



Memory: Set-Associative $CSCE430/830
Memory Hierarchy: Set-Associative Cache
CSCE430/830 Computer Architecture
Lecturer: Prof. Hong Jiang
Courtesy of Yifeng Zhu (U. Maine)
Fall, 2006
Portions of these slides are derived from:
Dave Patterson © UCB























































































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
DEtailed solution for exercise on Memory cache
Typology: Exercises
1 / 96

This page cannot be seen from the preview
Don't miss anything!
CSCE430/830 Memory: Set-Associative $
Portions of these slides are derived from:
Dave Patterson © UCB
Execution
includes ALU and Memory instructions
MissRate MissPenalty CycleTime
Inst
MemAccess
Execution
CPUtime IC CPI
MissPenalty CycleTime
Inst
MemMisses
Execution
CPUtime IC CPI
AMAT = Average Memory Access Time
ALUOps
does not include memory instructions
AMAT CycleTime
Inst
MemAccess
Inst
AluOps
CPUtime IC
AluOps
AMAT HitTime MissRate MissPenalt y
Data Data Data
Inst Inst Inst
HitTime MissRate MissPenalt y
HitTime MissRate MissPenalt y
Instruction miss cycles =IC x 2% x 40 = 0.80 x IC
Data miss cycles = IC x 36% x 4% x 40 = 0.576 x IC
CPIstall = 2 + ( 0.80 + 0.567 ) = 2 + 1.376 = 3.
IC x CPIstall x Clock period 3.
IC x CPIperfect x Clock period 2
For gcc, the frequency for all loads and stores is 36%
Instruction miss cycles = IC x 2% x 80 = 1.600 x IC
Data miss cycles = IC x 36% x 4% x 80 = 1.152 x IC
2.752 x IC
I x CPI slowClk
x Clock period 3.
I x CPI fastClk
x Clock period 4.752 x 0.
Assume: we increase the performance of the previous machine by
doubling its clock rate. Since the main memory speed is unlikely to
change, assume that the absolute time to handle a cache miss does not
change. How much faster will the machine be with the faster clock?
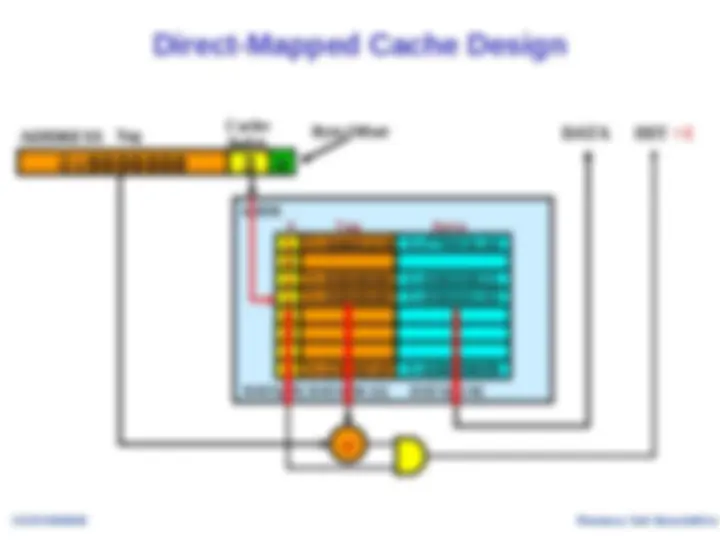
In one predetermined place - direct-mapped
Use part of address to calculate block location in cache
Compare cache block with tag to check if block present
Anywhere in cache - fully associative
Compare tag to every block in cache
In a limited set of places - set-associative
Use portion of address to calculate set (like direct-
mapped)
Place in any block in the set
Compare tag to every block in set
Hybrid of direct mapped and fully associative
***0 *4 8 C
Cache
00 04 08 0C 10 14 18 1C 20 24 28 2C 30 34 38 3C 40 44 48 4C
Memory
address maps to block:
location = (block address MOD # blocks in cache)
CSCE430/830 Memory: Set-Associative $
00001 00101 01001 01101 10001 10101 11001 11101
Cache
Memory
00 04 08 0C 10 14 18 1C 20 24 28 2C 30 34 38 3C 40 44 48 4C
Cache
Memory
arbitrary block mapping
location = any