Download Junction Tree Algorithm: Exact Inference in Arbitrary Graphs - Prof. Volkan Cevher and more Study notes Statistics in PDF only on Docsity!
JUNCTION TREE ALGORITHM
Tuesday, September 9, 2008 Rice University STAT 631 / ELEC 639: Graphical Models Scribe: David Kahle Terrance Savitsky Stephen Schnelle
Instructor: Dr. Volkan Cevher
- Introduction In the previous scribes, we introduced general objects used in graphical models as well message passing schemes such as the sum-product algorithm and the max-sum algorithm for efficient computation of local marginals over subsets of the graph as well as the most probable state of the graph. For graphs which are trees, we noted that the algorithms are exact. In this article, we discuss a more flexible tool known as the junction tree algorithm which is used to compute local marginals of subsets of arbitrary graphs and yet still retains the property of being exact. The article draws largely from the exposition contained in Bishop[2], Lauritzen[4], Barber[1], and Wainwright and Jordan[5].
- The Junction Tree Algorithm The junction tree algorithm comprises 7 steps, listed below, which are expounded in the 7 subsections of this section.
(1) Moralize (directed graphs only) (2) Triangulate (3) Form the junction tree. (4) Assign the potentials to the junction tree cliques and initialize the separator potentials to unity (5) Select an (arbitrary) root clique (6) Carry out message passing with absorption to and from the root clique until updates passed along both directions of every link on the junction tree. (7) Read off the clique marginal potentials from the junction tree
2.1. Moralizing the graph (Directed graphs only). For uniform applicability, directed graphs require the additional step, called “moralization”, in order to be converted into an undirected graph. Thus, to perform the junction tree algorithm on an already undirected graph, one proceeds directly to step (2). The procedure described in this section is only necessary if we begin with a directed graph. Moralization, the transformation of the directed graph G~ = (NG~ , EG~ ) to an undi- rected graph G = (NG , EG ) plays an important role in the junction tree algorithm. Informally, moralizing entails adding edges between parents of nodes and dropping the directions. More formally, the transformation from G~ to G requires the addition (to EG~ ) of two sets, EG→G~ and EG↔~ ~G. The former joins the parents, and the latter “drops” the directions (by adding edges in the reverse direction). They are properly defined
EG→G~ :=
(Xi, Xj ) ∈ N 2 : ∃Xk ∈ N 3 : (Xi, Xk) ∈ EG~ and (Xj , Xk) ∈ EG~
EG↔~ G~ :=
(Xj , Xk) ∈ N 2 : (Xj , Xk) ∈ E/ G~ but (Xk, Xj ) ∈ EG~.
1
Thus, the moralization step is simply EG~ ∪ EG→G~ ∪ EG↔~ G~ , and the moralized graph is
(1) G := (NG~ , EG~ ∪ EG→G~ ∪ EG↔~ G~ ).
Example 1. Suppose we are presented with the directed graph G~ =
NG~ , EG~
where
NG~ := {A, B, C, D, E, F, G} EG~ := {(A, C), (A, D), (B, D), (C, F ), (D, F ), (D, G), (E, G)}.
A pictorial representation of G~ is contained in Figure 1. To moralize the graph, we join the parents and remove all directions. Here, A and B are both parents of D, so the edges (A, B) and (B, A) must be added to EG~ in the moralization step. Similarly, (C, D), (D, C), (D, E), (E, D) all need to be added. All of these are part of the joining step, that is, in EG→G~. Thus,
EG→G~ = {(A, B), (B, A), (C, D), (D, C), (D, E), (E, D)}. All that is left to do is remove the directions. This is done by adding all the re- verses of the edges which aren’t in the graph. For example, (A, C) ∈ EG~ but (C, A) ∈/ EG~ , so (C, A) needs to be added to EG~. Similarly, (D, A), (D, B), (F, C), (F, D), (G, D), and (G, E) should be added. The entire set is therefore simply the mirror image of EG~ ,
EG↔~ G~ = {(C, A), (D, A), (D, B), (F, C), (F, D), (G, D), (G, E)}. The undirected graph resulting from the moralization we simply call G,^1
(2) G := (NG~ , EG~ ∪ EG→G~ ∪ EG↔~ G~ ).
where
NG := {A, B, C, D, E, F, G}
(3) EG := {(A, C), (A, D), (B, D), (C, F ), (D, F ), (D, G), (E, G),
(A, B), (B, A), (C, D), (D, C), (D, E), (E, D), (C, A), (D, A), (D, B), (F, C), (F, D), (G, D), (G, E)}.
The undirected graph G made from the moralization of G~ is displayed in Figure 2 with the edges added by moralization in dashed blue.
||
2.2. Triangulating the graph. The second step (first for already undirected graphs) is triangulation. To begin, we need to have a notion of a triangulated graph. An undirected graph G is said to be triangulated if and only if for every cycle of length n ≥ 4 possesses a chord.^2 Thus, in triangulating the undirected graph G we are adding edges so that the new graph G^4 is triangulated.^3 The
(^1) This is instead of introducing new notation which makes explicit that it came from moralizing
G^ ~. Wherever the distinction is ambiguous, we will use the notation Gm. (^2) Recall that a n-cycle is a path with the same beginning and end; a chord is an edge joining a pair of nonconsecutive vertices in the cycle. Also recall that, by convention, the counting of cycle length begins with 0 as opposed to 1. (^3) In general, we will reserve the superscript 4 on an undirected graph G to emphasize that G is triangulated.
Upon inspection, the new graph, G(1), is still not a triangulated graph since it exhibits, for example, the 4-cycle A − C − D − E − A; so we must continue adding edges. Thus, we will add the undirected edge (A, D) and (D, A). As before the result is G(2)^ = (NG , EG(2) ) where
EG(2) = {(A, B), (B, C), (C, D), (D, E), (E, A), (A, C), (A, D) = (B, A), (C, B), (D, C), (E, D), (A, E), (C, A), (D, A)}.
However, unlike its predecessors, G(2)^ is triangulated. Thus, we set G^4 = G(2), completing the triangulation process.
||
Note that the triangulation procedure is not unique. The selection of which edges to add in Example 2 was completely arbitrary; we could have selected many different edges to add to triangulate G. Which edges are of greatest interest to add is a question which will not be examined in this article.
C
B
A
E D
Figure 3. The untriangulated graph G in Example 2
C
B
A
E D
Figure 4. The graph G(1)^ from Example 2 with the triangulation undirected edge in dashed red
2.3. Forming the junction tree. As in step (2), we begin with a few definitions. A hypergraph H is a collection of nonempty subsets of a finite set H (known as the base set). The elements of H (subsets of H) are referred to as
C
B
A
E D
Figure 5. The graph G(2)^ = G^4 from Example 2 with the trian- gulation undirected edges in dashed red
hyperedges.^4 For example, if G is a finite undirected graph, the set of cliques of G, denoted C(G), forms a hypergraph known as the clique hypergraph. Recall that a tree T = (NT , ET ) is any connected, undirected graph without cycles and that the key property of such graphs is uniqueness of path between any two vertices. A junction tree is, not surprisingly, a particular kind of tree. Specifically, a junction tree T J^ = (HT J , ET J ) is a tree whose nodes HT J are a hypergraph (with respect to some base set) with the additional property that the intersection U ∩ V of any two nodes U , V ∈ HT J is contained in every node W in the unique path joining U and V. The property is referred to as the running intersection property or the junction property. The definition of a junction tree is daunting at first because of the tiers of new definitions. Fortunately, a familiar example can help make the definition more tangible. It will also indicate why the formation of a junction tree is the third step in the algorithm.
Example 1 - Continued. Recall our graph achieved via moralization in Example 1 defined in (2) and (3) and pictured in Figure 2. Consider the clique hypergraph C(G). To be precise, to describe it we need to determine H. The base set is of course NG , and from the edge set EG we determine that
(4) C(G) = {{A, C, D} , {F, C, D} , {D, A, B} , {G, D, E}} ,
each set being a maximal clique of G. Now, the definition of the junction tree specifies that such a hypergraph is thought of as the nodes of a tree with a special property. So, if we set HT J = C(G), the only thing that stands in the way of us and having a junction tree is the edge set of the tree, ET J , which can be anything as long as the graph which it generates is undirected, connected, contains no cycles, and satisfies the running intersection property (meaning that it has to be both a tree and satisfy the running intersection property).
(^4) The definition of hypergraph is somewhat unfortunate. Intuitively, we would like a hypergraph to be a generalization of an undirected graph; however, precisely speaking, this is in fact not the case. The definition provided is closer to a generalization of what we have been referring to as the edge set of an undirected graph, EG. A more appropriate definition would be an ordered pair H = (NH, EH), where EH is a set of subsets (no longer restricted to pairs) of NH. In this definition, a hypergraph H would be akin to the familiar notions of topological space and measurable space, the difference being that the set EH is not defined through a set of axioms. For the purposes of this article, however, the definition will be the one provided in the main body.
There is one additional step which is taken when displaying the junction tree which makes explicit the running intersection property which will be so important in enforcing certain consistency properties later on in our discussion - that of introducing separator nodes. Displayed in the middle of each edge is placed a separator node which is conventionally boxed instead of circled, it contains the variables which are common to both of the nodes (the intersection). Thus, the junction tree we found in Example 2 is more commonly displayed as Figure 9; we will use this representation for the duration of the article.
F CD
DAB
ACD GCD
Figure 6. Graph on C(G) with edge set E T(1) J
F CD DAB ACD GCD
Figure 7. Graph on C(G) with edge set E (2) T J
GDE DAB ACD F CD
Figure 8. Graph on C(G) with edge set E T(3) J
GDE D DAB AD ACD CD F CD
Figure 9. Junction tree T J^ with separator nodes
2.4. Assigning potentials and initializing. From the Hammersley-Clifford theorem, we know that the joint density of all the variables in the original graph factors into an appropriately scaled product of potential functions over the maximal cliques. For the junction tree algorithm, the clique potentials are set to the original potentials over the undirected graph (or even more explicitly if they are known from a known directed graph structure, the conditional distributions themselves), just as they would be in the sum-product algorithm. The potentials for the separator nodes are set to unity.
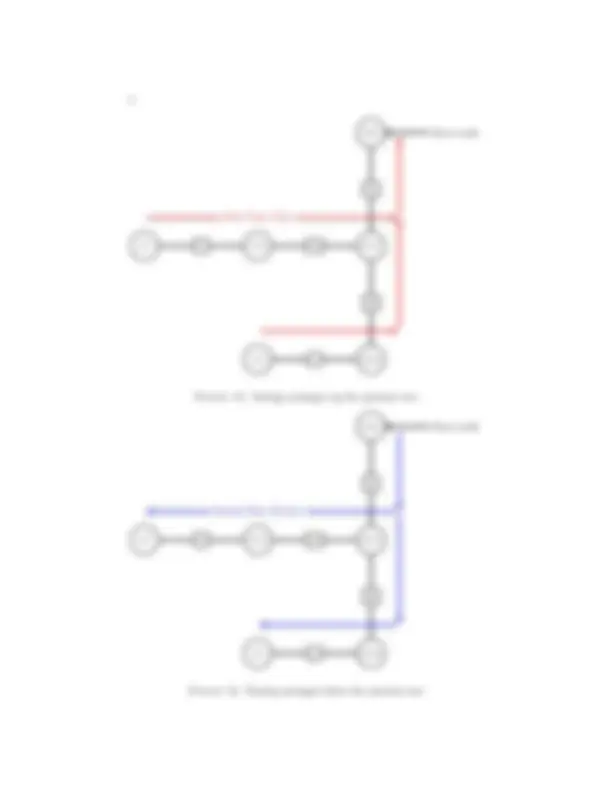
2.5. Selecting an arbitrary root node. The previous steps of the algorithm have been used to set up the nodes/cliques in a way that is suitable to apply a message passing algorithm. Now we must select a root node to begin. Each link between nodes and separators will be used twice during message passing, once in each direction. This is done by propagating messages “up” from each leaf to a root and then in reverse from the leaves to the root. Although trees are usually represented with a vertical orientation, we will represent them sideways as in 9 to preserve space.
Example 1 - Continued. In Figure 10, we select node GDE as root.
||
Root node
GDE D DAB AD ACD CD F CD
Figure 10. Junction tree T J^ with node GDE emphasized as root
2.6. Carrying out message passing. Potentials were assigned in step (4). Because we have created a junction tree, there will be at least one node of the junction tree that is connected to only one neighbor and is not our arbitrarily chosen root of the tree. Do not choose the root as the idea is for our first pass through the tree, we pass towards the root. Pass the messages using the standard message passing algorithms for graphical modes. Select other nodes that are connected to only one neighbor, if present, and pass towards the root. Once an internal node of the tree (more than one neighbor) has received messages from all those nodes which it separates from the root, pass its updated message along towards the root. Finally reverse this process. We can think of this in the sense of a traditional tree with a root node at the top; messages are passed up the tree at each stage, updating nodes along the path to the root with information from all of its children before moving up to the next level. Then with the updated root, we pass revised messages down the chain. Fortunately, messages must be passed along the links in each direction only once. Forming the junction tree ensures that this algorithm will converge.
- Consistency
The concept of consistency came into the discussion at the end of the junction tree algorithm. This concept is explored in more detain in this section in three parts - the idea, the importance, and the algorithm.
3.1. Idea. Given two adjacent nodes of the junction tree V and W , we wish the potentials resulting from marginalizing over V or W to their separator, S, to give the same potential for S.
∑
w\s
Ψ(w) = pS (s) =
v\s
Ψ(v); pS (s) = Ψ(s)
We call this condition of equality consistency. Global consistency would imply that for any two nodes V and W with intersection I, we have ∑
w\i
Ψ(w) =
v\i
Ψ(v)
Hence the joint probability distribution of the intersection of any two nodes is the same whether marginalizing within either node, even if the two nodes are not neighbors.
3.2. Importance. Ensuring consistency is important. The idea of the junction tree algorithm and many other message passing schemes is that marginalization to find variables in a cluster need only be done over that cluster. Essentially each cluster is localized, and effects of other clusters are factored in during the message passing algorithm, but need not be considered later. However localization should require that if we look at a variable in the intersection of two (or more) cliques, we get the same results for its density whether we marginalize over one clique or another. Fortunately consistency holds for a junction tree, under a variety of circumstances, including as data is observed and used to obtain better estimates of other parameter. This fact is outline in further detail below.
3.3. Algorithm. Suppose one or more variables in V = v is observed (and clamped to a particular state). Ψ∗^ represents the updated potential function due to the observed data Our task is to modify Ψ(w) and Ψ(s) to satisfy:
∑
w\s
Ψ∗(w) = Ψ∗(s) =
v\s
Ψ∗(v)
Absorption replaces Ψ∗(s) and Ψ∗(w) with
Ψ∗(s) =
v\s
Ψ(v)
Ψ∗(w) = Ψ(w) Ψ∗(s) Ψ(s)
Then,
w\s
Ψ∗(w) =
w\s
Ψ(w) Ψ∗(s) Ψ(s)
Ψ∗(s) Ψ(s)
w\s
Ψ(w)
Ψ∗(s) Ψ(s)
Ψ(s) = Ψ∗(s) =
v\s
Ψ∗(v)
and consistency is re-established. We say we have absorbed v into W through S.
- Example 2 A nice example is carried throughout [3] attributed to Lauritzen and Spiegelhalter. The following problem is set up, “Shortness-of breath (Dyspnoea) my be due to Tuberculosis, Lung cancer or Bronchitis, or none of them, or more than one of them. A recent visit to Asia increases the chances of Tuberculosis, while Smoking is known to be a risk factor for both Lung Cancer and Bronchitis. The results of a single X-ray do not discriminate between Lung Cancer and Tuberculosis, as neither does the presence or absence of Dyspnoea.” They set up the graphical model as shown in Figure 13.
A
T
E
X
L
S
B
D
Figure 13. Original graphical model in Example 2
For the first step in the algorithm, we moralize the graph as shown in Figure
- Next we triangulate the graph, as demonstrated in Figure 15. Then we form a corresponding junction tree, as in Figure 16. Separator nodes are added in Figure
- Now, we need to select a root node, so we select SBL and start passing messages up to and down from SBL as in Figure 18 and Figure 19. From here, we could obtain any marginal we desire.
||
AT T LE
XE
SBL
BLE
DBE
Figure 16. Junction tree of graph in Example 2
AT T LE
XE
SBL
BLE
DBE
T LE
E
BE
BL
Figure 17. Junction tree of graph in Example 2 with separators (initialized to 1)
Root node
First Pass (Up)
AT T LE
XE
SBL
BLE
DBE
T LE
E
BE
BL
Figure 18. Passing messages up the junction tree
Root node
Second Pass (Down)
AT T LE
XE
SBL
BLE
DBE
T LE
E
BE
BL
Figure 19. Passing messages down the junction tree