


AI's Secret Language
Why LLM’S doesn't actually read your words.
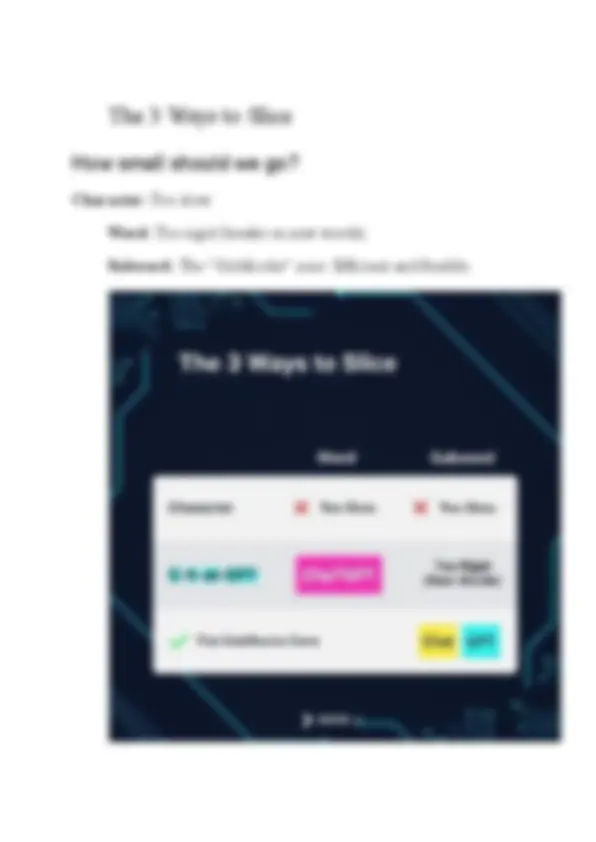
Understanding the magic of Tokenization.

Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Explore the concept of tokenization in artificial intelligence, focusing on how large language models (llms) process text. This document breaks down the methods of tokenization, including character, word, and subword approaches, with a detailed look at byte pair encoding (bpe). It explains how text is converted into numerical ids for ai processing, the implications of token usage, and how understanding tokenization can improve prompting and cost management. This guide is designed to demystify the inner workings of ai language processing for students and enthusiasts alike, offering insights into efficient and effective ai interaction.
Typology: Summaries
1 / 7

This page cannot be seen from the preview
Don't miss anything!
Why LLM’S doesn't actually read your words.
Understanding the magic of Tokenization.
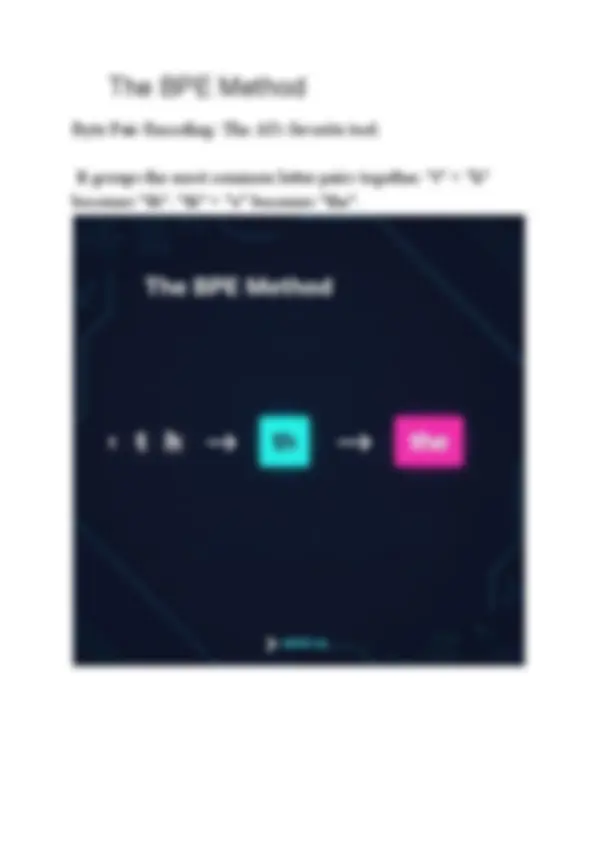
Byte Pair Encoding: The AI's favorite tool.
It groups the most common letter pairs together. "t" + "h"
becomes "th". "th" + "e" becomes "the".
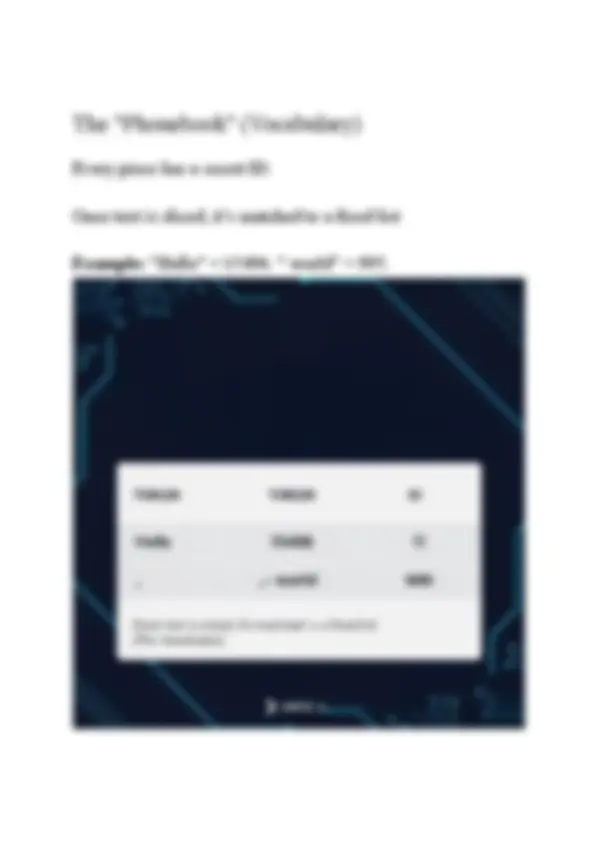
The "Phonebook" (Vocabulary)
Every piece has a secret ID.
Once text is sliced, it’s matched to a fixed list
Example: "Hello" = 15496. " world" = 995.
Understanding tokenization helps you prompt better and manage costs.