



Lecture 2: MDPs
Lecture 2: Markov Decision Processes
¨
Omer Ekmekci
METU CENG
Fall 2025-2026
Adapted from David Silver’s slides
¨
Omer Ekmekci CENG7822 Reinforcement Learning Fall 2025-2026 1/41






























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Markov decision process for Reinforcement Learning
Typology: Slides
1 / 41

This page cannot be seen from the preview
Don't miss anything!
Omer Ekmekci^ ¨
METU CENG
Fall 2025-
Adapted from David Silver’s slides
1 Markov Processes
Introduction Markov Property State Transitions Markov Chain
(^2) Markov Reward Processes
Definition Return & Discounting Bellman for MRPs
3 Markov Decision Processes
Definition Policies Value Functions Bellman Expectation Optimality
(^4) Extensions to MDPs
Infinite & Continuous POMDPs Average Reward MDPs
(^5) Summary
Markov Processes
Markov Property
“The future is conditionally independent of the past given the present.”
A state St is Markov iff
P[St+1 | St ] = P[St+1 | S 1 ,... , St ].
The state captures all relevant information from the history
Once St is Markov, the full history can be discarded (sufficient statistic).
Markov Processes
State Transitions
For a Markovian state s and successor state s
′ , state transition proability is defined by
Pss′^ = P
St+1 = s
′ | St = s
State transition matrix P defines transition probabilities from all states s to all successor
states s
′ ,
to
P = from
P 11 · · · P 1 n . . .
Pn 1 · · · Pnn
where each row of the matrix sums to 1.
Markov Processes
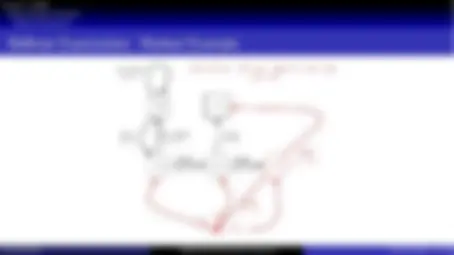
Markov Chain
C1 C2 C3 Pass Sleep
C1 FB FB C1 C2 Sleep
C1 C2 C3 Pub C2 C3 Pass Sleep
C1 FB FB C1 C2 C3 Pub C1 FB FB FB
C1 C2 C3 Pub C2 Sleep
Markov Processes
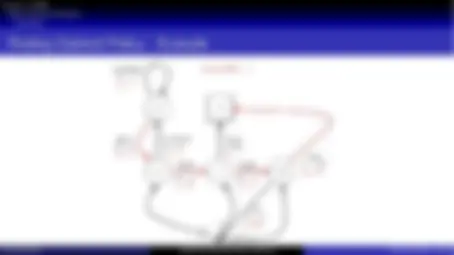
Markov Chain
C1 C2 C3 Pass Pub FB Sleep
C1 0. 5 0. 5
C2 0. 8 0. 2
C3 0. 6 0. 4
Pass 1. 0
Pub 0. 2 0. 4 0. 4
FB 0. 1 0. 9
Sleep 1
Markov Reward Processes
Definition
Markov Reward Processes
Return & Discounting
The return Gt is the total discounted reward from time-step t:
Gt = Rt+1 + γRt+2 + · · · =
k=
γ
k Rt+k+1.
The discount γ ∈ [0, 1] is the present value of future rewards.
The value of receiving reward R after k+1 time-steps is γ
k R.
This values immediate reward above delayed reward.
γ ≈ 0 leads to “myopic” evaluation.
γ ≈ 1 leads to “far-sighted” evaluation.
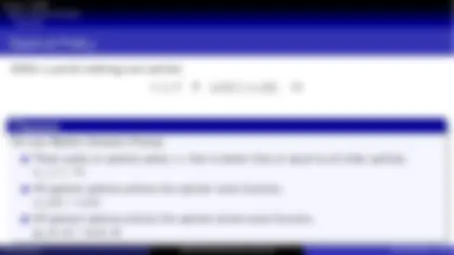
Markov Decision Processes
Definition
A Markov decision process (MDP) is a Markov reward process with decisions. It is an
environment in which all states are Markov.
A Markov Decision Process is a tuple ⟨S, A, P, R, γ⟩
S is a finite set of states
A is a finite set of actions
P is a state transition probability matrix, P
a ss′^ =^ P[^ St+1^ =^ s
′ | St = s, At = a]
R is a reward function, R
a s =^ E[^ Rt+1^ |^ St^ =^ s,^ At^ =^ a]
γ is a discount factor with γ ∈ [0, 1].
Markov Decision Processes
Definition
Markov Decision Processes
Value Functions
The state-value function vπ(s) of an MDP is the expected return starting from state s, and
then following policy π:
vπ(s) = Eπ[ Gt | St = s].
The action-value function qπ(s, a) is the expected return starting from state s, taking action a,
and then following policy π:
qπ(s, a) = Eπ[ Gt | St = s, At = a].
Markov Decision Processes
Value Functions
Markov Decision Processes
Bellman Expectation
π
π
Markov Decision Processes
Bellman Expectation
π
π