


Module 1
Introduction to ML






























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
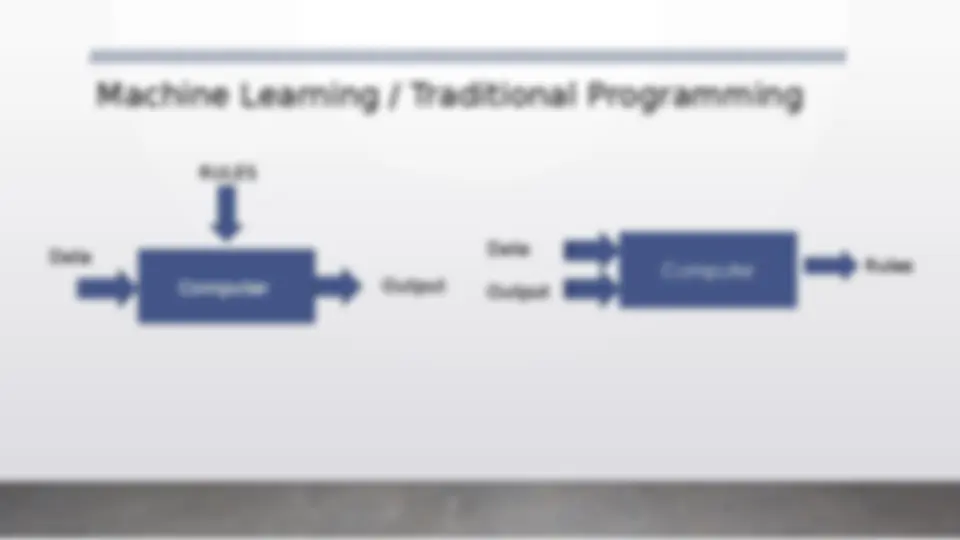
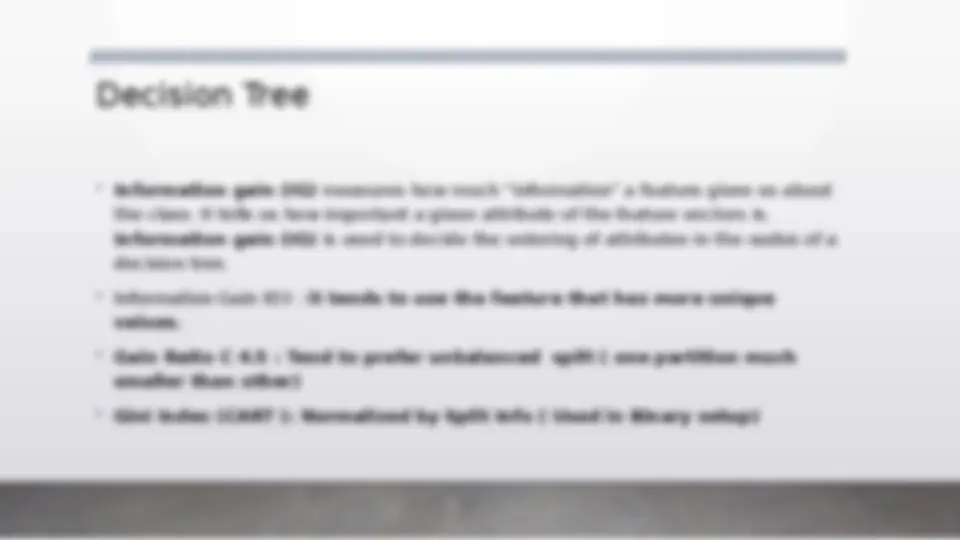
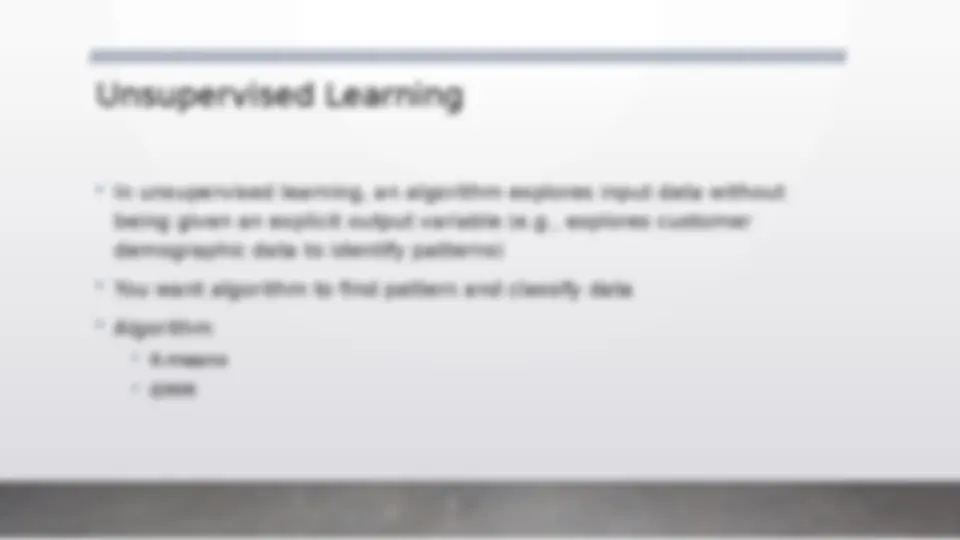
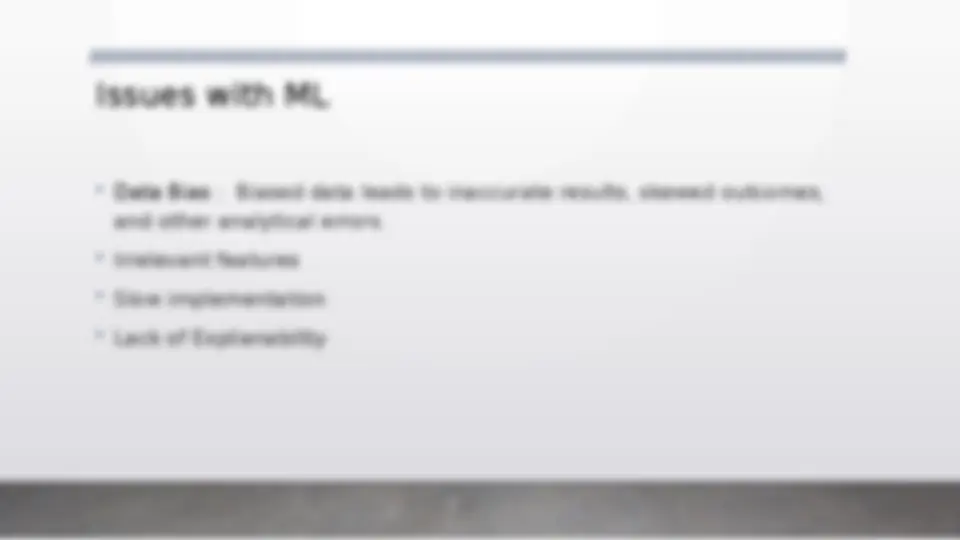
An introduction to machine learning, covering various algorithms and concepts. It explains the difference between machine learning and traditional programming, and discusses supervised and unsupervised learning techniques. The document also covers decision trees, bagging, boosting, knn, and dbscan algorithms. Additionally, it addresses issues like overfitting, underfitting, and data bias in machine learning models. The document concludes with applications of machine learning in finance, healthcare, and marketing, along with an overview of training, validation, and test datasets. It also covers bias and variance, and performance analysis using confusion matrix, precision, recall, and f score. (447 characters)
Typology: Lecture notes
1 / 47

This page cannot be seen from the preview
Don't miss anything!
Introduction to ML
Supervised learning Unsupervised learnig Input Data is provided to the model along with the output in the Supervised Learning. Only input data is provided in Unsupervised Learning. Output is predicted by the Supervised Learning. Hidden patterns in the data can be found using the unsupervised learning model. Accurate results are produced using a supervised learning model. The accuracy of results produced are less in unsupervised learning models. Training the model to predict output when a new data is provided is the objective of Supervised Learning. Finding useful insights, hidden patterns from the unknown dataset is the objective of the unsupervised learning. Computational Complexity is very complex There is less computational complexity Some of the applications of Supervised Learning are Spam detection, handwriting detection, pattern recognition, speech recognition etc. Some of the applications of Unsupervised Learning are detecting fraudulent transactions, data preprocessing etc.