritydendrogram
13
Weighted Pair Group Method Centroid (WPGMC) (
a^ i
, a
=1/2j
, b
c=
). In this case
d^ qs
d^ is
d
)/2js
–d
/4ij
For WPGMC there are cases where
d
qs
^
max
{d
, dis
}js
(crossover)
Ward or minimum variance algorithm. Here the distance
d´
ij^
between
C
i
and
C
is defined asj
d´
=ij^
(n
ni^
/(j
n^ i
+n
)) ||j
m
-mi
||j 2
d´
qs
can also be written as
d´
qs
n^ i
n
)j^
d´
is^
n^ i
n
)d´j
js^
–^
n^ s
d´
ij^
n^ i
nj
n^ s
Remark: Ward’s algorithm forms
t+
by merging the two clusters that
lead to the smallest possible increase of the total variance, i.e.,
t N r^
C x
r
t
r
m
x
E
1
docsity.com
14
Example 3: Consider the following dissimilarity matrix (Euclidean distance)All the algorithms produce the above sequence of clusterings at differentproximity levels:
0 (^5). 1 25 36
37
(^5). 1 0
16 25
26
25
16 0
3 2
36
25 3
0
1
37
26 2
1 0
P^0 SL
CL
WPGMA
UPGMA
WPGMC
UPGMC
Ward
0
1
2
3
4
x^1
x^2
x^3
x^4
x^5
x^1
, x
,^ {
x^3
x^4
x^5
x^1
, x
,^ {
x^3
x^4
, x
x^1
, x
, x 2
,^ {
x^4
, x
x^1
, x
, x 2
, x 3
, x 4
16
Monotonicity condition:If clusters
C
andi
C
are selected to be merged in clusterj
C
, at theq
t
th
level of the hierarchy, the condition
d(
C
,Cq
)k
d
(C
,Ci
)j
must hold for all
C
,k k
i, j , q
In other words, the monotonicity condition implies that a cluster is formedat higher dissimilarity level than any of its components.
Remarks:
•^
Monotonicity is a property that is exclusively related to the clusteringalgorithm and not to the (initial) proximity matrix.
-^
An algorithm that does not satisfy the monotonicity condition, doesnot necessarily produce dendrograms with crossovers.
-^
Single link, complete link, UPGMA, WPGMA and the Ward’s algorithmsatisfy the monotonicity condition, while UPGMC and WPGMC do notsatisfy it.
17
Complexity issues:
- GAS requires, in general,
O
(N
operations.
- More efficient implementations require
O
(N
2 logN
)^
computational time.
- For a class of widely used algorithms, implementations that require
O
(N
computational time and
O
(N
or
O
(N
)^
storage have also been
proposed.
- Parallel implementations on SIMD machines have also been
considered.
19
•^
A complete subgraph
G´
V´,E
)^
is a subgraph where for any pair of
vertices in
V’
there exists an edge in
E´´
connecting them.
•^
A maximally connected subgraph of
G
is a connected subgraph
G´
of
G
that contains as many vertices of
G
as possible.
•^
A maximally complete subgraph of
G
is a complete subgraph
G´
of
G
that contains as many vertices of
G
as possible.
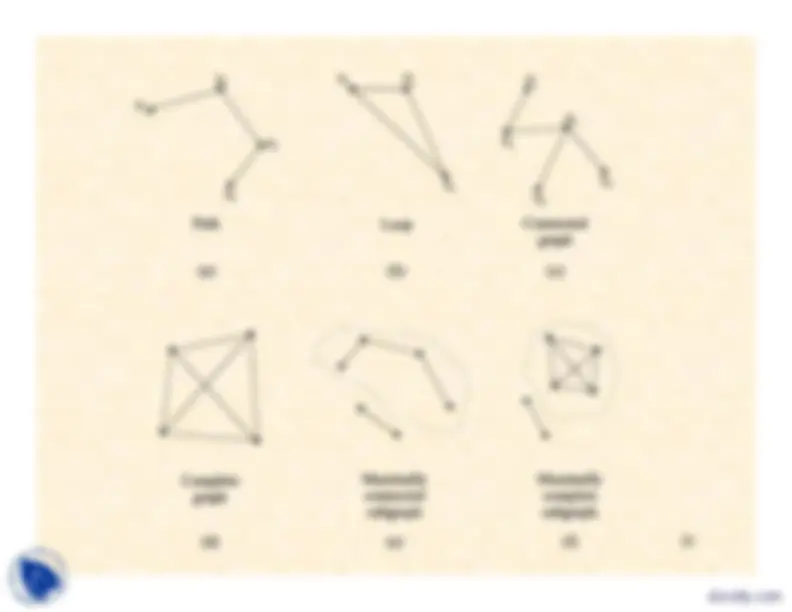
Examples for the above, are shown in the following figure.
20