Download Support Vector Machines (SVMs) for Classification: Wide Margin and Misclassification and more Slides Semantics of Programming Languages in PDF only on Docsity!
Sp’
Classification
(SVMs / Kernel method)
Sp’
LP versus Quadratic programming
min cT^ x
Ax b
x 0
min xT^ Qx cT^ x
Ax b
x 0
- LP: linear constraints, linear objective function
- LP can be solved in polynomial time. - In QP, the objective function contains a quadratic form. - For +ve semindefinite Q, the QP can be solved in polynomial time
Sp’
Separating by a wider margin
- Solutions with a wider margin are better.
Maximize 2 2
, or Minimize^ ^
2 2
Sp’
Separating via misclassification
- In general, data is not linearly separable
- What if we also wanted to minimize misclassified points
- Recall that, each sample xi in our training set has the label yi {- 1,1}
- For each point i, yi(Txi- 0 ) should be positive
- Define i >= max {0, 1- yi(Txi- 0 ) }
- If i is correctly classified ( yi(Txi- 0 ) >= 1), and i = 0
- If i is incorrectly classified, or close to the boundaries i > 0
- We must minimize ii
Sp’
Reformulating the optimization
min
2
2 ^ C^ i^ i
i 0
i 1 yi T^ xi 0
Sp’
Lagrangian relaxation
L
2
C i i i i i 1 yi T^ xi 0 i i i
min^ ^
2
2 ^ C^ i^ i
i 0
i 1 yi T^ xi 0
Sp’
Substituting
L
2
C i i i i i 1 yi T^ xi 0 i i i
T
2
i i yi xi
^ i C^ i i ^ i i iyi^ 0 i i
L 1 2
i (^) j yi y (^) j xiT^ x (^) j i , j
^ i C^^ i i ^ i i iyi^ 0 i i
Sp’
- Substituting (2,3), we have the minimization problem
L 1 2
i (^) j yi y (^) j xiT^ x (^) j i , j
^ i C^^ i i ^ i i iyi^ 0 i i
min 1 2
i (^) j yi y (^) j xiT^ x (^) j i , j
i i
s. t. (^) i^ yi^ i ^0 0 i C
Sp’
The kernel method
- The SVM formulation can be solved using QP on dot-products.
- As these are wide-margin classifiers, they provide a more robust solution.
- However, the true power of SVMs approach from using ‘the kernel method’, which allows us to go to higher dimensional (and non- linear spaces)
Sp’
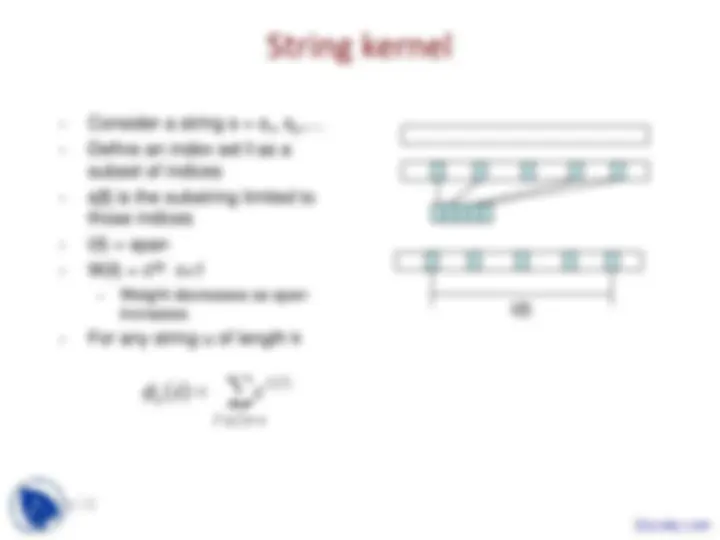
kernel
- Let X be the set of objects
- Ex: X =the set of samples in micro-arrays.
- Each object xX is a vector of gene expression values
- k: X X -> R is a positive semidefinite kernel if - k is symmetric. - k is +ve semidefinite
k ( x , x ') k ( x ', x )
cT^ kc 0 c Rp
Docsity.com
Sp’
Linear kernel is +ve semidefinite
- Recall X as a matrix, such that each column is a sample - X=[x 1 x 2 …]
- By definition, the linear kernel kL=XTX
- For any c
c
T kLc c
T X
T Xc Xc
2 0
Sp’
Generalizing kernels
- Any object can be represented by a feature vector in real space.
: X Rp
k ( x , x ') ( x )
T
( x ')
Sp’
The kernel trick
- If an algorithm for vectorial data is expressed exclusively in the form of dot-products, it can be changed to an algorithm on an arbitrary kernel - Simply replace the dot-product by the kernel
Sp’
Kernel trick example
- Consider a kernel k defined on a mapping
- It could be that is very difficult to compute explicitly, but k is easy to compute
- Suppose we define a distance function between two objects as
- How do we compute this distance?
d ( x , x ') ( x ) ( x ')
2
d ( x , x ') ( x ) ( x ') 2 ( x ) T ( x ) ( x ') T ( x ') 2 ( x ) T ( x ') k ( x , x ) k ( x ', x ') 2 k ( x , x ')