


kd-Trees
CMSC 420







Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
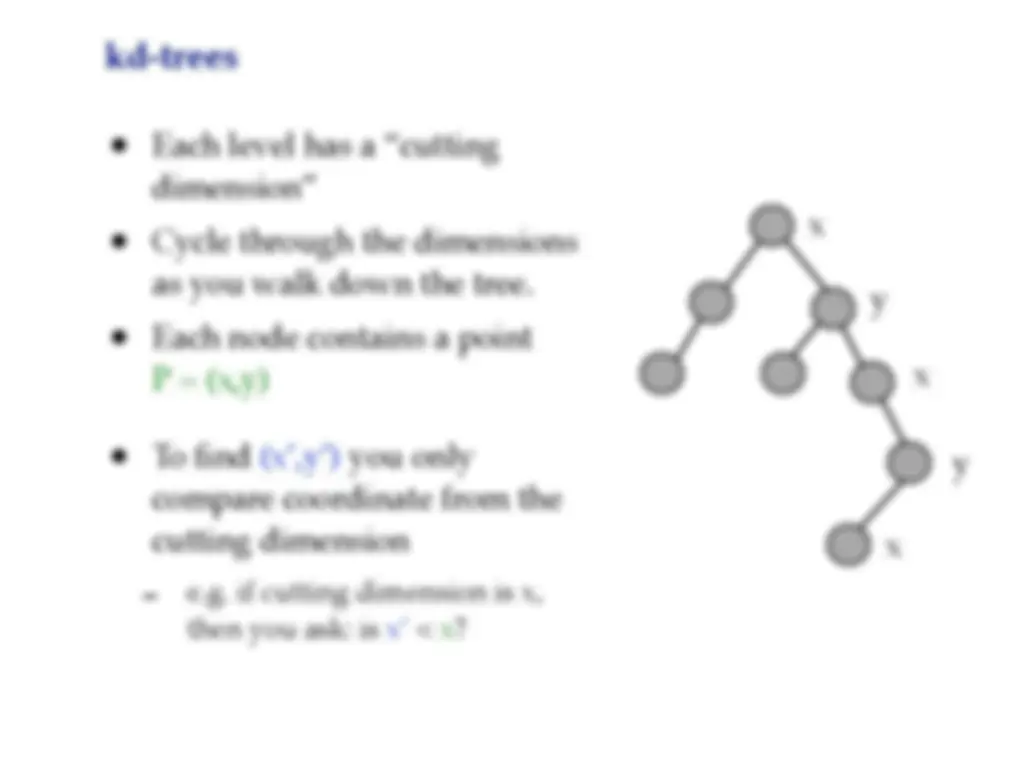
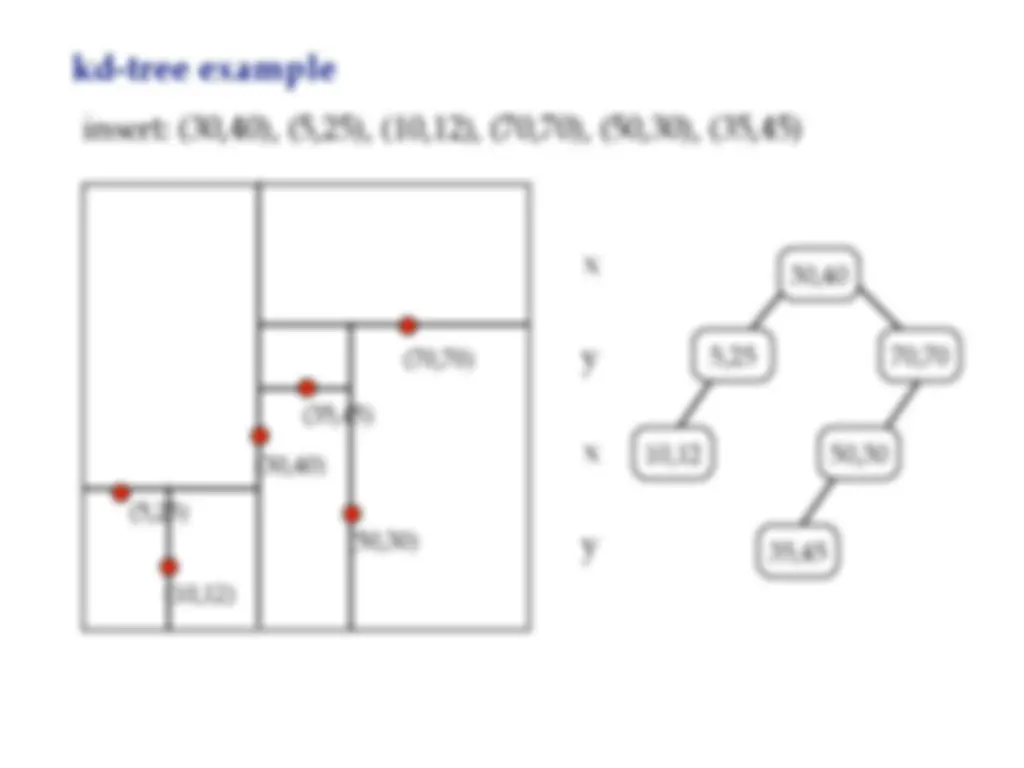
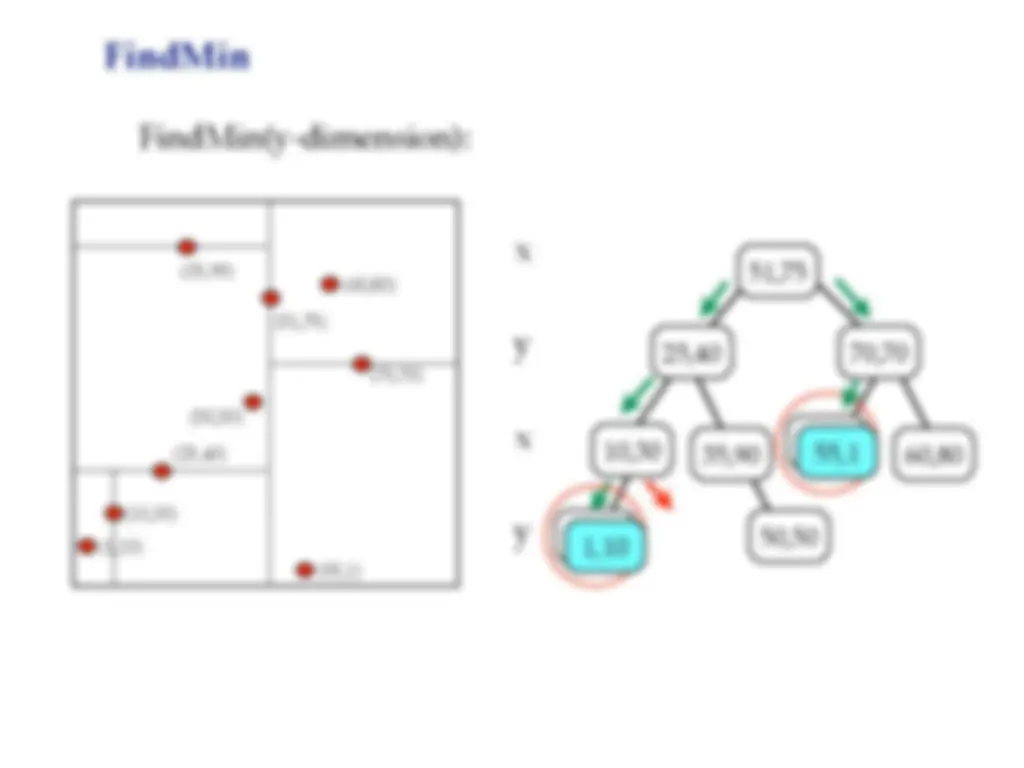
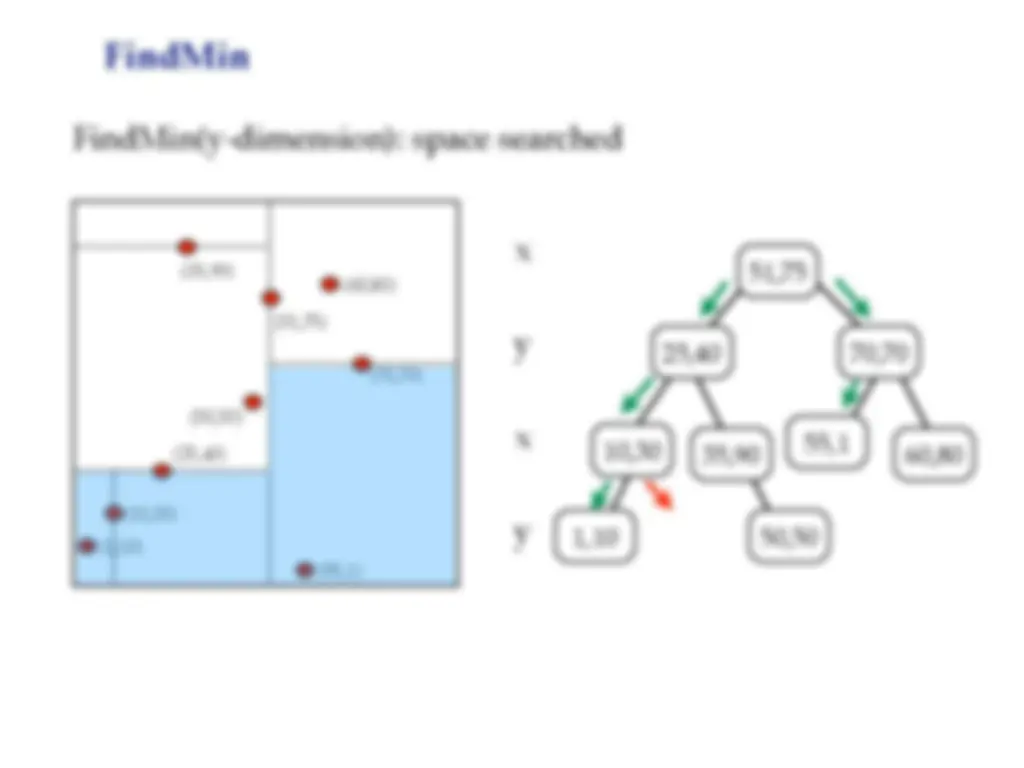
Kd-trees is a space partitioning data structure invented in the 1970s by jon bentley. It is a tree-based data structure used for efficient range and nearest neighbor searches in multi-dimensional spaces. Each level of the tree compares against one dimension, and the idea is to have only two children at each node. The tree is constructed by recursively inserting points, and each node contains a point and a 'cutting dimension'. To find a point, we only compare the coordinate from the cutting dimension. The insertion, findmin, and deletion operations in kd-trees, as well as the concept of nearest neighbor searches.
Typology: Study notes
1 / 19

This page cannot be seen from the preview
Don't miss anything!
d
insert(Point x, KDNode t, int cd) { if t == null t = new KDNode(x) else if (x == t.data) // error! duplicate else if (x[cd] < t.data[cd]) t.left = insert(x, t.left, (cd+1) % DIM) else t.right = insert(x, t.right, (cd+1) % DIM) return t }
(51,75)
(25,40) (10,30) (55,1) (1,10) (70,70) (60,80) (35,90)
(50,50)
(51,75)
(25,40) (10,30) (55,1) (1,10) (70,70) (60,80) (35,90)
(50,50)
Point findmin(Node T, int dim, int cd): // empty tree if T == NULL : return NULL // T splits on the dimension we’re searching // => only visit left subtree if cd == dim: if t.left == NULL : return t.data else return findmin(T.left, dim, (cd+1)%DIM) // T splits on a different dimension // => have to search both subtrees else : return minimum( findmin(T.left, dim, (cd+1)%DIM), findmin(T.right, dim, (cd+1)%DIM) T.data )
Q (^) P
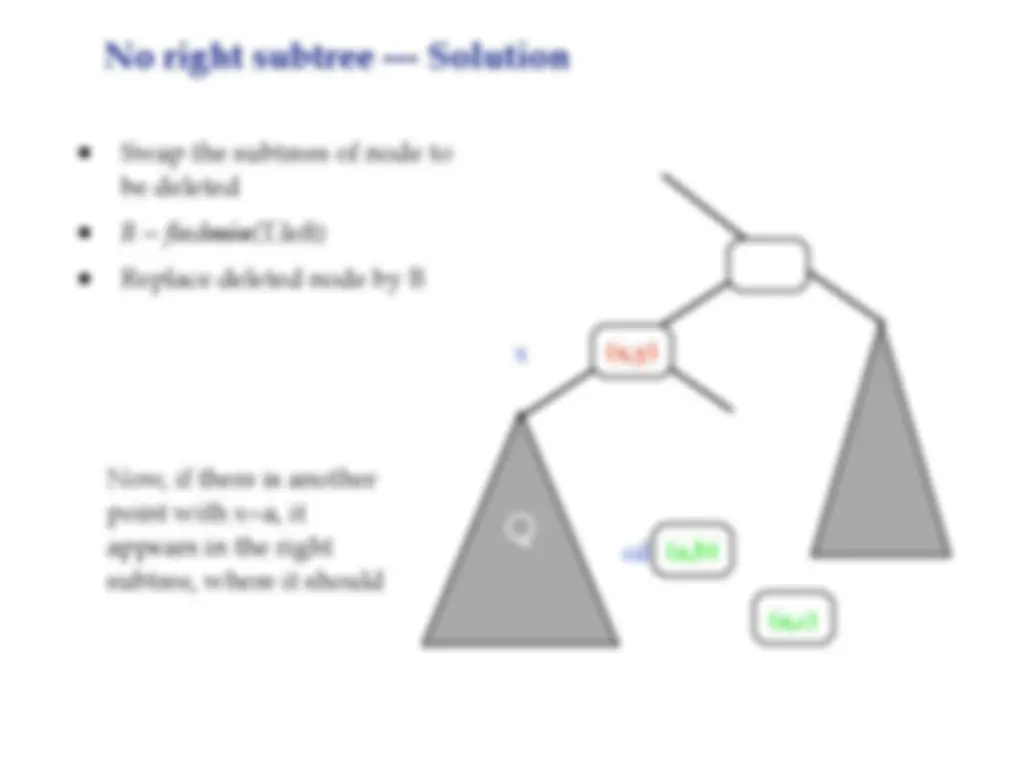
- Swap the subtrees of node to
- B = find min (T.left) - Replace deleted node by B Q
Point delete(Point x, Node T, int cd): if T == NULL : error point not found! next_cd = (cd+1)%DIM // This is the point to delete: if x = T.data: // use min(cd) from right subtree: if t.right != NULL: t.data = findmin(T.right, cd, next_cd) t.right = delete(t.data, t.right, next_cd) // swap subtrees and use min(cd) from new right: else if T.left != NULL: t.data = findmin(T.left, cd, next_cd) t.right = delete(t.data, t.left, next_cd) else t = null // we’re a leaf: just remove // this is not the point, so search for it: else if x[cd] < t.data[cd]: t.left = delete(x, t.left, next_cd) else t.right = delete(x, t.right, next_cd) return t
d
d to search around cells in that neighborhood