



Carnegie Mellon
Introduction to Computer Systems
15-213/18-243, spring 2009
1st Lecture, Jan. 12th
Instructors:
Gregory Kesden and Markus Püschel
The course that gives CMU its “Zip”!





































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Lecture notes from the first lecture of the course Introduction to Computer Systems at Carnegie Mellon. The lecture covers topics such as code security, memory referencing errors, and memory system performance. The notes include code examples and assembly code. The document could be useful as study notes or a summary for students taking the course or a similar course in computer systems.
Typology: Lecture notes
1 / 45

This page cannot be seen from the preview
Don't miss anything!
/* Kernel memory region holding user-accessible data */ #define KSIZE 1024 char kbuf[KSIZE];
/* Copy at most maxlen bytes from kernel region to user buffer */ int copy_from_kernel(void user_dest, int maxlen) { / Byte count len is minimum of buffer size and maxlen */ int len = KSIZE < maxlen? KSIZE : maxlen; memcpy(user_dest, kbuf, len); return len; }
/* Kernel memory region holding user-accessible data */ #define KSIZE 1024 char kbuf[KSIZE];
/* Copy at most maxlen bytes from kernel region to user buffer */ int copy_from_kernel(void user_dest, int maxlen) { / Byte count len is minimum of buffer size and maxlen */ int len = KSIZE < maxlen? KSIZE : maxlen; memcpy(user_dest, kbuf, len); return len; }
#define MSIZE 528
void getstuff() { char mybuf[MSIZE]; copy_from_kernel(mybuf, -MSIZE);
... }
double fun(int i) { volatile double d[1] = {3.14}; volatile long int a[2]; a[i] = 1073741824; /* Possibly out of bounds */ return d[0]; }
fun(0) – > 3. fun(1) – > 3. fun(2) – > 3. fun(3) – > 2. fun(4) – > 3.14, then segmentation fault
void copyji(int src[2048][2048], int dst[2048][2048]) { int i,j; for (j = 0; j < 2048; j++) for (i = 0; i < 2048; i++) dst[i][j] = src[i][j]; }
void copyij(int src[2048][2048], int dst[2048][2048]) { int i,j; for (i = 0; i < 2048; i++) for (j = 0; j < 2048; j++) dst[i][j] = src[i][j]; }
s1 s s5 s s s s s15 8m^ 2m^ 512k
128k
32k
8k
2k
0
200
400
600
800
1000
1200
Read throughput (MB/s)
Stride (words) Working set size (bytes)
Pentium III Xeon 550 MHz 16 KB on-chip L1 d-cache 16 KB on-chip L1 i-cache 512 KB off-chip unified L2 cache
0
5
10
15
20
25
30
35
40
45
50
0 1,000 2,000 3,000 4,000 5,000 6,000 7,000 8,000 9, matrix size
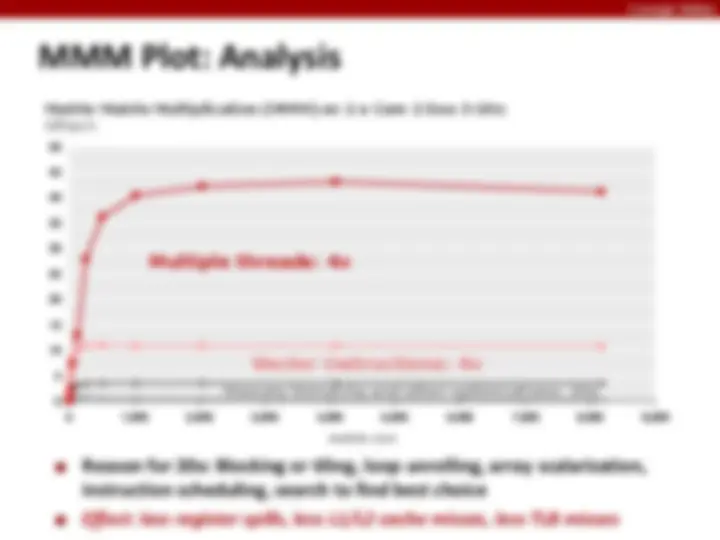
Matrix-Matrix Multiplication (MMM) on 2 x Core 2 Duo 3 GHz (double precision) Gflop/s
0
5
10
15
20
25
30
35
40
45
50
0 1,000 2,000 3,000 4,000 5,000 6,000 7,000 8,000 9, matrix size
Matrix-Matrix Multiplication (MMM) on 2 x Core 2 Duo 3 GHz Gflop/s
Memory hierarchy and other optimizations: 20x