How2Sign: A Large-scale Multimodal Dataset
for Continuous American Sign Language
Supplementary material
1. Sign Language
In this section we discuss in more detail some important
non-manual features (that are not conveyed through other
linguistic parameters e.g. palm orientation, handshape, etc.)
present in sign languages. It is important to remember
that American Sign Language, for example, requires more
than just complex hand movements to convey a message.
Without the use of proper facial expressions and other non-
manual features as the ones described below, a message
could be greatly misunderstood [32].
Head movement. The movement of the head supports the
semantics of sign language. Questions, affirmations, de-
nials, and conditional clauses are communicated with the
help of the signer’s head movement.
Facial grammar. Facial grammar does not only reflect a
person’s affect and emotions, but also constitutes to large
part of the grammar in sign languages. For example, a
change of head pose combined with the lifting of the eye
brows corresponds to a subjunctive.
Mouth morphemes (mouthing). Mouth movement or
mouthing is used to convey an adjective, adverb, or an-
other descriptive meaning in association with an ASL word.
Some ASL signs have a permanent mouth morpheme as part
of their production. For example, the ASL word NOT-YET
requires a mouth morpheme (TH) whereas LATE has no
mouth morpheme. These two are the same sign but with a
different non-manual signal. These mouth morphemes are
used in some contexts with some ASL signs, not all of them.
2. How2Sign dataset
Here we discuss some additional metadata that are im-
portant for a better understanding of our data as well as the
biases and generalization of the systems trained using the
How2Sign dataset. We also describe information that might
be helpful for future similar data collection.
Gloss. We collected gloss annotations for the ASL videos
present in the How2Sign dataset using ELAN. Figure 2
shows samples of the gloss annotations present in our
dataset. Here we describe some conventional and few mod-
ified symbols and explanations that will be found in our
dataset. A complete list is available on the dataset website.
•Capital letters. English glosses are written using capital
letters. They represent an ASL word or sign. It is impor-
tant to remember that gloss is not a translation. It is only
an approximate representation of the ASL sign itself, not
necessarily a meaning.
• A hyphen is used to represent a single sign when more
than one English word is used in gloss (e.g. STARE-AT).
• The plus sign (+) is used in ASL compound words (e.g.
MOTHER+FATHER – used to transcribe parents). It is
also used when someone combines two signs in one (e.g.
YOU THERE will be glossed as YOU+THERE).
• The plus sign (++) at the end of a gloss indicates a num-
ber of repetitions of an ASL sign (e.g. AGAIN++ – the
word “again” was signed two more times meaning “again
and again”).
•FS: represents a fingerspelled word (e.g. FS:AMELIA).
•IX is a shortcut for “index”, which means to point to a
certain location, object, or person.
•LOC is a shortcut for “locative”, a part of the grammatical
structure in ASL.
•CL: is a shortcut for “classifier”. Classifiers are signs
that use handshapes that are associated with specific cat-
egories (classes) of things, size, shape, or usage. They
can help to clarify the message, highlight specific de-
tails, and provide an efficient way of conveying infor-
mation1. In our annotations, classifiers will appear as:
“CL:classifier(information)”. For example, if the signer
signs “TODAY BIKE” and uses a classifier to show the
bike going up the hill, this would be glossed as: “TODAY
BIKE CL:3 (going uphill)”).
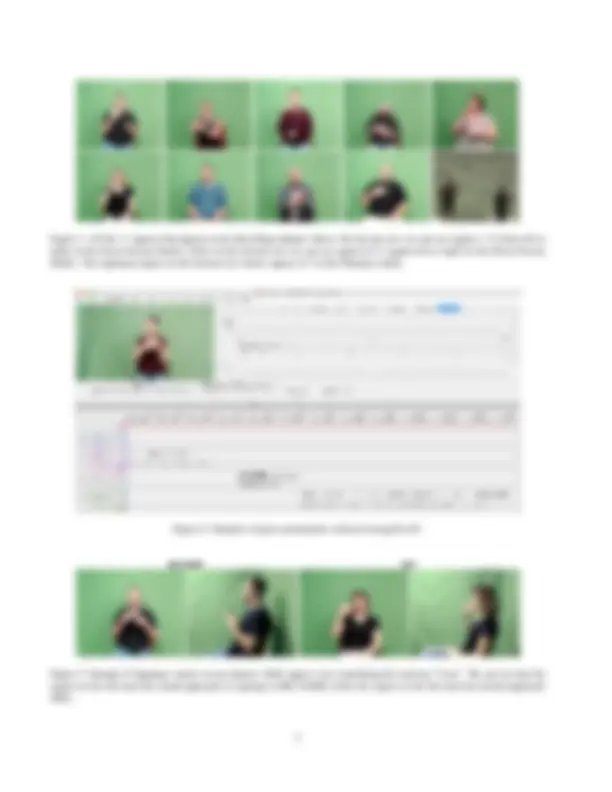
Signers. Figure 1show all the 11 signers that participated
in the recordings of the How2Sign dataset. From the 11
signers, four of them (signers 1, 2, 3 and 10 ) participated
in both the Green Screen studio and the Panoptic studio
recordings. Signers 6 and 7 participated only in the Panop-
tic studio recordings, while signers 4, 5, 8, 9 and 11 partic-
1More info about handshapes and classifiers can be found at:
https : / / www . lifeprint . com / asl101 / pages - signs /
classifiers/classifiers-main.htm
1