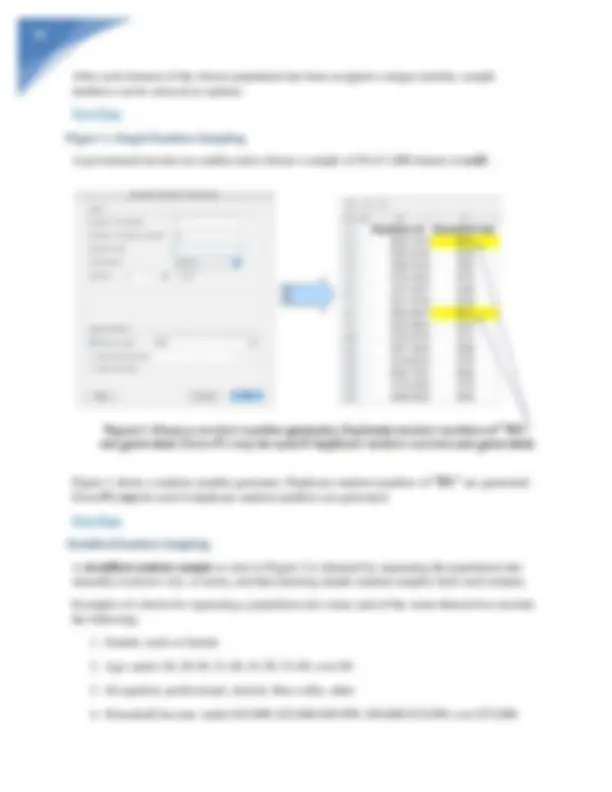
Download Inferential Statistics and Sampling Distributions and more Exams Nursing in PDF only on Docsity!
Review Questions
- A company has developed a new smartphone whose average lifetime is unknown. In order to estimate this average, 200 smartphones are randomly selected from a large production line and tested; their average lifetime is foundto be 5 years. The 200 smartphones represent a blank. o Sample
- Which of the following is a measure of the reliability of a statistical inference? o A Significance Level
- The process of using sample statistics to draw conclusions about populationparameters is called blank. o doing inferential statistics
- Which of the following statements involve descriptive statistics as opposed toinferential statistics? o The Alcohol, Tobacco and Firearms Department reported that Houston had 1,791 registered gun dealers in 1997.
- A population of all college applicants exists who have taken the SAT exam in the United States in the last year. A parameter of the population are blank. o SAT Scores
- Which of the following statements is true regarding the design of a goodsurvey? o The questions should be kept as short as possible
- Which method of data collection is involved when a researcher counts and records the number of students wearing backpacks on campus on a given day? o Direct observation
- The manager of the customer service division of a major consumer electronics company is interested in determining whether the customers who have purchased a videocassette recorder over the past 12 months are satisfied with their products. If there are four different brands of videocassette recorders madeby the company, the best sampling strategy would be to use a blank. o stratified random sample
- Which of the following types of samples is almost always biased?
o Self-selected samples
- is an expected error based only on the observations limited to asample taken from a population. o sampling error
- Bayes's Law is used to compute blank.
o the alternative hypothesis
- A Type I error occurs when we blank. o reject a true null hypothesis
- Statisticians can translate p-values into several descriptive terms. Suppose you typically reject H 0 at level 0.05. Which of the following statements is incorrect?
o If the p-value < 0.01, there is overwhelming evidence to infer that thealternative hypothesis is false.
- In a criminal trial where the null hypothesis states that the defendant is
innocent, a Type I error is made when blank. o an innocent person is found guilty
- To take advantage of the information of a test result using the rejection regionmethod and make a better decision on the basis of the amount of statistical evidence we can analyze the blank. o p-value
- An unbiased estimator is blank. o a sample statistic, which has an expected value equal to the value of thepopulation parameter
- Thirty-six months were randomly sampled and the discount rate on new issues
of 91-day Treasury Bills was collected. The sample mean is 4.76% and the standard deviation is 171.21. What is the unbiased estimate for the mean of the population? o 4.76%
- A 98% confidence interval estimate for a population mean is determined to be
75.38 to 86.52. If the confidence level is reduced to 90%, the confidenceinterval for population mean blank. o becomes narrower
- Suppose the population of blue whales is 8,000. Researchers are able to garnisha sample of oceanic movements from 100 blue whales from within this population. Thus, blank. o researchers can ignore the finite population correction factor 30.In the sample proportion, represented by p = x / n , the variable x refers
to blank. o The number of successes in the sample
- The distribution of the test statistic for analysis of variance is the o F -distribution
- In Fisher's least significant difference (LSD) multiple comparison method, the LSD value will be the same for all pairs of means if
- Assume a null hypothesis is found true. By dividing the sum of squares of all observations or SS(Total) by (n - 1), we can retrieve the blank. o sample variance
- Which of the following is true about one-way analysis of variance? o n1 = n2 = … = nk is not required.
- A tabular presentation that shows the outcome for each decision alternativeunder the various states of nature is called a blank. o payoff table
- Which of the following statements is false regarding the expected monetaryvalue (EMV)? o In general, the expected monetary values represent possible payoffs. 38.In the context of an investment decision, blank is the difference
between what the profit for an act is and the potential profit given an optimal decision. o an opportunity loss
- The branches in a decision tree are equivalent to o events and acts
- Which of the following is not necessary to compute posterior probabilities? o EMV
- Which of the following statements about decision analysis is false? o Decisions can never be made without the benefit of knowledge gainedfrom sampling
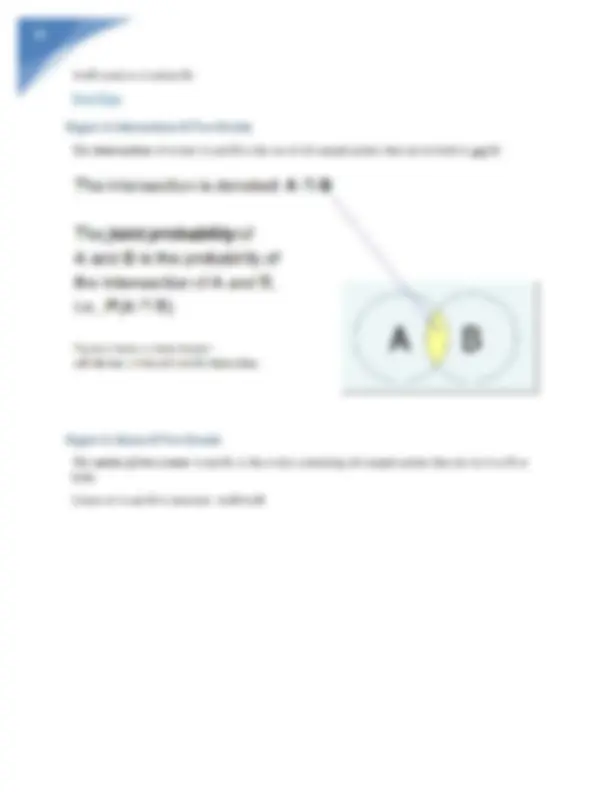
- can identify when two events are relational o Conditional probability
- An approach of assigning probabilities, which assumes that all outcomes of theexperiment are equally likely is referred to as the o Classical Approach
- The expected value of perfect information is the same as o The expected opportunity loss for the best alternative
- Which of the following is False? o The EMV decision is always different from the EOL decision
- A payoff table lists monetary values for each possible combination of the o Event (state of nature) and act (alternative)
- When a person receives an email questionnaire and places it in their deleteditems witout responding, they are contributing to
o Non-response error
- The Notion represents the probability of B when A has occurred o P(B/A)
- When is the tukey multiple comparison method used o To test for difference in pairwise means62.Which of the following statements is false
o A confidence level expresses the degree of certainty that an INTERVAL will include the actual value of the SAMPLE STATISTIC
- Though not the most efficient method rolling four dice enough times will result in theoretical probabilities being similar to o The relative frequency
- The standard error is o The standard deviation of the sampling distribution 65.For a given level of significance, if the sample size increases. The probability of a type II error will o Decrease
- A study is under way to determine the average height of all 32,000 adult pinetrees in a certain national forest. The heights of 500 randomly selected adult pine trees are measured and analyzed. The sample in this study is o the 500 adult pine trees selected at random selected at random from this forest.
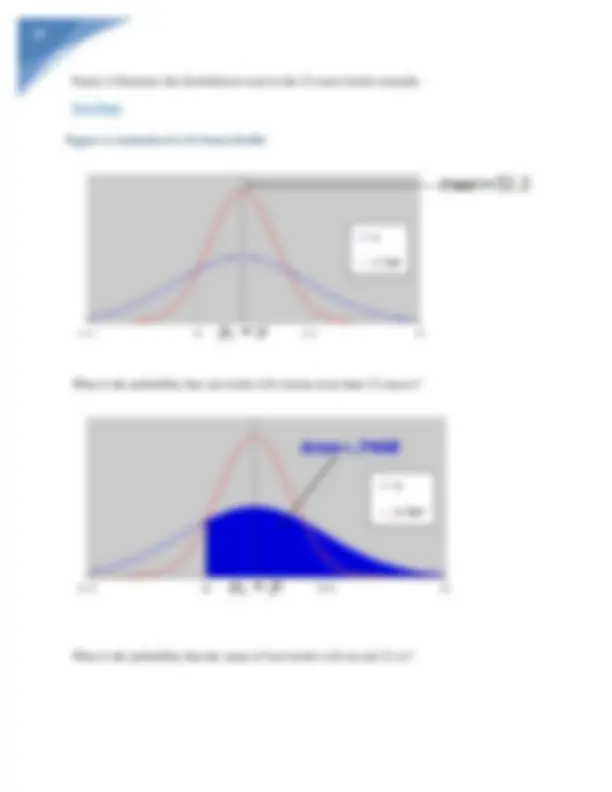
- The average sales per customer at a home improvement store during the past year is $75 with a standard deviation of $12. The probability that the averagesales per customer from a sample of 36 customers, taken at random from thispopulation, exceeds $78 is o.
- Which of the following is a rule violation in hypothesis testing o We accept the null hypothesis
What Is Statistics?
"Statistics is a way to get information from data."
The first is the "typical" grade. We call this a measure of central location. The mean (or average) is one such measure; it is the sum of all the data values divided by the number of values. Suppose the student was told that the average grade last year was 67. Is this enough information to reduce
his anxiety? The student would likely respond "no" and he would like to know whether most of the grades were close to 67 or if the grades were scattered far below and above the average. He needs a measure of variability. The simplest such measure is the range , which is calculated by subtracting the smallest number from the largest. Suppose the highest grade is 96 and the lowest grade is 24. The range of grades is 72. Unfortunately, this range calculation provides little additional information. The student also wants to know how the grades are distributed between 24 and 96. Next Page
Descriptive Statistics
The median is the midpoint of the distribution where 50% of the data values are higher and 50% are lower. (Note that the mean and median will not necessarily be an observed test score.) Finally, the mode is the most frequently occurring data value. The student might find it useful to know that the median score was 78 and the modal score was 80. He now knows that half the students scored 78 or higher and that 80 was the most frequently occurring test score. Apparently some very low test scores dragged the average down to 67. (See Figure 1.) There are two more measures of variability which are used in statistics. The variance is the average squared deviation from the mean. To compute the variance, the difference between each data value and the mean is calculated and squared. The mean of the resulting squared differences is the variance. Note that if the differences are not squared, their sum will always be 0. If the data values are, for example, heights in inches, the resulting variance will be measured in square inches. As we move further into our study of statistics, we will often use standard deviation as the measure of variability. Standard deviation is simply the square root of the variance and gets the variability measure back to the same units as the data. Standard deviation has many useful properties when the data is normally distributed. Next Page
Figure 1: Summary Statistics
1, 3, 3, 6 , 7, 8, 9 Median = 6 1, 3, 3, 4 , 5 6, 8, 9 Median = 4.
exclusivity agreement that would give Pepsi exclusive rights to sell its products at all university facilities for the next year with an option for future years. In return, the university would receive
35% of the on-campus revenues and an additional lump sum of $200,000 per year. Pepsi has been given 2 weeks to respond. The market for soft drinks is measured in terms of 12-ounce cans. Pepsi currently sells an average of 22,000 cans per week (over the 40 weeks of the year that the university operates). The cans sell for an average of 75 cents each. The costs including labor amount to 20 cents per can. Pepsi is unsure of its market share but suspects it is considerably less than 50%. Next Page
Descriptive Statistics
A quick analysis reveals that if its current market share were 25%, then, with an exclusivity agreement, Pepsi would sell 88,000 (22,000 is 25% of 88,000) cans per week or 3,520,000 cans per year (over the 40 weeks of university operation). The profit or loss can be calculated. The only problem is that we do not know how many soft drinks are sold weekly at the university. Pepsi assigned a recent university graduate to survey the university's students to supply the missing information. Accordingly, she organizes a survey that asks 500 students to keep track of the number of soft drinks they purchase over the next 7 days. The information we would like to acquire is an estimate of annual profits from the exclusivity agreement. The data are the numbers of cans of soft drinks consumed in 7 days by the 500 students in the sample. We can use descriptive techniques to learn more about the data. In this case, however, we are not so much interested in what the 500 students are reporting as we are in knowing the mean number of soft drinks consumed by all 50,000 students on campus. To accomplish this goal, we need the second branch of statistics called inferential statistics. Next Page
Inferential Statistics
Inferential statistics is a body of methods used to draw conclusions or inferences about characteristics of populations based on sample data. The population in question in this case is the soft drink consumption of the university's 50,000 students. The cost of interviewing each student would be prohibitive and extremely time consuming. Statistical techniques make such endeavors unnecessary. Instead, we can sample a much smaller number of students (the sample size is 500) and infer from the data the number of soft drinks consumed by all 50,000 students. We can then estimate annual profits for Pepsi. When an election for political office takes place, the television networks cancel regular programming and instead provide election coverage. When the ballots are counted, the results are reported. However, for important offices such as president or senator in large states, the networks actively compete to see which will be the first to predict a winner. Winner predictions are made by using exit polls, wherein a random sample of voters who exit the polling booth is asked for whom they voted. From the data the sample proportion of voters supporting the candidates is computed.
Statistical inference is the process of making an estimate, prediction, or decision about a population based on sample data. Because populations are almost always very large, investigating each member of the population would be impractical and expensive. It is far easier and cheaper to take a sample from the population of interest and draw conclusions or make estimates about the population on the basis of information provided by the sample. However, such conclusions and estimates are not always going to be correct. For this reason, we build into the statistical inference a measure of reliability. There are two such measures, the confidence level and the significance level. The confidence level is the proportion of times that an estimating procedure will be correct. When the purpose of the statistical inference is to draw a conclusion about a population, the significance level measures how frequently the conclusion will be wrong in the long run.
Key Statistical Concepts
Next Page
Statistical Inference
Statistical inference is the process of making an estimate, prediction, or decision about a population based on a sample.
What can we infer about a Population’s Parameters based on a Sample’s Statistics? Next Page
Statistical Inference
Since statistical inference involves using statistics to make inferences about parameters, we can make an estimate, prediction, or decision about a population based on sample data. We can apply what we know about a sample to the larger population from which it was drawn! The rationale is large populations make investigating each member impractical and expensive. It is easier and cheaper to take a sample and make estimates about the population from the sample. However, such conclusions and estimates are not always going to be correct. For this reason, we build into the statistical inference “measures of reliability,” such as the confidence level and the significance level. The confidence level is the proportion of times that an estimating procedure will be correct. A confidence level of 95% means that estimates based on this form of statistical inference will be correct 95% of the time. When the purpose of the statistical inference is to draw a conclusion about a population, the significance level measures how frequently the conclusion will be wrong in the long run. A 5% significance level means that, in the long run, this type of conclusion will be wrong 5% of the time. Next Page
Confidence and Significance Levels
If we use αα (Greek letter "alpha") to represent significance, then our confidence level is 1−α1−α. This relationship can also be stated as confidence level plus significance level, which is equivalent to one: