


Statistics 511: Statistical Methods
Dr. Levine
Purdue University
Fall 2006
Lecture 18: Inferences Based on Two Samples
Devore: Section 9.1-9.2
Aug, 2006















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A lecture note from dr. Levine's statistics 511 class at purdue university, fall 2006. It covers the topic of inferencing between two samples, specifically focusing on z tests and confidence intervals for the difference of two population means. How to calculate the natural estimator and standard deviation of the difference between two sample means, and derives the z distribution of the test statistic under the assumption of equal variances. It also discusses the rejection regions for upper-tailed, lower-tailed, and two-tailed tests, as well as the calculation of type ii error and the choice of sample size.
Typology: Study notes
1 / 34

This page cannot be seen from the preview
Don't miss anything!
Purdue University
Lecture 18: Inferences Based on Two Samples
Devore: Section 9.1-9.
Aug, 2006
Purdue University
z
Tests and Confidence Intervals for a Difference Between Two
Population Means
An example of such hypothesis would be
μ
1
μ
2
or
σ
1
σ
2
. It may also be appropriate to estimate
μ
1
μ
2
and
compute its
α
confidence interval
1 ,... , X
m
is a random sample from a population with
mean
μ
1
and variance
σ
(^12)
1 ,... , Y
n
is a random sample from a population with mean
μ
2
and variance
σ
(^22)
and
samples are independent of one another
Aug, 2006
Purdue University
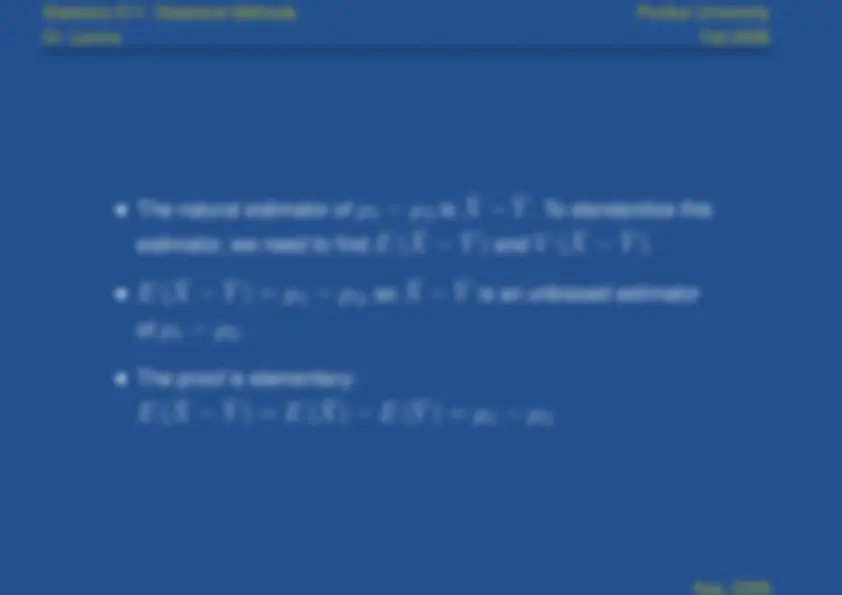
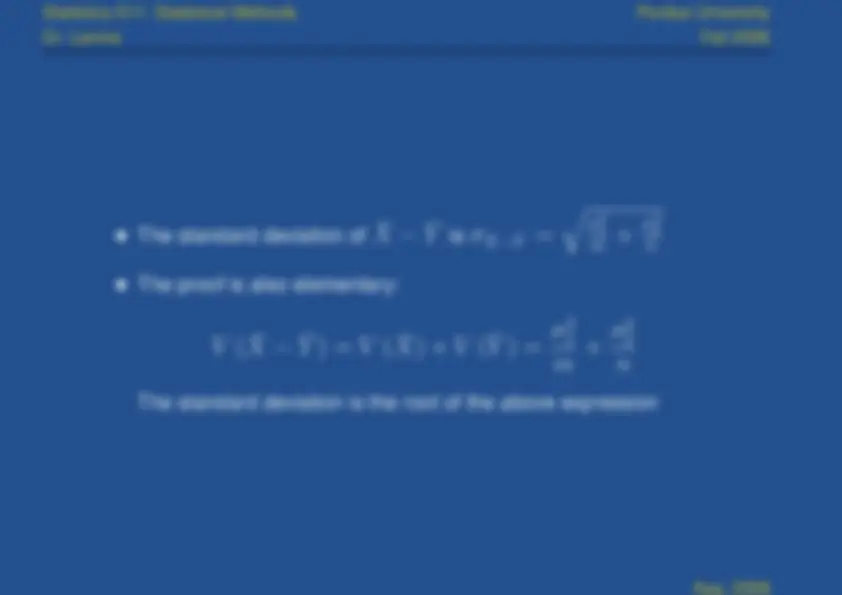
The standard deviation of
is
σ
¯
X
−
Y¯
σ 12
m
σ (^22)
n
The proof is also elementary:
σ
(^12)
m
σ
(^22)
n
The standard deviation is the root of the above expression
Aug, 2006
Purdue University
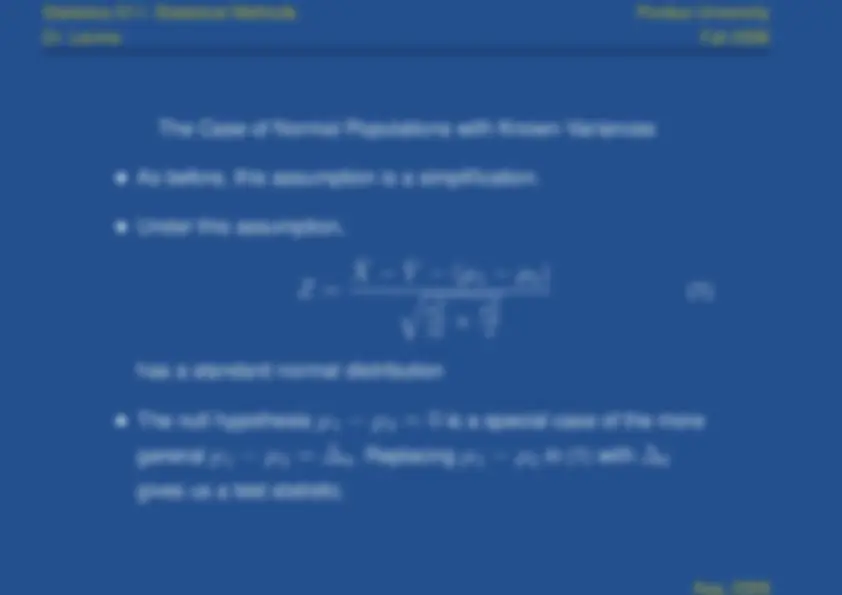
The Case of Normal Populations with Known Variances
As before, this assumption is a simplification.
Under this assumption,
− ( μ 1 − μ 2 )
σ (^12)
m
σ (^22)
n
(1)
has a standard normal distribution
The null hypothesis
μ
1
μ
2
is a special case of the more
general
μ
1
μ
2
0
. Replacing
μ
1
μ
2
in (1) with
0
gives us a test statistic.
Aug, 2006
Purdue University
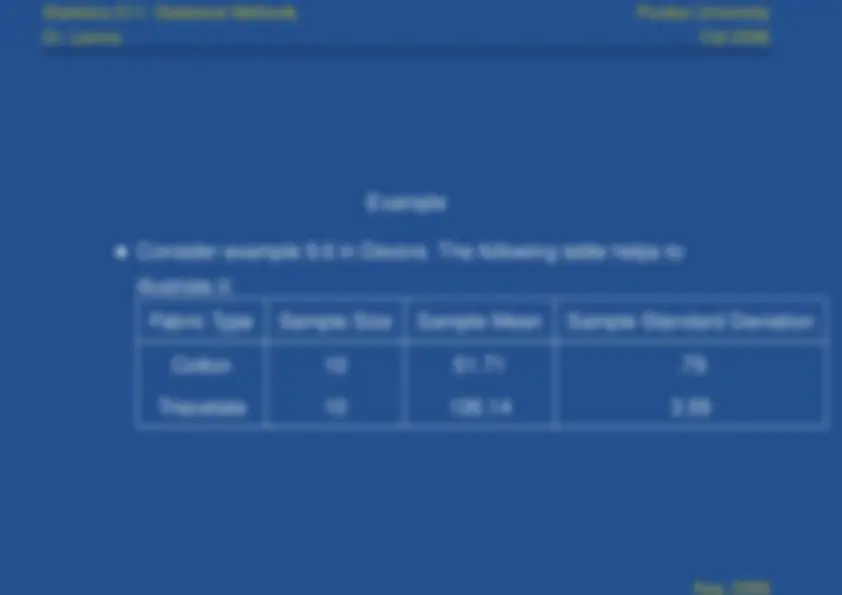
Example
Consider Ex. 9.1 in Devore. Sample sizes are
m
and
n
. Note that
m
n
...it is not important now but will be
later...
exploratory data analysisNote that the normality suggestion is based on some
The hypotheses are
H 0 : μ 1 − μ 2
and
H a : μ 1 − μ 2 6
The test statistic is
z
¯x
¯y
σ (^12)
m
σ (^22)
n
Aug, 2006
Purdue University
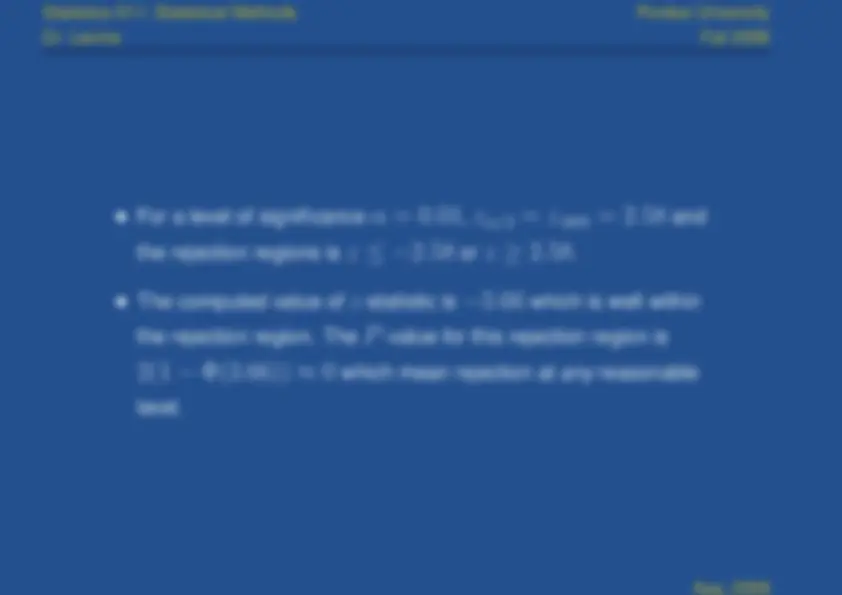
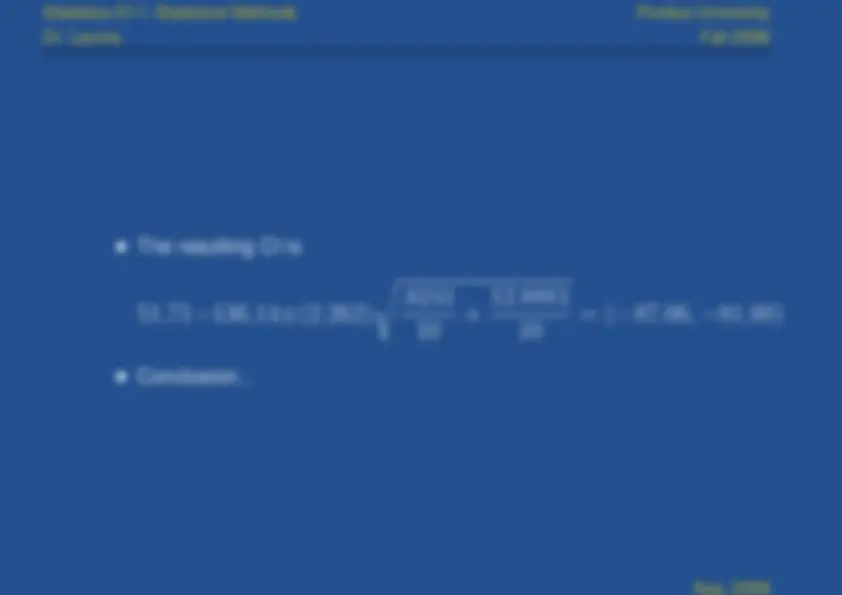
For a level of significance
α
,
z
α/
2
z
. 005
and
the rejection regions is
z
or
z
.
The computed value of
z
-statistic is
which is well within
the rejection region. The
(^) -value for this rejection region is
which mean rejection at
any reasonable
level.
Aug, 2006
Purdue University
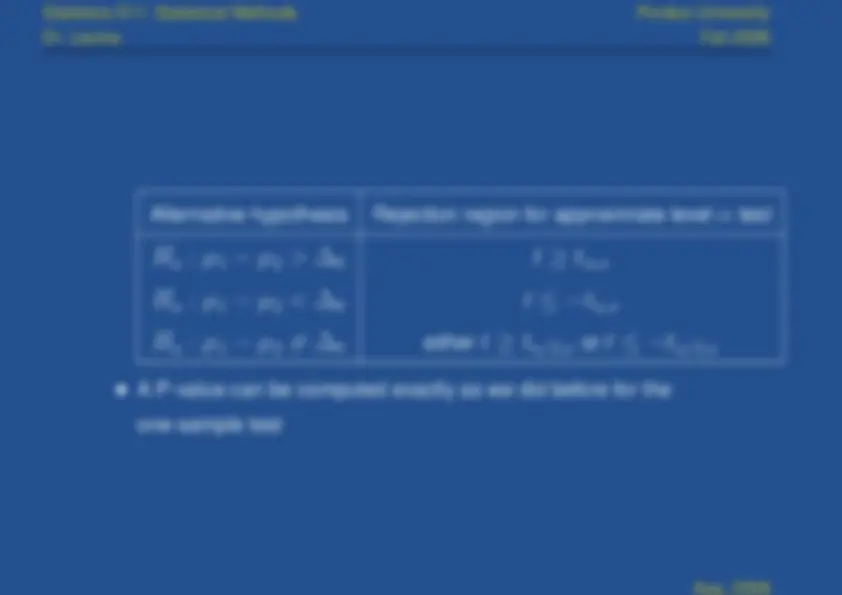
alternatives. In particular, ifSimilar results can be easily obtained for the other two possible
H a : μ 1 − μ 2 < ∆ 0
, we have
β
′ ) = 1
− Φ ( − z α − ∆ ′ − ∆ 0
σ
If
μ 1 − μ 2 6
0 , the probability of Type II Error is
z
α/
σ ) − Φ ( − z
α/
σ
Aug, 2006
Purdue University
Example
probability of detecting a differenceConsider Example 9.3 from Devore. Suppose that the
between the two means
should be
. Can the
level test with
m
and
n
support this?
β For a two-sample test we have
β Because the rejection region is symmetric, we have
β
, and, therefore, the probability of detecting a
difference of
is
β
.
We can conclude that slightly larger sample sizes are needed.
Aug, 2006
Purdue University
Large-Sample Tests
unnecessary and variancesIn this case, the assumption of normality for the data is
σ
1 2 (^) ,
σ
(^22)
need not be known
This is because for large
n
the variable
− ( μ 1 − μ 2 )
S
(^12)
m
S
(^22)
n
is approximately standard normal
Aug, 2006
Purdue University
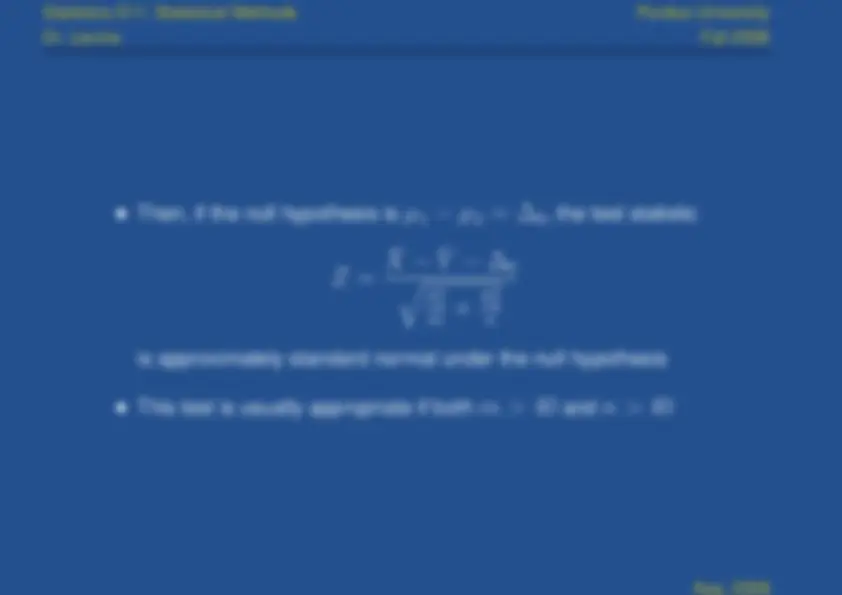
Then, if the null hypothesis is
μ
1
μ
2
0 , the test statistic
0
S
(^12)
m
S
(^22)
n
is approximately standard normal under the null hypothesis
This test is usually appropriate if both
m >
and
n >
Aug, 2006
Purdue University
and
H a : μ 1 − μ 2 > 0
Reject
0
if
Calculations:
z
27
2
40
31
2
40
Decision:
0
cannot be rejected at
α
; the
p
-value is
Aug, 2006
Purdue University
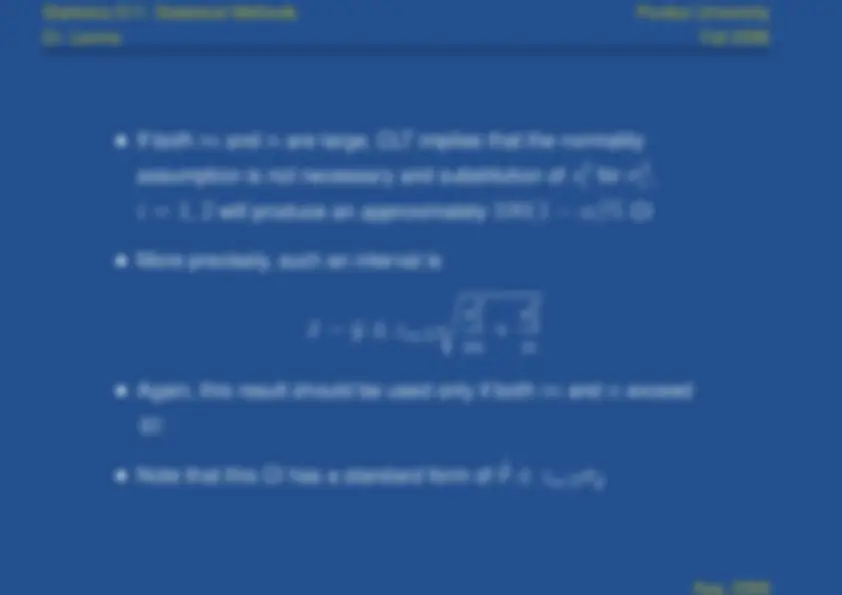
Confidence intervals for
μ
1
μ
2
Since the test statistic
that we just described is exactly
normal when
σ
1 2
and
σ
(^22)
are known,
z
α/
2
Y − ( μ 1 − μ 2 )
σ 12
m
σ 22
n
< z
α/
2
(^) α
The
α
CI is easy to derive from this probability
statement; it is
¯x
¯y
z
α/
2 σ
¯
X
−
Y¯
where
σ
¯
X
−
Y¯
is a square root expression.
Aug, 2006
Purdue University
Example
An experiment was conducted in which two types of engines,
and
, were compared. Gas mileage, in miles per gallon, was
measured.
experiments were conducted using engine type
and
were done for engine type
. The gasoline used and
engineother conditions were held constant. The average mileage for
was
mpg and the average for machine
was
mpg. Find an approximate
CI on
μ
B
μ
A
, where
μ
A
and
μ
B
are population mean gas mileage for machines
and
,
respectively. Sample standard deviation are
and
for
machines
and
, respectively.
Aug, 2006
Purdue University
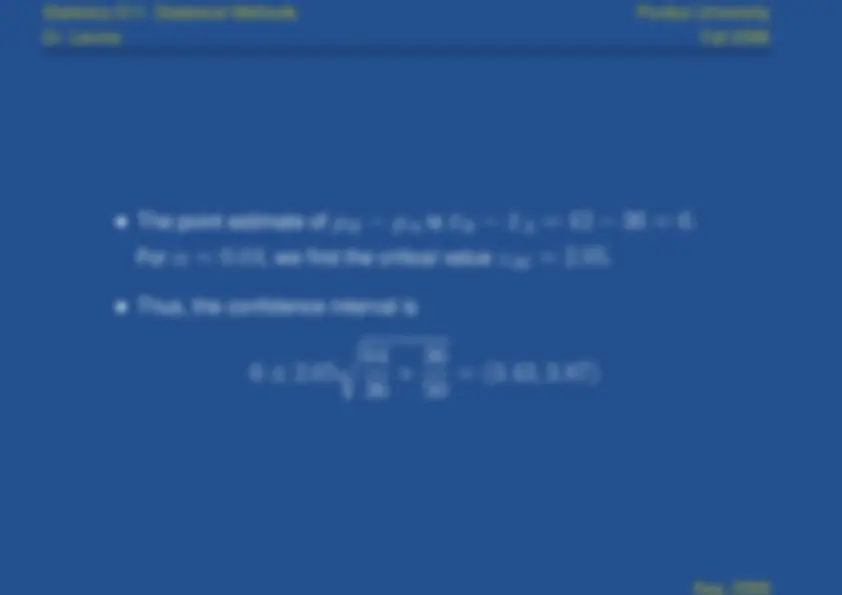
The point estimate of
μ
B
μ
A
is
¯x
B
¯x
A
.
For
α
, we find the critical value
z
. 02
.
Thus, the confidence interval is
Aug, 2006