


Inference about a population
proportion
BPS chapter 20
© 2006 W.H. Freeman and Company












Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The concepts of inferring population proportions using large sample confidence intervals and significance tests. It covers the calculation of sample proportions, the sampling distribution of proportions, and the conditions for inference. The document also includes an example of calculating a confidence interval for the proportion of arthritis patients experiencing adverse symptoms from a medication.
Typology: Exams
1 / 20

This page cannot be seen from the preview
Don't miss anything!
© 2006 W.H. Freeman and Company
Objectives (BPS chapter 20) Inference for a population proportion ^
The sample proportion ^
The sampling distribution of ^
Large sample confidence interval for
p
^
Accurate confidence intervals for
p
^
Choosing the sample size ^
Significance tests for a proportion
ˆ p
ˆ p
^
We choose 50 people in an undergrad class, and find that 10 of them areHispanic:
(proportion of Hispanics in sample)
^
You treat a group of 120 Herpes patients given a new drug; 30 get better:
(proportion of patients improving in sample)
The sample proportion We now study categorical data and draw inference on the proportion, orpercentage, of the population with a specific characteristic.If we call a given categorical characteristic in the population “success,”then the sample proportion of successes,
sample
in the ns
observatio of
count
sample
in the
successes of
count
ˆ^
= p
ˆ p ˆ p
ˆ p ˆ p
Sampling distribution of The sampling distribution of
is never exactly normal. But as the
sample size increases, the sampling distribution of
becomes
approximately normal.
ˆ p^ p ˆ
Conditions for inference on
p
we’ll see what to do practically
Large-sample confidence interval for
p
m *
m
C is the area under the standardnormal curve between
z * and
z
n p
p
z
SE z
m
m m p
ˆ^ )
(^1) ( ˆ
error of
margin the is
,
ˆ
−
=
± =
ˆ p
Upper tail probability P
z*^
50%
60%
70%
80%
90%
95%
96%
98%
Confidence level C
Let’s calculate a 90% confidence interval for the population proportion ofarthritis patients who suffer some “adverse symptoms.”What is the sample proportion
n p
p p N p^
p
What is the sampling distribution for the proportion of arthritis patients withadverse symptoms for samples of 440?For a 90% confidence level,
z
Using the large sample method, wecalculate a margin of error
m
With 90% confidence level, between 2.9% and 7.5% of arthritis patients taking this pain medication experience some adverse symptoms.
ˆ p
m
=
z
ˆ p (
−^
ˆ p ) n
Specifically, the actual confidence interval is usually less than the confidencelevel you asked for in choosing z*. But there is no systematic amount(because it depends on p).
Use with caution!
We now use the “plus four” method to calculate the 90% confidenceinterval for the population proportion of arthritis patients who suffersome “adverse symptoms.”
(^018). 0
(^011). (^0) *
(^645). 1
(^444) / ) (^056). 0 (^1) ( (^056). 0
(^645). 1
) 4
( ~) (^1) ( ~
≈
=
−
=
−
= m m
n p
p
z m
An approximate 90% confidence interval for
p
using the “plus four” method is:
Upper tail probability P
z*^
50%
60%
70%
80%
90%
95%
96%
98%
99%
99.5%
99.8%
99.9%
Confidence level C
With 90% confidence level, between 3.8% and 7.4% of arthritis patients taking this pain medication experience some adverse symptoms.
(^018). 0
(^056). 0 or
~ :
for CI % 90
±
±^
m p p
p
What is the value of the “plus four” estimate of
p
The margin of error will be less than or equal to
m
if
p*
is chosen to be 0.5.
Remember, though, that sample size is not always stretchable at will. There aretypically costs and constraints associated with large samples.
2
ˆ p
Significance test for
p
0
z^
=
ˆ p^
−
p
0
p^0
(
−
p
) 0
n
If H
is true, the sampling distribution is known 0
The likelihood of our sample proportion given thenull hypothesis depends on how far from p
our p^ 0
p^0
(
−^
p^0
)
n
p^0 ˆ p
ˆ p
P-values and one- or two-sided hypotheses
—
reminder
α
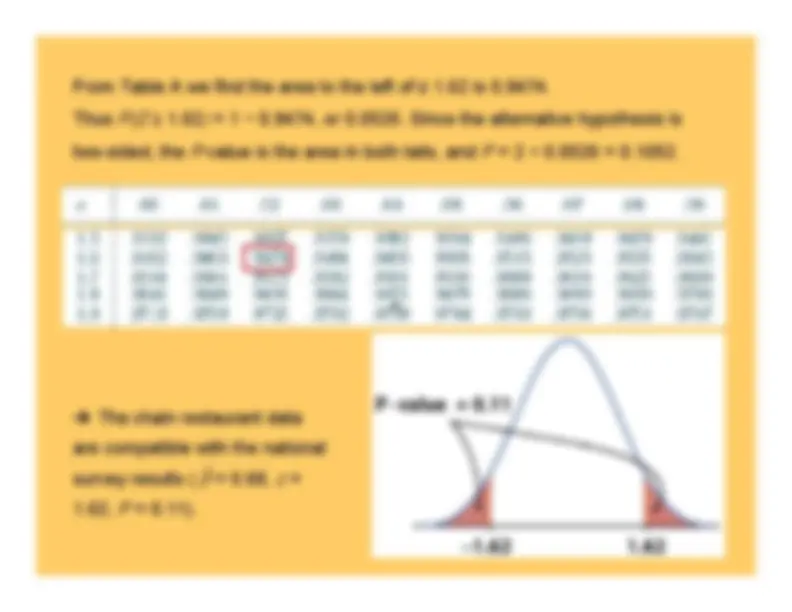
From Table A we find the area to the left of z 1.62 is 0.9474.Thus
. 9474, or 0.0526. Since the alternative hypothesis is
two-sided, the
-value is the area in both tails, and
The chain restaurant data are compatible with the nationalsurvey results (
z
ˆˆˆ ppp
ˆ p
Interpretation: magnitude versus reliability of effects^ The