Download introduction programming and more Lecture notes Programming Methodologies in PDF only on Docsity!
Table of Contents
- Introduction 1.
- Introduction to Algorithms Analysis 1.
- Growth Rates 1.2.
- Big-O, Little-o, Theta, Omega 1.2.
- Analysis of Linear Search 1.2.
- Analysis of Binary Search 1.2.
- Recursion 1.
- The runtime stack 1.3.
- How to Write a Recursive Function 1.3.
- Example: the Factorial Function 1.3.2.
- Drawbacks of Recursion and Caution 1.3.
- Lists 1.
- Implementation 1.4.
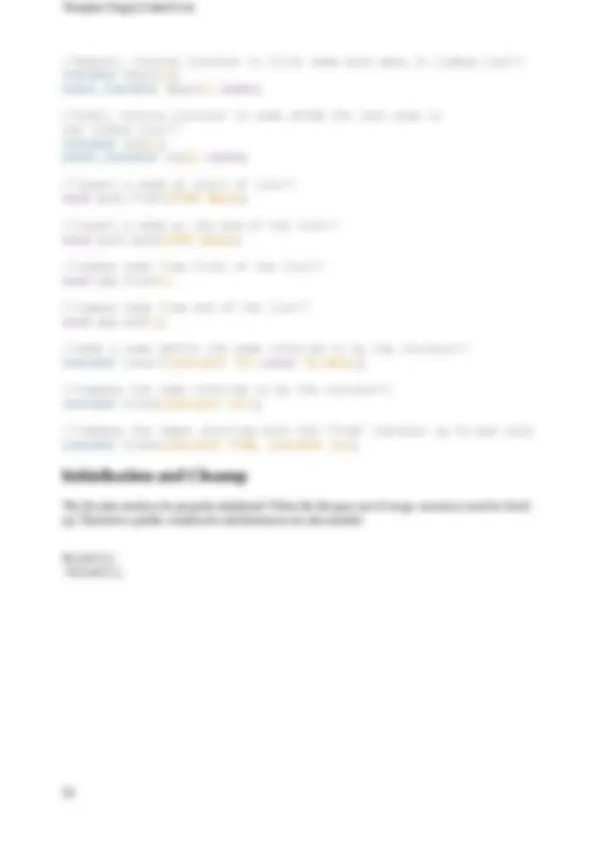
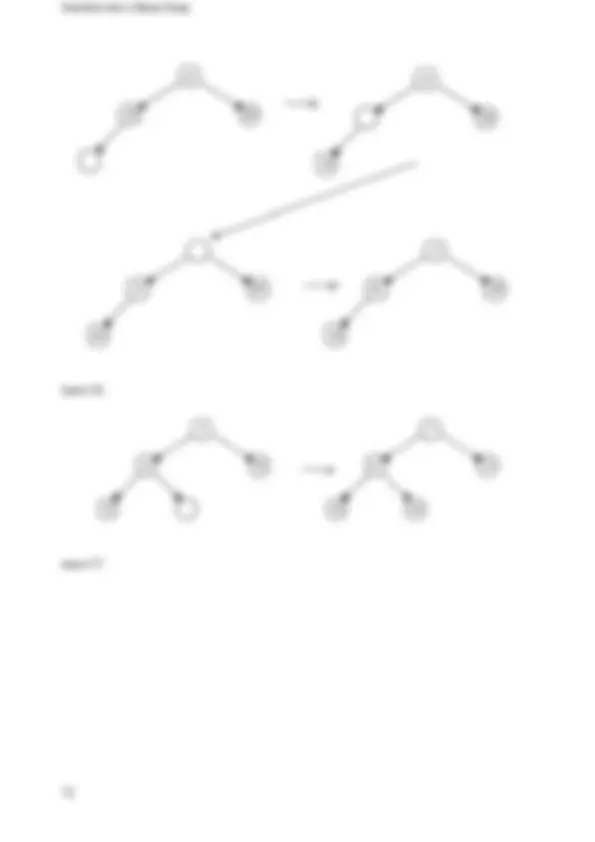
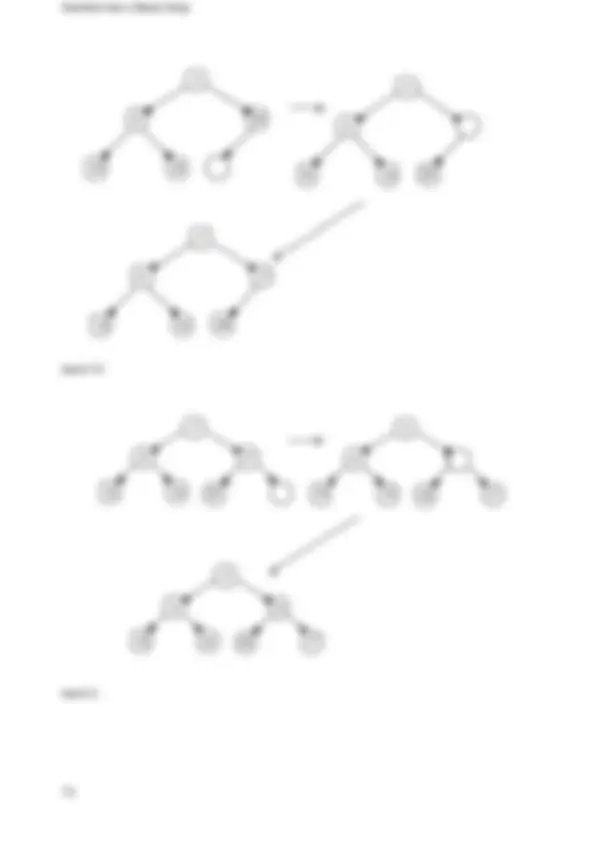
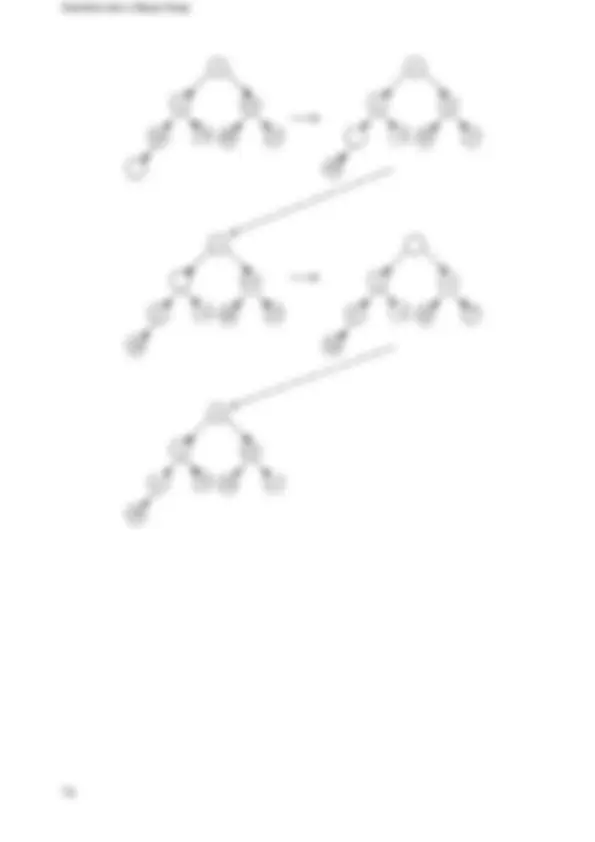
- Linked List 1.4.
- Nodes 1.4.2.
- Iterator 1.4.2.
- Template Singly Linked List 1.4.2.
- Doubly Linked List 1.4.2.
- Circular Linked List 1.4.2.
- Stacks 1.
- Stack Operations 1.5.
- Stack Implementations 1.5.
- Stack Applications 1.5.
- Queue 1.
- Queue Operations 1.6.
- Queue Implementations 1.6.
- Queue Applications 1.6.
- Tables 1.
- Simple Table 1.7.
- Hash Table 1.7.
- Bucketing 1.7.2.
- Chaining 1.7.2.
- Linear Probing 1.7.2.
- Quadratic Probing and Double Hashing 1.7.2.
- Sorting 1.
- Simple Sorts 1.8.
- Bubble Sort 1.8.1.
- Insertion Sort 1.8.1.
- Selection Sort 1.8.1.
- Merge Sort 1.8.
- Merge Sort Implementation 1.8.2.
- Quick Sort 1.8.
- Heap Sort 1.8.
- Binary heap 1.8.4.
- Binary heap basics 1.8.4.
- Insertion into a binary heap 1.8.4.
- Delete from a binary heap 1.8.4.
- Implementation 1.8.4.
- Sorting 1.8.4.
- Introduction to Trees, Binary Search Trees 1.
- Definitions 1.9.
- Tree Implementations 1.9.
- Binary Trees 1.9.
- Binary Search Trees 1.9.
- Insertion 1.9.4.
- Removal 1.9.4.
- Traversals 1.9.4.
- AVL Trees 1.
- Height Balance 1.10.
- Insertion 1.10.
- Why it works 1.10.
- 2-3 Trees 1.
- Graphs 1.
- Complexity Theory 1.
- Appendix: Mathematics Review 1.
Introduction to Algorithms Analysis
Introduction to Algorithms Analysis
When you write a program or subprogram you should be concerned about the resource needs of the program. The two main resources to consider are time and memory. These are separate resources and depending on the situation, you may end up choosing an algorithm that uses more of one resource in order to use less of the other. Understanding this will allow you to produce better code. The resource to optimize for depends on the application and the computing system. Does the program need to finish execution within a restricted amount of time? Does the system have a limited amount of memory? There may not be one correct choice. It is important to understand the pros and cons of each algorithm and data structure for the application at hand. The amount of resources consumed often depends on the amount of data you have. Intuitively, it makes sense that if you have more data you will need more space to store the data. It will also take more time for an algorithm to run. Algorithms Anaylsis does not answer the question "How much of a resource is consumed to process n pieces of data"... the real question it answers is "How much more of the same resource will it consume to process n+1 pieces of data". In other words what we really care about is the growth rate of resource consumption with respect to the data size. And with this in mind, let us now consider the growh rates of certain functions. Introduction to Algorithms Analysis
Growth Rates
Growth Rates Algorithms analysis is all about understanding growth rates. That is as the amount of data gets bigger, how much more resource will my algorithm require? Typically, we describe the resource growth rate of a piece of code in terms of a function. To help understand the implications, this section will look at graphs for different growth rates from most efficent to least efficient. Constant Growth Rate A constant resource need is one where the resource need does not grow. That is processing 1 piece of data takes the same amount of resource as processing 1 million pieces of data. The graph of such a growth rate looks like a horizontal line Logrithmic Growth Rate A logrithmic growth rate is a growth rate where the resource needs grows by one unit each time the data is doubled. This effectively means that as the amount of data gets bigger, the curve describing the growth rate gets flatter (closer to horizontal but never reaching it). The following graph shows what a curve of this nature would look like. Growth Rates
Quadratic Growth Rate A quadratic growth rate is one that can be described by a parabola. Cubic Growth Rate While this may look very similar to the quadratic curve, it grows significantly faster Growth Rates
Exponential Growth Rate An exponential growth rate is one where each extra unit of data requires a doubling of resource. As you can see the growth rate starts off looking like it is flat but quickly shoots up to near vertical (note that it can't actually be vertical) Growth Rates
O (log n ), O ( n ), O ( n log n ), O ( n ), O ( n ), O (2 ). Think about the graphs in the grow rate section. The way each curve looks. That is the most important thing to understand about algorithms analysis What all this means Let's take a closer look a the formal definition for big-O analysis " T ( n ) is O ( f ( n ))" if for some constants c and n , T ( n ) <= cf ( n ) for all n >= n The way to read the above statement is as follows. n is the size of the data set. f ( n ) is a function that is calculated using n as the parameter. O ( f ( n )) means that the curve described by f ( n ) is an upper bound for the resource needs of a function. This means that if we were to draw a graph of the resource needs of a particular algorithm, it would fall under the curve described by f ( n ). What's more, it doesn't need to be under the exact curve described by f ( n ). It could be under a constant scaled curve for f ( n )... so instead of having to be under the n curve, it can be under the 10 n curve or the 200 n curve. In fact it can be any constant, as long as it is a constant. A constant is simply a number that does not change with n. So as n gets bigger, you cannot change what the constant is. The actual value of the constant does not matter though. The other portion of the statement n >= n means that T ( n ) <= cf ( n ) does not need to be true for all values of n. It means that as long as you can find a value n for which T ( n ) <= cf ( n ) is true, and it never becomes untrue for all n larger than n , then you have met the criteria for the statement T ( n ) is O ( f ( n )) In summary, when we are looking at big-O, we are in essence looking for a description of the growth rate of the resource increase. The exact numbers do not actually matter in the end. 2 3 n 0 0 2 2 2 0 0 0 Big-O, Little-o, Theta, Omega
Analysis of Linear Search
How to do an Analysis
To look at how to perform analysis, we will start with a performance analysis of the following C++ function for a linear search: template int linearSearch(const vector& arr, const TYPE& key){ int rc=-1; for(int i=0;i<arr.size()&& rc==-1;i++){ if(arr[i]==key){ rc=i; } } return rc; } We will make a few assumptions. arr.size() runs in constant time. That is no matter how big the array is, arr.size() takes the same amount of time to run. When we run the above algorithm, 2 things can occur. The first is that we will find the key. The second is that we won't. The worst case scenario occurs when key is not in the array. Thus, let us start by performing the analysis base on that worst case. Analysis of an Unsuccessful Search Let n represent the size of the array arr. Let T(n) represent the number of operations necessary to perform linear search on an array of n items. Looking at the code, we see that there are some operations that we have to perform one time no matter what: int rc = - int i = 0 return rc;
So here, we can count these as 3 operations that have to occur at least once r Now we then look at the rest of the code, if our search was to fail we would h The following has to be done each time through the loop: i<arr.size() && rc == -1 --> 3 operations i++ --> 1 operation if(arr[i]==key) --> 2 operations ``` 6 operations in the loop total Now... some of you may also think... should the function call arr.size() be an operation itself? or what about the [i] in arr[i]? The truth is, it doesn't actually matter if we count them or not. Let's take a look Analysis of Linear Search Thus, we have proven that the function is _O_ ( _n_ ) because we were able to find the two constants _c_ and _n_ needed for the _T_ ( _n_ ) to be _O_ ( _n_ ) This is also the reason why it did not matter if we counted the operations for the size() function call or the [i] operator. If we counted both of them, _T_ ( _n_ ) = 8 _n_ + 3 The dominating term would still be 8n. The proof would go exactly the same way except that we can't use _n_ = 1 as the statement _T_ ( _n_ ) < _cn_ is not true when _n_ == 1. However, when _n_ = 2, _T_ ( _n_ ) = 19 and _cn_ would be 20. Thus, it would be true and stays true for all values of _n_ > 2. **Average case analysis** In the previous analysis, we assumed we wouldn't find the data and thus the worst possible case of searching through the entire array was used to do the analysis. However, what if the item was in the array? Assuming that key is equally likely to be in any element, we would have to search through n elements at worst and elements on average. Now since we will at some point find the item, the statement inside the if will also be performed. Thus, we will have 4 operations that we must run through once. 0 0 2 _n_ Analysis of Linear Search int rc = - int i = 0 rc=i return rc; These other operations will also run for each iteration of the loop: i<arr.size() && rc == -1 --> 3 operations i++ --> 1 operation if(arr[i]==key) --> 2 operations The difference is we do not expect that the loop would have to run through the entire array. On average we can say that it will go through half of the array. Thus: _T_ ( _n_ ) = 6 ∗ 0.5 _n_ + 4 = 3 _n_ + 4 Now... as we said before... the constant of the dominating term does not actually matter. 3 _n_ is still _n_. Our proof would go exactly as before for a search where the key would not found. Analysis of Linear Search By doing this, it would take the loop at most log n iterations before low>high Thus for an unsuccessful search, the function's runtime _O_ ( _logn_ ) For a successful search we might still need to search when high==low and to get to that point would also require iterations. Thus, the worst case runtime for this function when the key is found is also O(log n) Therefore, the worst case runtime for this function is _O_ ( _logn_ ) Analysis of Binary Search ## Recursion ## Recursion Recursion is one of those things that some of you may or may not have heard of / attempted. This section of the notes will introduce to you what it is if you do not already know and how it works. Some of this will be review some will not. Take your time to try and understand this process. It is important to know at least a little recursion because some algorithms are most easily written recursively. The text book sometimes only provide the recursive version of an algorithm so in order for you to understand it, you will need to understand how recursion works. Recursion ## How to Write a Recursive Function ## How to Write a Recrusive Function Recursive functions are sometimes hard to write because we are not use to thinking about problems recursively. However, there are two things you should do: 1. state the base case (aka easy case). what argument value will be the simplest case that you can possibly have for your problem? what should the result be given this simplest case 2. state the recursive case. if you are given something other than the simplest case how can you simplify it to head towards the simplest case? How to Write a Recursive Function ## Example: the Factorial Function ## Example: the Factorial Function Write the function: int factorial(int n); This function returns n! (read n factorial) where n is an integer. n!=n* n-1* n-2*....2*1 by definition 0! is 1 for example if n==5, then n! would be 5! = 5*4*3*2*1= To write this we must come up with several things. What is the base case? In other words, for what value of n do I immediately know what the answer would be without doing more than a simple operation or two. In this case, we know what 0! is. It is 1 by definition 1! is another base case because 1! is simply 1 as well. However, it is not actually necessary to explicitly state the base case for when n is 1 as we can further reduce that to the 0! base case So the base case occurs when n is 0 or 1. In this case, the function can simply return 1 Now the recursive case. How can we state the solution in terms of itself. First thing you should notice is that: 5!=5 * 4 * 3 * 2 * 1 but 4*3*2*1 is really 4! So: 5! = 5* 4! but 4! is just 4* 3! and so on. Thus if I had a function that can give me the factorial of any number I can use it to find the factorial of that number-1 and thus allowing me to calculate the factorial of the original by multiplying that result with number. In other words I can use the int factorial(int) function to solve int factorial(int) int factorial(int n){ int rc; //stores result of function if(n==1 || n==0){ //check for base case rc=1; //if n is 1 or 0 rc is 1 } else{ //else it is recursive case rc=n * factorial(n-1); //rc is n * (n-1)! } return rc; } **Why does this work?** Example: the Factorial Function