



1
Information Gain
Which test is more informative?
Split over whether
Balance exceeds 50K
Over 50KLess or equal 50KEmployed
Unemployed
Split over whether
applicant is employed






Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Entropy: a common way to measure impurity. • Entropy = p i is the probability of class i. Compute it as the proportion of class i in the set.
Typology: Schemes and Mind Maps
1 / 13

This page cannot be seen from the preview
Don't miss anything!
Split over whether Balance exceeds 50K
Less or equal 50K Over 50K Unemployed Employed
Split over whether applicant is employed
Information Gain
Impurity/Entropy (informal)
p (^) i is the probability of class i Compute it as the proportion of class i in the set.
∑ − i
What does that mean for learning from examples?
16/30 are green circles; 14/30 are pink crosses log 2 (16/30) = -.9; log 2 (14/30) = -1. Entropy = -(16/30)(-.9) –(14/30)(-1.1) =.
Minimum impurity
Maximum impurity
not a good training set for learning
good training set for learning
7
1 43 0 (^) lo g 2 1 43 0 1 63 0 lo g 2 1 63 0= 0. 9 9 6 −^ ⋅
−^ ⋅
lo g^4 1 7
4 1 7
lo g 1 3 1 7
1 3 2 2 =
−^ ⋅
−^ ⋅
Entire population (30 instances) 17 instances
13 instances
(Weighted) Average Entropy of Children = 30 0.^3910.^615
(^17) =
+^ ⋅
(^) ⋅
Information Gain= 0.996 - 0.615 = 0.38 for this split
lo g 1 2 1 3
1 2 1 3
lo g^1 1 3
1 2 2 =
−^ ⋅
−^ ⋅
Information Gain = entropy(parent) – [average entropy(children)]
parent entropy
child entropy
child entropy
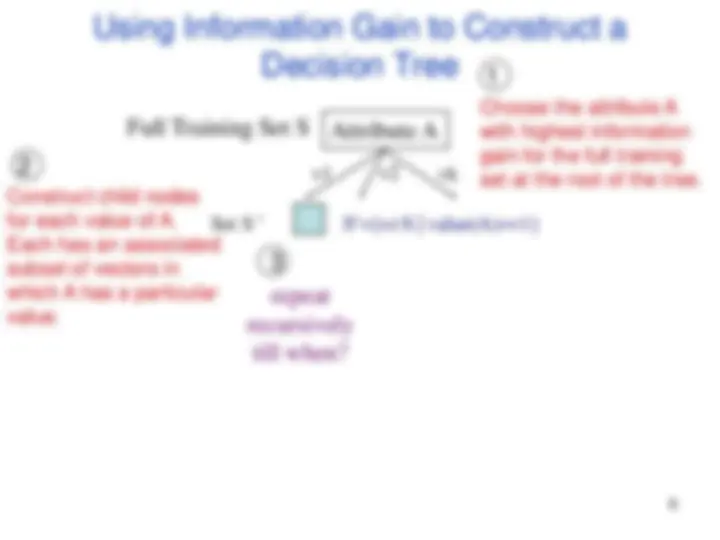
Node 1 What feature should be used? What values?
Training Set S x 1 =(f 11 ,f 12 ,…f1m) x 2 =(f 21 ,f 22 , f2m) . . xn =(fn1 ,f 22 , f2m)
Quinlan suggested information gain in his ID3 system and later the gain ratio, both based on entropy.
How would you distinguish class I from class II?
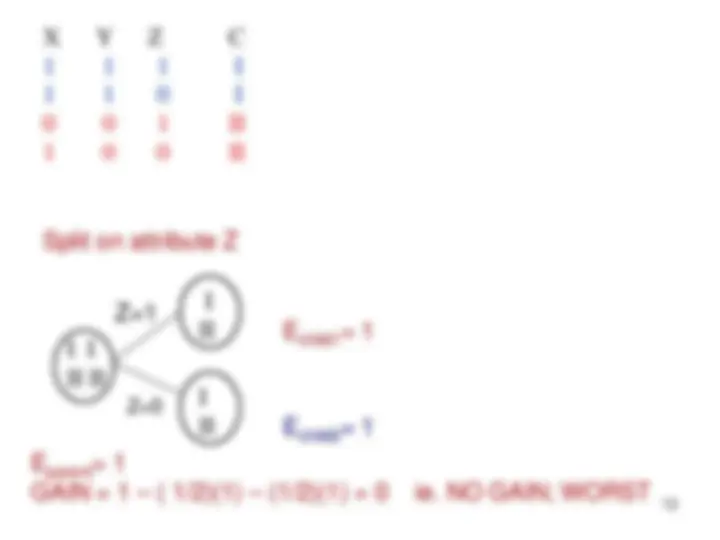
Training Set: 3 features and 2 classes
Split on attribute X
Eparent = 1 GAIN = 1 – ( 3/4)(.9184) – (1/4)(0) =.
X= Echild2 = 0
Echild1 = -(1/3)log 2 (1/3)-(2/3)log 2 (2/3) = .5284 +. =.
If X is the best attribute, this node would be further split.
Split on attribute Z
Eparent = 1 GAIN = 1 – ( 1/2)(1) – (1/2)(1) = 0 ie. NO GAIN; WORST
Z= Echild2 = 1
Echild1 = 1