Download Huffman Codes - Information Theory - Lecture Slides and more Slides Information Technology in PDF only on Docsity!
EE514a – Information Theory I
Fall Quarter 2013
Prof. Jeff Bilmes
University of Washington, Seattle Department of Electrical Engineering Fall Quarter, 2013 http://j.ee.washington.edu/~bilmes/classes/ee514a_fall_2013/
Lecture 11 - Oct 29th, 2013
Class Road Map - IT-I
L1 (9/26): Overview, Communications, Information, Entropy L2 (10/1): Props. Entropy, Mutual Information, L3 (10/3): KL-Divergence, Convex, Jensen, and properties. L4 (10/8): Data Proc. Ineq., thermodynamics, Stats, Fano, M. of Conv L5 (10/10): AEP, Compression L6 (10/15): Compression, Method of Types, L7 (10/17): Types, U. Coding., Stoc. Processes, Entropy rates, L8 (10/22): Entropy rates, HMMs, Coding, Kraft, L9 (10/24): Kraft, Shannon Codes,Huffman, Shannon/Fano/Elias
L10 (10/28): Huffman, Shannon/Fano/Elias L11 (10/29): Shannon Games, Arith. Coding L12 (10/31): Midterm, in class. L L L L L L L L
Finals Week: December 12th–16th.
Homework
Homework 4 out on our web page (http://j.ee.washington. edu/~bilmes/classes/ee514a_fall_2013/), due Tuesday, Oct 29th, at 11:45pm.
Announcements
Office hours, every week, Tuedsays 4:30-5:30pm. Can also reach me at that time via a canvas conference. Midterm on Thursday, 10/31 in class. Covers everything up to and including homework 4 (today’s cumulative reading). We’ll have a review on 10/29. Next lecture will conflict with Stephen Boyd’s lecture (which is at 3:30-4:20pm in room EEB-105, see http://www.ee.washington. edu/news/2013/boyd_lytle_lecture.html). In order to see the lecture, 1/2 of Tuesday’s lecture will be youtube only (which is right now), and we’ll meet in person only from 2:30-3:20. On Tuesday, Oct 29th, we will meet from 2:30-2:20 in EEB-026, and then talk to the Boyd talk. The topic will be “games” and then midterm review.
Huffman Codes
Can we easily compute p(x1:n)? If |A| is the alphabet size, we need a table of size |A|n^ to store these probabilities. Moreover, it is hard to estimate p(x1:n) accurately. Given an amount of “training data” (to borrow a phrase from machine learning), it is hard to estimate this distribution. Many of the possible strings in any finite sample size will not occur (sparsity). Example: how hard is it to find a short grammatically valid English prhase never before written using a web search engine? “dogs ate banks on the river” is not found as of Mon, Oct 28, 2013. Smoothing models are required. Similar to the language model problem in natural language processing.
Huffman Codes
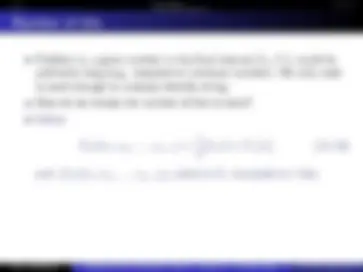
Huffman has the property that
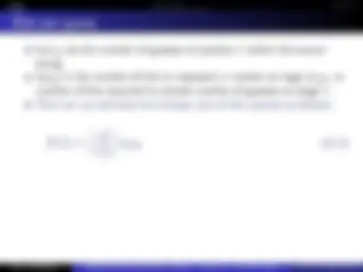
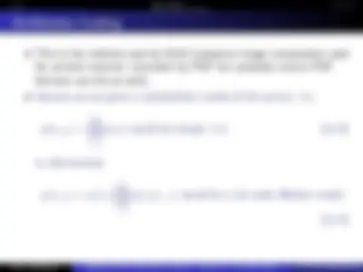
H(X) ≤ L(Huffman) ≤ H(X) + 1 (11.16)
Bigger block sizes help, but we get
H(X1:n) ≤ L(Block Huffman) ≤ H(X1:n) + 1 (11.17)
for the block. If H(X1:n) is small (e.g., English text) then this extra bit can be significant. If block gets too long, we have the estimation problem again (hard to compute p(x1:n), also the fact that it introduces latencies (we need to encode and then wait for the end of a block before we can send any bits).
The Probabilities They Are A-Changin’
Real sequential processes are not stationary. It might be a reasonable approximation to assume that they are “locally stationary”, meaning that the statistics of the process are governed by a distribution p(x) within a given fixed-width time window.
The Probabilities They Are A-Changin’
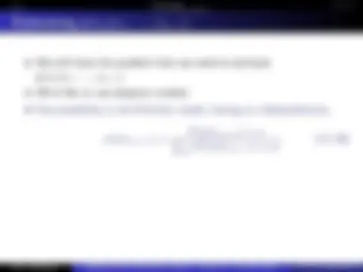
Real sequential processes are not stationary. It might be a reasonable approximation to assume that they are “locally stationary”, meaning that the statistics of the process are governed by a distribution p(x) within a given fixed-width time window. Huffman assumes one fixed p(x). If this changes, say to p′(x), the code will be less optimal by D(p′(x)||p(x)) bits per symbol, where p′(x) is the “correct” distribution.
The Probabilities They Are A-Changin’
Real sequential processes are not stationary. It might be a reasonable approximation to assume that they are “locally stationary”, meaning that the statistics of the process are governed by a distribution p(x) within a given fixed-width time window. Huffman assumes one fixed p(x). If this changes, say to p′(x), the code will be less optimal by D(p′(x)||p(x)) bits per symbol, where p′(x) is the “correct” distribution. Instead we could: (^1) Recompute Huffman distribution and code each period. This is inefficient, however, as we’ll need to re-transmit the codebook each time!
The Probabilities They Are A-Changin’
Real sequential processes are not stationary. It might be a reasonable approximation to assume that they are “locally stationary”, meaning that the statistics of the process are governed by a distribution p(x) within a given fixed-width time window. Huffman assumes one fixed p(x). If this changes, say to p′(x), the code will be less optimal by D(p′(x)||p(x)) bits per symbol, where p′(x) is the “correct” distribution. Instead we could: (^1) Recompute Huffman distribution and code each period. This is inefficient, however, as we’ll need to re-transmit the codebook each time! (^2) We could do some sort of adaptive Huffman scheme.
Games Arith. Coding Midterm
O Redundancy, Redundancy, wherefore art thou
Redundancy
Consider English text. Redundancy abounds.
Games Arith. Coding Midterm
O Redundancy, Redundancy, wherefore art thou
Redundancy
Consider English text. Redundancy abounds. Redundancy exists at the sentence level, the word level, and the character level.
Games Arith. Coding Midterm
O Redundancy, Redundancy, wherefore art thou
Redundancy
Consider English text. Redundancy abounds. Redundancy exists at the sentence level, the word level, and the character level. Complete the following sentence fragment: “with more than 300 dead, most of the victims choked to death.”
Games Arith. Coding Midterm
O Redundancy, Redundancy, wherefore art thou
Redundancy
Consider English text. Redundancy abounds. Redundancy exists at the sentence level, the word level, and the character level. Complete the following sentence fragment: “with more than 300 dead, most of the victims choked to death.” did you really need to see that last word, we could just predict it, or alternatively use few bits to code it.