



Introduction to Gaussian Processes
Docsity.com





























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Learn about gaussian processes, a powerful probabilistic modeling approach for regression, classification, and ordinal regression tasks. Understand the concept of model complexity, the role of gaussian distributions, and how to make predictions with noisy observations. Discover the importance of covariance functions and hyper-parameters in building large gaussians.
Typology: Study notes
1 / 39

This page cannot be seen from the preview
Don't miss anything!
Docsity.com
Learn scalar function of vector values f (x)
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
x
f(x) yi
0
(^1 )
1
−
0
5
x 1 x 2
f
We have (possibly noisy) observations {xi, yi}ni=1 Docsity.com
The world is often complicated:
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
simple fit complex fit truth
Problems:
— Fitting complicated models can be hard — How do we find an appropriate model? — How do we avoid over-fitting some aspects of model? Docsity.com
Factory settings x 1 → profit of 32 ± 5 monetary units
Factory settings x 2 → profit of 100 ± 200 monetary units
Which are the best settings x 1 or x 2?
Knowing the error bars can be very important. Docsity.com
If we come up with a parametric family of functions, f (x; θ) and define a prior over θ, probability theory tells us how to make predictions given data. For flexible models, this usually involves intractable integrals over θ.
We’re really good at integrating Gaussians though
−2−2 −1 0 1 2
−
0
1
2 Can we really solve significant machine learning problems with a simple multivariate Gaussian distribution? Docsity.com
Completely described by parameters μ and Σ:
P (f |Σ, μ) = | 2 πΣ|−
(^12) exp
− 12 (f − μ)T^ Σ−^1 (f − μ)
μ and Σ are the mean and covariance of the distribution. For example: Σij = 〈fifj〉 − μiμj
If we know a distribution is Gaussian and know its mean and covariances, we know its density function. Docsity.com
Any conditional of a Gaussian distribution is also Gaussian:
P (f , g) = N
a b
P (f |g) = N (a + CB−^1 (y − b), A − CB−^1 C>)
Showing this is not completely straightforward. But it is a standard result, easily looked up. Docsity.com
Previously we inferred f given g. What if we only saw a noisy observation, y ∼ N (g, S)?
P (f , g, y) = P (f , g)P (y|g) is Gaussian distributed; still a quadratic form inside the exponential after multiplying.
Our posterior over f is still Gaussian:
P (f |y) ∝
dg P (f , g, y)
(RHS is Gaussian after marginalizing, so still a quadratic form in f inside an exponential.)
Docsity.com
Three draws from a 25D Gaussian:
−
0
1
2
f
x To produce this, we needed a mean: I used zeros(25,1)
The covariances were set using a kernel function: Σij = k(xi, xj).
The x’s are the positions that I planted the tics on the axis.
Later we’ll find k’s that ensure Σ is always positive semi-definite.Docsity.com
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
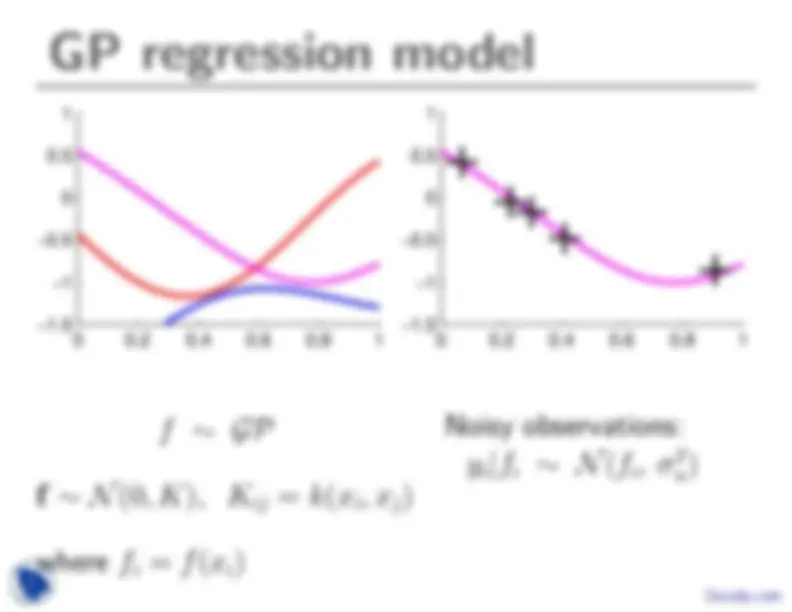
f ∼ GP
f ∼ N (0, K), Kij = k(xi, xj)
where fi = f (xi)
Noisy observations: yi|fi ∼ N (fi, σ n^2 )
Docsity.com
Two (incomplete) ways of visualizing what we know:
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
−1.5 0 0.2 0.4 0.6 0.8 1
−
−0.
0
1
Draws ∼ p(f |data) (^) Mean and error bars Docsity.com
Conditional at one point x∗ is a simple Gaussian:
p(f (x∗)|data) = N (m, s^2 )
Need covariances:
Kij = k(xi, xj), (k∗)i = k(x∗, xi)
Special case of joint posterior:
M = K + σ n^2 I m = k>∗ M −^1 y s^2 = k(x∗, x∗) − k︸ >∗ M︷︷ − 1 k︸∗ positive Docsity.com
We can represent a function as a big vector f
We assume that this unknown vector was drawn from a big correlated Gaussian distribution, a Gaussian process. (This might upset some mathematicians, but for all practical machine learning and statistical problems, this is fine.)
Observing elements of the vector (optionally corrupted by Gaussian noise) creates a posterior distribution. This is also Gaussian: the posterior over functions is still a Gaussian process.
Because marginalization in Gaussians is trivial, we can easily ignore all of the positions xi that are neither observed nor queried. Docsity.com
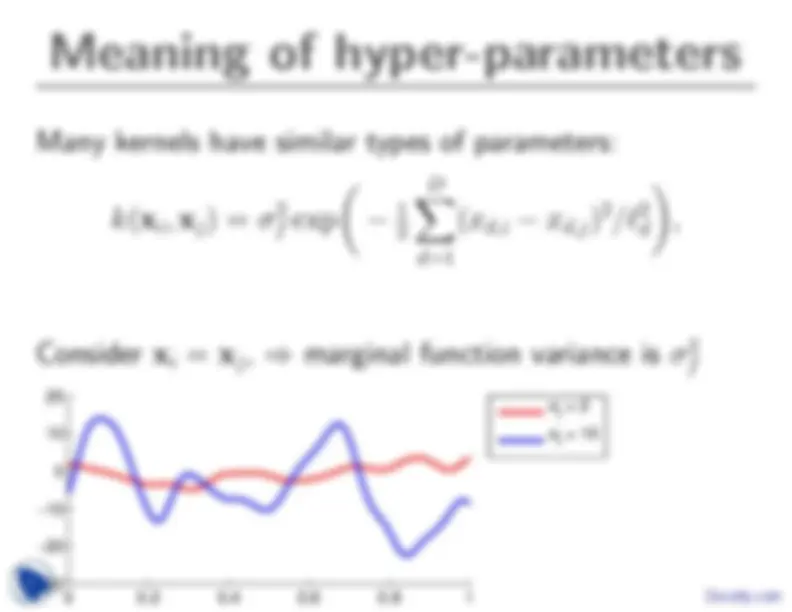
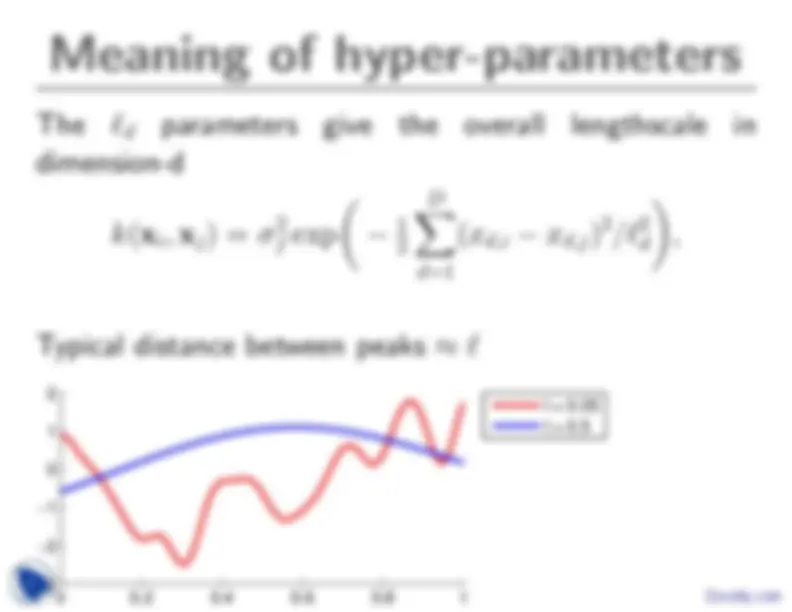
The main part that has been missing so far is where the covariance function k(xi, xj) comes from.
Also, other than making nearby points covary, what can we express with covariance functions, and what do do they mean?
Docsity.com