


Part 4: Index Construction
Francesco Ricci
Most of these slides comes from the
course:
Information Retrieval and Web Search,
Christopher Manning and Prabhakar
Raghavan
1





































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An in-depth analysis of index construction in the field of information retrieval and web search. It covers various aspects such as hardware basics, sort-based index construction, blocked sort-based indexing, single-pass in-memory indexing, and distributed indexing. The document also discusses the use of mapreduce for index construction and the challenges of dynamic indexing.
Typology: Schemes and Mind Maps
1 / 48

This page cannot be seen from the preview
Don't miss anything!
Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan 1
Index construction
Ch. 4 2
Hardware basics p Access to data in memory is much faster than access to data on disk p Disk seeks: No data is transferred from disk while the disk head is being positioned p Therefore transferring one large chunk of data from disk to memory is faster than transferring many small chunks p Disk I/O is block-based: Reading and writing of entire blocks (as opposed to smaller chunks) p Block sizes: 8KB to 256 KB. Inside of Hard Drive video 4
Hardware basics p Servers used in IR systems now typically have several GB of main memory, sometimes tens of GB p Available disk space is several (2–3) orders of magnitude larger p Fault tolerance is very expensive: It’s much cheaper to use many regular machines rather than one fault tolerant machine. 5
Hardware assumptions p symbol statistic value p s average seek time 5 ms = 5 x 10 − 3 s p b transfer time per byte 0.02 μs = 2 x 10 − 8 s/B p processor’s clock rate 10 9 s − 1 p p low-level operation 0.01 μs = 10 − 8 s (e.g., compare & swap a word) p size of main memory several GB p size of disk space 1 TB or more p Example: Reading 1GB from disk n If stored in contiguous blocks: 2 x 10 − 8 s/B x 10 9 B = 20s n If stored in 1M chunks of 1KB: 20s + 10 6 x 5 x 10 − 3 s = 5020 s = 1.4 h 7
A Reuters RCV1 document 8
p Documents are parsed to extract words and these are saved with the Document ID. I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me. Doc 1 So let it be with Caesar. The noble Brutus hath told you Caesar was ambitious Doc 2 Recall IIR 1 index construction Term Doc # I 1 did 1 enact 1 julius 1 caesar 1 I 1 was 1 killed 1 i' 1 the 1 capitol 1 brutus 1 killed 1 me 1 so 2 let 2 it 2 be 2 with 2 caesar 2 the 2 noble 2 brutus 2 hath 2 told 2 you 2 caesar 2 was 2 ambitious 2 10
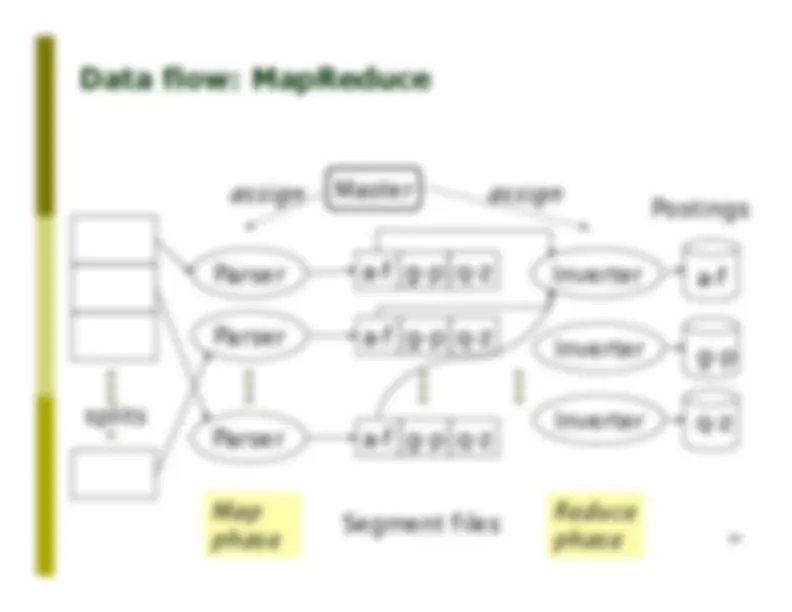
Key step p After all documents have been parsed, the inverted file is sorted by terms. We focus on this sort step. We have 100M items to sort for Reuters RCV1 (after having removed duplicated docid for each term)
Sort-based index construction p As we build the index, we parse docs one at a time n While building the index, we cannot easily exploit compression tricks (you can, but much more complex) n The final postings for any term are incomplete until the end p At 12 bytes per non-positional postings entry (term, doc, freq) , demands a lot of space for large collections p T = 100,000,000 in the case of RCV1 – so 1.2GB n So … we can do this in memory in 2015, but typical collections are much larger - e.g. the New York Times provides an index of >150 years of newswire p Thus: We need to store intermediate results on disk. 13
Use the same algorithm for disk? p Can we use the same index construction algorithm for larger collections, but by using disk instead of memory? n I.e. scan the documents, and for each term
n Finally sort the postings and build the postings lists for all the terms p No: Sorting T = 100,000,000 records (term, doc, freq) on disk is too slow – too many disk seeks n See next slide p We need an external sorting algorithm. 14
Solution (2ds-time + comparison-time)Nlog 2 N seconds = (25
)* 10 8 log 2 8 ~= (25
8 since the time required for the comparison is actually negligible (as the time for transferring data in the main memory) = 10 6
8 = 10 6
17 Gaius Julius Caesar Divide et Impera
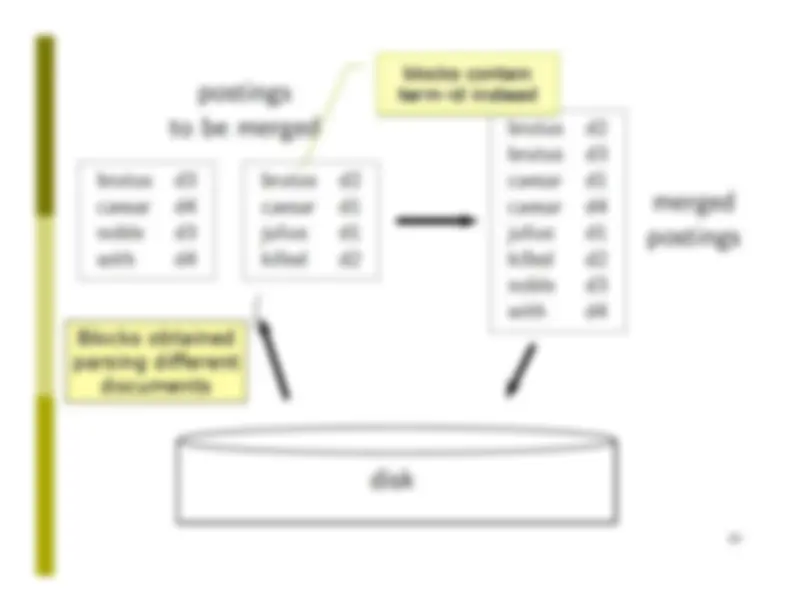
Blocks obtained parsing different documents 19 blocks contain term-id instead
Sorting 10 blocks of 10M records p First, read each block and sort ( in memory ) within: n Quicksort takes 2 N log 2 N expected steps n In our case 2 x (10M log 2 10M) steps p Exercise: estimate total time to read each block from disk and quicksort it n Approximately 7 s p 10 times this estimate – gives us 10 sorted runs of 10M records each p Done straightforwardly, need 2 copies of data on disk n But can optimize this 20