Download Math 407, Machine Learning: Practice Midterm and more Exams Machine Learning in PDF only on Docsity!
Machine Learning: Practice Midterm, Spring 2018
Name:_________________________________________________________________________________
Instructions
You may use the following resources on the midterm:
1. your filled in "methods" table with the accompanying notation page,
2. a single page of notes (8.5 by 11in),
3. a calculator.
In this exam, you will use the methods of (statistical) machine learning to solve two prediction problems.
The first problem is to predict the energy consumption of applicances in a certain house and the second is
to predict whether or not a particular office is occupied. Both datasets are from the UCI Machine Learning
Repository.
Please note that this exam is longer than I expect you to be able to do in 50 minutes. The actual midterm
will have a subset of the questions that are on this practice exam, possibly applied to different datasets.
Prediction Problem 1: Energy Consumption
Problem Description:
The goal is to predict the energy consumption (in watts) of appliances in a certain house. Here is a
description of the dataset by the authors:
Data was collected every 10 min for about 4.5 months. The house temperature and humidity conditions were
monitored with a ZigBee wireless sensor network. Each wireless node transmitted the temperature and
humidity conditions around 3.3 min. Then, the wireless data was averaged for 10 minutes periods. The
energy data was logged every 10 minutes with m-bus energy meters. Weather from the nearest airport
weather station (Chievres Airport, Belgium) was downloaded from a public data set from Reliable Prognosis
(rp5.ru), and merged together with the experimental data sets using the date and time column.
Here is a list of the variable names in the dataset:
date time, year-month-day
hour:minute:second
Appliances, energy use in Wh
T1, Temperature in kitchen area, in
Celsius
RH_1, Humidity in kitchen area, in %
T2, Temperature in living room area, in
Celsius
RH_2, Humidity in living room area, in %
T3, Temperature in laundry room area
RH_3, Humidity in laundry room area, in
T4, Temperature in office room, in Celsius
RH_4, Humidity in office room, in %
T5, Temperature in bathroom, in Celsius
RH_5, Humidity in bathroom, in %
T6, Temperature outside the building
(north side), in Celsius
RH_6, Humidity outside the building
(north side), in %
T7, Temperature in ironing room , in
Celsius
RH_7, Humidity in ironing room, in %
T8, Temperature in teenager room 2, in
Celsius
RH_8, Humidity in teenager room 2, in %
T9, Temperature in parents room, in
Celsius
RH_9, Humidity in parents room, in %
To, Temperature outside (from Chievres
weather station), in Celsius
Pressure (from Chievres weather station),
in mm Hg
RH_out-Humidity outside (from Chievres
weather station), in %
Wind speed (from Chievres weather
station), in m/s
Visibility (from Chievres weather station),
in km -Tdewpoint (from Chievres weather
station), in Celsius
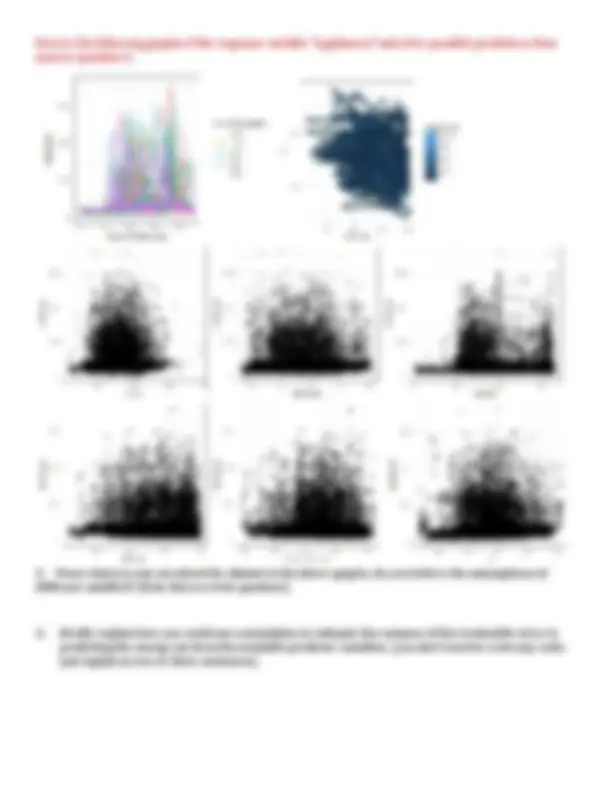
Review the following graphs of the response variable “Appliances” and a few possible predictors, then
answer question 5.
5. From what you can see about the dataset in the above graphs, do you believe the assumptions of
kNNs are satisfied? (Hint: this is a trick question!)
6. Briefly explain how you could use a simulation to estimate the variance of the irreducible error in
predicting the energy use from the available predictor variables. (you don’t need to write any code,
just explain in two or three sentences).
7. The code snippet below shows kNN being trained and tested for k=1,2,...,15. Use the resulting output
to choose the best value of k to use.
I choose k=_________________________
# choose a test set set.seed ( 11 ) samp<- sample ( 1 : nrow (dd), round (. 1 * nrow (dd)), replace=TRUE) # use the following 25 variables as predictors in kNN pnames<- c ("T1", "RH_1","T2", "RH_2", "T3", "RH_3", "T4", "RH_4","T5", "RH_5", "T6","RH_6","T7","RH_7","T8", "RH_8","T9","RH_9","T_out", "Press_mm_hg", "RH_out", "Windspeed", "Visibility", "Tdewpoint","hour") # storage for mean absolute error of kNN for 15 different k's MAEk<- numeric ( 15 ) # train kNN for(k in 1 : 15 ) { knnk<-FNN:: knn.reg (train=dd[-samp,pnames], test=dd[samp,pnames], y=dd[-samp,"Appliances"], k=k) y<-dd[samp,"Appliances"] errork<-(y-knnk$pred) MAEk[k]<- mean ( abs (errork)) } plot ( 1 : 15 , MAEk, main="Mean Absolue Error of kNN on test set", xlab="k", ylab="Mean Absolute Error", type='l', xlim= c ( 1 , 15 ))
8. What (if anything) could we try to improve the performance of kNNs?
The linear regression model shown on the previous page has an MAE of 52.75, which is worse than the
best kNN model. One advantage of a linear regression over kNN is that the model is more interpretable.
9. Use the table of model coefficients in the R output and the location codes to determine:
a) which location has the largest predicted increase in energy use of the appliances for an increase of
one degree Celsius (T), if all other variables in the model are held constant?
Location: ________________________________________
b) which location has the largest reduction in predicted energy use of the appliances for an increase of
1% in relative humidity (RH), if all other variables in the model are held constant?
Location:_________________________________________
10. The month each measurement was recorded was included in the linear regression model as a
qualitative variable with categories "Jan", "Feb", "Mar", "Apr" and "May". The category "Jan" was
used as the baseline and the model coefficients under "MonthFeb", "MonthMar", "MonthApr" and
"MonthMay" correspond to the difference between the baseline "Jan" and the months of "Feb",
"Mar", "Apr" and "May". Thus the predicted energy use of appliances in Febuary may be found by
adding the intercept ("Intercept") to the coefficient of "MonthFeb".
Which month has the lowest predicted energy use by appliances, if all other variables in the model
are held constant?
Month:___________________________________________
11. Besides adding more predictor variables, what (if anything) could you try changing about the linear
regression model to improve it's performance?
12. The linear regression model had an estimated test MSE of 9628.81. Do you expect that the MSE of
the training set for the model is larger, smaller or exactly the same as the MSE of the test set?
Circle one: larger smaller exactly the same
13. The test MSE of the linear regression model was higher than the test MSE of the best kNN model. Do
you expect that the higher MSE is a result of more bias, a higher variance in model fits or a higher
variance of the irreducible error?
Circle one: bias variance in model fits variance of the irreducible error
Prediction Problem 2: Office Occupancy
Is a particular office occupied or not? To answer this question, the following variables were collected
every minute in the office for about two weeks:
date time year-month-day hour:minute:second
Temperature, in Celsius
Relative Humidity, %
Light, in Lux
CO2, in ppm
Humidity Ratio, Derived quantity from temperature and relative humidity, in kgwater-vapor/kg-
air
Occupancy, ("Empty" or "Occupied").
The dataset was broken into three parts, a training set and two test sets.
1. Which methods from class are appropriate to try when the predicting a binary response variable
such as "Occupancy" using four predictor variables such as "time of day" (hour), "light" (Lux), "CO2"
(ppm) and "humidity ratio" (kgwater-vapor/kg-air)?
2. Based on the following histograms of three predictor variables by occupancy, do you expect that
either LDA or QDA will work well to predict whether or not the office is empty? Briefly explain.
8. Write down the prediction model from the trained logistic regression model shown in the following
R output:
model
Call: glm(formula = Occupancy ~ Light + CO2 + HumidityRatio + hour +
I(hour^2), family = "binomial", data = rr)
Coefficients:
(Intercept) Light CO2 HumidityRatio hour
- 6.746022 0.020607 0.004841 21.519182 - 0.
I(hour^2)
0.
Degrees of Freedom: 8142 Total (i.e. Null); 8137 Residual
Null Deviance: 8420
Residual Deviance: 1045 AIC: 1057
9. Use above R output from logistic regression to compute the odds ratio of the office being occupied
for a one Lux increase in the amount of light detected.
10. Briefly describe how 5-fold cross validation could have been used to select the best model instead of
a single training and test set. You don’t need to write code, just explain the idea in a sentence or two.