Download I. Genes & Proteins and more Summaries Genetics in PDF only on Docsity!
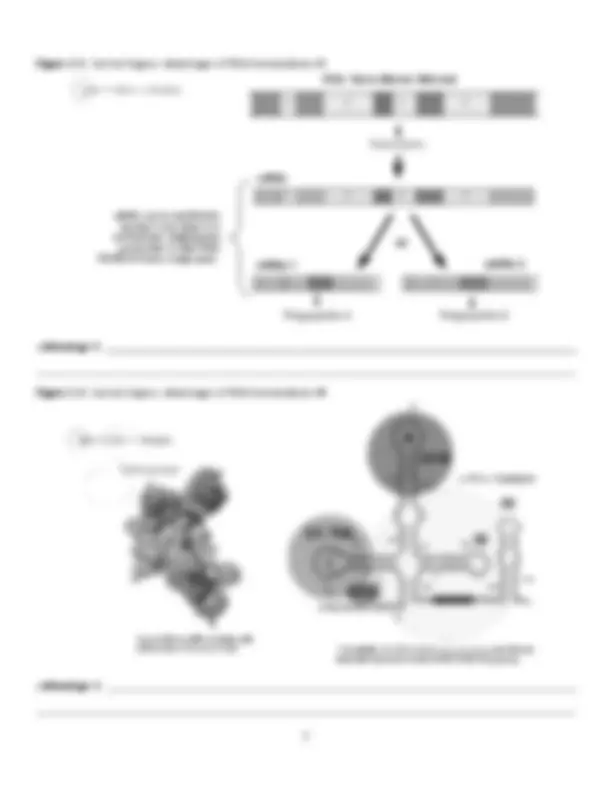
I. Genes & Proteins ● Archibald Garrod (1909) was the first to contend that genes coded for enzymes that, in turn, controlled phenotypic traits. This so-called “One-Gene-One-Enzyme Hypothesis” was experimentally verified in the 1940’s by the work of Beadle & Tatum. ● To test the one-gene, one enzyme hypothesis, Beadle & Tatum studied the metabolic pathway in which the fungus, Neurospora , synthesized the amino acid arginine. The pathway was known to involve 3 enzymes (A, B, & C). If Garrod’s hypothesis was correct, a mutation in one of the genes controlling this pathway would affect a SINGLE one of these enzymes (A, B, OR C). ● Beadle & Tatum started by exposing wild type Neurospora to X-rays in order to induce mutations in the arginine pathway. In doing so, they produced 3 mutant classes , each possessing a SINGLE mutation in the arginine pathway: Figure 1: Beadle & Tatum’s Experiment: Creating Mutant Classes ● After establishing these mutant classes, Beadle & Tatum then investigated whether the single mutation within in class affected a single or multiple enzyme in the arginine pathway. To do so, Beadle & Tatum distributed each mutant to a number of vials, each with minimal medium + a single intermediate in the synthesis of arginine ...
Figure 1.1: Beadle & Tatum’s Experiment: Class I Mutants Figure 1.2: Beadle & Tatum’s Experiment: Class II Mutants
Figure 2.1: Central Dogma: Advantages of RNA Intermediates # ● Advantage 1: Figure 2. 2 : Central Dogma: Advantages of RNA Intermediates # 2 ● Advantage 2 :
Figure 2. 3 : Central Dogma: Advantages of RNA Intermediates # 3 ● Advantage 3 : Figure 2.4: Central Dogma: Advantages of RNA Intermediates # 4 ● Advantage 4 :
Figure 4.1: Eukaryotic Gene Structure ●The Promoter , located at the start end of every eukaryotic gene, contains the base sequence “TATAAT”, commonly referred to as a TATA Box. This region functions to “advertise” the site to which the proteins & enzymes responsible for transcription (i.e. transcription factors) initially bind to the coding strand (3’→ 5’); this strand serves as the template for the production of mRNA. Figure 4.2: Eukaryotic Gene Structure: The Transcription Unit ●The region of a gene containing the stretch of DNA that codes for a polypeptide is called a Transcriptional Unit. Within this region, bases are organized into coding regions that are randomly interrupted by noncoding regions:
● Exons represent regions w/in the transcription unit of a gene that contains the information for the assembly of a polypeptide (protein) product. Within exons, nucleotide bases are organized into Codons , a 3 - base sequence that codes for an individual amino acid component of the polypeptide product. ● Introns are noncoding regions that randomly interrupt the exons within a gene’s transcription unit. Introns allow for mRNA to be edited in a variety of different ways following transcription, leading to the formation of multiple polypeptide products from the SAME gene sequence. ●At the end of the transcriptional unit is a Terminator sequence that signals the end of the gene sequence. Upon reaching the terminator, transcription factors will detach from the coding strand to end transcription. III. Gene Expression: Transcription ●The first step in the expression of the information encoded by a gene into a protein product is Transcription. In this process, the base sequence of a gene is used to create a complementary molecule of mRNA … Figure 5: Transcription: General Overview ●Once formed, the mRNA can leave the nucleus (“mobile gene”) & interact with a ribosome in the cytosol, whereupon the instructions it carries will be translated to form a polypeptide → protein. ●The major enzyme responsible for creating mRNA from a gene is called RNA Polymerase II. Genes that are transcribed by RNA polymerase II to give rise to mRNA are referred top as Structural Genes (contain polypeptide “recipes”).
Figure 5. 2 : Transcription: Elongation Phase ● During the Elongation process, RNA polymerase II adds RNA nucleotides complimentary to the DNA coding strand, elongating the mRNA in its 3’ direction (free - OH group). As RNA polymerase II “reads” the base sequence of the DNA’s coding strand, it pairs a URACIL, not a thymine, with an adenine... ● As the mRNA elongates, its 5’ end falls away from the DNA coding strand, allowing the separated DNA strands behind it to rewind into a helix (thus only one section of the gene is ever exposed at any one time). Figure 5. 3 : Transcription: Termination Phase
● At the 5’ end of the mRNA transcript is a 5’ Untranslated Region (UTR). This region represents a portion of the DNA’s promotor that was transcribed into mRNA. This region plays important roles in the modification of the mRNA before it leaves the nucleus. Likewise, a 3’ Untranslated Region exists at the 3’ end of the mRNA, representing a portion of the DNA’s terminator that was transcribed into mRNA. ● Between the UTR’s exists the mRNA’s Reading Frame, which contains the actual recipe for a polypeptide. Within this region, codons specify a single amino acid for the polypeptide to be made. Within the first exon of the reading frame
exists a Start Codon (AUG) , which signals the beginning of the coding sequence. Within the last exon of the reading
frame exists a Stop Codon (UAA, UAG, UGA) , which signals the end of the coding sequence.
Figure 5.4: mRNA Reading Frame: Codons ● The mRNA transcript that results at the end of the termination phase is considered to be unrefined , for it requires several modifications in order to increase its chances of surviving in the hostile environment of the cytoplasm. IV. Gene Expression: mRNA Processing ● If mRNA is not resistant to exonucleases within the cytoplasm, or unable to associate with a ribosome , translation leading to the synthesis of a polypeptide will be blocked. Thus, prior to leaving the nucleus, the “unrefined” mRNA transcript must be structurally modified in the following ways …
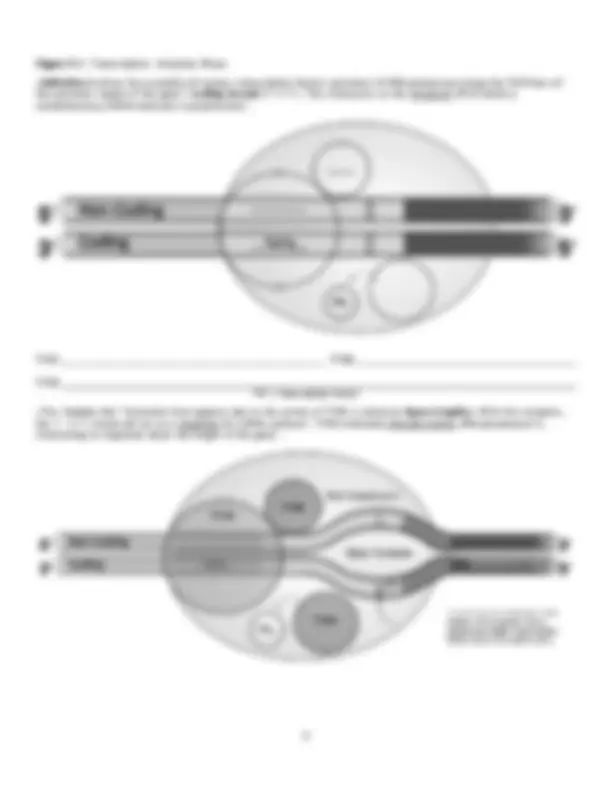
Figure 6. 3 : mRNA Processing: Intron Removal & Exon Splicing ● RNA polymerase II transcribes both introns & exons from a gene on DNA. Within mRNA, introns can be problematic, for they increase the likelihood of the molecule base pairing with itself. The resulting “kinks” within the mRNA can inhibit its ability to associate with a ribosome, thus ultimately blocking translation to form a polypeptide… ● Within the nucleus exists Small Nuclear Ribonuclear Particles (“snurps”) which possess a catalytic form of RNA, called snRNA. The “snurps”, with their snRNA, combine with various other proteins to form complexes known as Spliceosomes. Upon interacting with mRNA, the snRNA of the “snurps” identify the boundaries between introns & exons to introduce cuts at these regions. The exons are then joined (spliced) together to form a mRNA molecule that is intron free & thus shorter (and more easily managed by ribosomes). ● Different cell types possess different regulatory proteins that associate w/the spliceosome. These proteins may bind to select exons within the mRNA transcript, marking them for removal along w/introns ... Figure 6. 4 : Differential / Alternative mRNA Splicing
● As a result of the differential removal of selected mRNA exons in different cells, it is possible for the same gene to give rise to multiple proteins. This mechanism may be one reason humans can get along with a relatively small number of genes (20-25,000). Figure 7: Final mRNA Transcript ● After the addition of the 5’ cap, poly-A tail, & removal of introns (& select exons), the final mRNA transcript is exported from the nucleus. There it will interact with a ribosome to produce a polypeptide (protein) product. V. Gene Expression: Translation ●The final step in the expression of the information encoded by a gene into a protein product is Translation. In this process, the base sequence of mRNA is deciphered w/in a ribosome with the aid of Transfer RNA (tRNA) molecules to create a polypeptide/protein. Figure 8: Transfer RNA (tRNA) ● After the addition of an amino acid by an Aminoacyl-tRNA Synthase , the molecule is regarded as being “charged” (can actively participate in protein synthesis). Figure 8.1: Transfer RNA: Anticodon
● Due to wobble, a base substitution at the 3’ position of an mRNA codon won’t affect its amino acid “meaning”. This so-called Silent Mutation will not alter the final polypeptide product as a result of gene expression… Figure 8.3: Transfer RNA Anticodon: Wobble Base Pairing & “Silent” Mutations *Since the mutation at the 3’ position of the mRNA codon (GGC → GGU) corresponds to the wobble position of the anticodon, its amino acid “meaning” will not change.
Figure 9: Ribosome Structure & Function: Overview ● Ribosomes facilitate the interaction between mRNA (genetic code) & tRNA to promote polypeptide production (translation). The large & small subunits join to form a functional complex only when they attach to mRNA. During translation, the mRNA fits in a groove between the two subunits. Figure 10: Translation: Initiation Phase (Early) ● 5’ CAP of mRNA serves as a “landing platform” for the attachment of the small (30s) ribosome subunit. The 30s subunit then “scans” the mRNA for the start codon (AUG), whereupon the initiator tRNAmet^ binds to it via its anticodon.
● During Translocation , a sub-stage of elongation, the tRNA in the (P) site dissociates from the ribosome, & the tRNA in the (A) site, carrying the growing polypeptide, is shifted to the (P) site. This movement brings into the (A) site the next codon to be translated on the mRNA. Figure 10.3: Translation: Termination Phase ● Elongation continues until a stop codon ( UAA , UAG , & UGA ) reaches the A site of the ribosome. A protein called a Release Factor binds to the termination codon in the A site, causing the release of the polypeptide chain from the tRNA. This hydrolysis initiates the dissociation of the ribosomal subunits as well as the release of the mRNA transcript. ● The liberated polypeptide chains will undergo a modification process as amino acids may be altered by the addition of sugars, lipids, phosphate groups, etc. The chain will assume a specific conformation (3-D shape) with the help of molecular chaperones & join with other polypeptide chains to form a functional protein or enzyme. VI. Regulating Gene Expression: RNA Interference (RNAi) ● RNAi via Micro-RNA (miRNA) or Small Interfering RNA (siRNA) acts to “capture” mRNA in route to a ribosome prior to being translated. Consequently, no protein product is made & gene expression is essentially blocked. Figure 11: RNAi: General Mechanism ● si/miRNAs are small RNA molecules that base pair with themselves to form hairpin loop structures. Upon interacting with the enzyme Dicer , the hairpin is “trimmed” to form a short, double stranded si/miRNA molecule. These molecules then interact with a RISC Complex , which removes one of the two strands…
● si/miRNA-RISC complex can “capture” complementary mRNA molecules from the nucleus, preventing them from interacting with a ribosome. Consequently, the genetic code within the mRNA cannot be translated into a polypeptide/protein product. ● The aforementioned phenomenon by which si/mi RNA’s block gene expression is called RNA Interference , or RNAi. Functions of RNAi within the cell includes: a) RNAi participates in silencing of certain viral mRNA’s to block their translation into viral proteins. Thus, RNAi can inhibit the reproduction of certain viral strains to stop further infection. b) RNAi participates in Gene Silencing: mi/siRNA genes are selectively active in some cell types, leading to differential cell development. c) miRNA / RISC complex can intercept mRNA from harmful genes, even those of cancer cells to block their spread (e.g. angiogenesis gene, telomerase gene, etc)