Download Understanding Snooping Protocols & Directory-Based Approaches for Cache Coherency - Prof. and more Study notes Computer Architecture and Organization in PDF only on Docsity!
© Sudhakar Yalamanchili, Georgia Institute of Technology
Memory Coherence and Memory Coherence and
ConsistencyConsistency
Reading for this Module
• Memory Coherence
- Snooping bus protocols
- Directory protocols
- Section 6.5 and Section 6.
• Memory Consistency
- Section 6.
- Reference: Adve, S. V. and K. Gharachorloo, “ Shared
memory consistency models: A tutorial,” IEEE Computer,
December 1996, pp. 66-
ECE 4100/6100 (3)
Shared Memory Multiprocessors
- Additional processors are used to improve
performance
- We adopt a simplified model wherein each
processor executes a distinct thread
Memory
P
Memory Memory
Network
A
P
B
P
C
Cache line
code data
Registers
stack stack stack
Registers Registers
Shared Address Space
Thread 1 Thread 2 Thread 3
cache
Handling Shared Data
- Intuitively we must ensure that the most “recent”
value of a shared variable is read Æ coherency!
Memory
P
Memory
Network
A=
P2 P
A=
A=
A=
What happens to this value?
When is this value updated?
- Multiple cache copies exist during read-only sharing
cache
ECE 4100/6100 (7)
Performance Issues
- Use of memory bandwidth
- Different protocols make different demands on bandwidth
of memory and the bus
- Memory traffic
- Different protocols produce different levels of bus traffic
- Implementation complexity
- Hardware complexity of the cache state machines
- Impact on bus protocol
System Model: Snooping Protocols
- Single physical address space with uniform memory
access (UMA) times
- Basic cache operation remains unchanged
- State of a cache line indicates sharing status
- State is associated with the physical, processor cache line
and not with the contents of the line
: : : : :
: 31 0
State Bits Tag (^) Data
: : : : : : :
: 31 0
State Bits Tag (^) Data
: :
Store the state of this physical cache line
Processor 0 Processor N-
BUS
Snooping cntrler Snooping cntrler
ECE 4100/6100 (9)
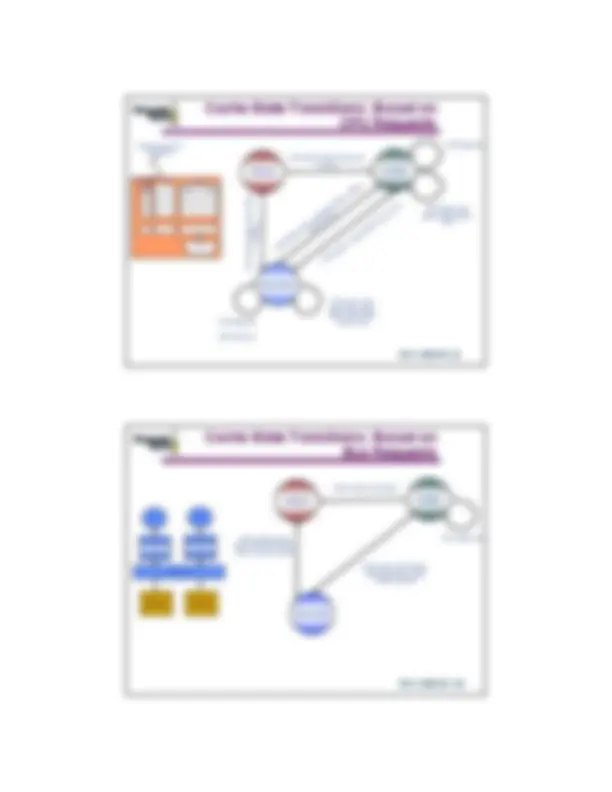
Cache State Transitions: Based on
CPU Requests
INVALID SHARED
EXCLUSIVE
CPU Read: Place read miss on bus
CPU Read hit
CPU Read miss: place read miss on bus
CPU Read miss: write-back block, place
read on bus
CPU Write: place write miss on bus
CPU Read hit
CPU Write hit
CPU write miss: write back cache block, place write miss on bus
CPU write: place write miss
on bus
: : : : :
: 31 0
Mux
State Bits Tag (^) Data
: (^) :
Invalid, shared or exclusive
Cache State Transitions: Based on
Bus Requests
INVALID SHARED
EXCLUSIVE
Write miss for this block
CPU read miss
Read miss for this block: write back block, abort memory access
Write miss for this block: write back block, abort memory access
Memory
P
Memory
Network
A
P
A
ECE 4100/6100 (13)
Implementation Issues
- In reality the preceding state transitions are not
atomic
- For example, miss, acquire the bus, and receive a
response will not in practice be atomic
- Split transaction buses introduce non-atomic operations
- Multiple coordinating entities on the same bus
- Interference between snooping and CPU accesses
- Duplicate the cache tags
- Use multi-level inclusion for L2/L3 caches
Further Optimizations
- In practice, protocols distinguish between write hits
and write misses
- Utilize the notions of invalidations and “ownership”
- Distinguish the exclusive, consistent state of the
cache line
- Let us refer to this as a clean-private state
- MESI protocol
- Allow blocks to be shared without writing back
- Distinguish shared, but dirty state.
ECE 4100/6100 (15)
A commercial protocol: MESI
Protocol
inv
Mod Exc
Sh Inv
Mod Exc
Sh
Read miss, shared
Write hit
Write miss Write hit
Write hit
Read hit
Read miss, exclusive
Snoop hit on write or Read with intent to modify
Snoop hit on read
- Industry standard, invalidation-based protocol for
SMPs
- Reading: Find a complete specification as used in
the Pentium and understand all of the transitions
Major Transitions
Scaling Multiprocessors
- A bus is a bottleneck to scaling to a large systems
- Electrical issues
- Contention issues
- Goal: scalable memory and interconnection bandwidth
- Message passing networks for scalable bandwidth
- Physically distributed memories for scalable memory bandwidth
- Problem: snooping schemes are not scalable
Memory
P
Memory Memory Memory
cache
P
cache
P
cache
P
cache
ECE 4100/6100 (19)
Using Distributed Directories
- Single physical, distributed address space with non-
uniform memory access (NUMA) times
- Basic snooping protocol state machine transitions
are preserved
P + C
Dir
Memory
P + C
Dir
Memory
P + C
Dir
Memory
P + C
Dir
Memory
Interconnection Network
Some Additional Concepts
P + C
Dir
Memory
P + C
Dir
Memory
P + C
Dir
Memory
Local node generates a memory reference Remote node has a copy of block
Home node is the physical memory location of a memory reference
Generating the request
Network
the order sent
- Directory entry indicates
state of cached blocks
and the members of the
sharing set
ECE 4100/6100 (21)
Directory Protocol Features
- The {sharing set} is the set of processors with a
copy of a memory block
- Implementation
- Bit vectors and fully mapped entries
- Linked lists
- Consistency strategy
- Shared lines always consistent with home copy
- Notification strategy
- Invalidation rather than update
The Local Processor State Machine
INVALID SHARED
EXCLUSIVE
CPU read miss
CPU read hit
Invalidate
CPU Read: send read miss msg
CPU write miss: data write back CPU write hit CPU read hit
Fetch Invalidate: data write back
CPU write: send write miss msg
CPU read miss: data write
back
Fetch; data write back
CPU write: data send write msg
P + C
Dir memory
Network
cache
: : : : :
: 31 0
State Bits Tag Data
: :
ECE 4100/6100 (25)
Example
Summary
- Performance scaling is achieved via the use of
multiple processors each working on one part of the
application
- Caching of shared data leads to the cache
coherency problem
- Essentially a synchronization problem
- Solutions depend on the scale of the system
- Small scale machines using a shared bus Æ snooping
protocols
- Large scale machines using a message passing network
Æ directory based protocols
© Sudhakar Yalamanchili, Georgia Institute of Technology
Memory Consistency Models Memory Consistency Models
Memory Consistency
• What can the programmer assume about the
servicing of memory operations?
- For example, will they occur in program order?
- Why are these assumptions important?
Network
P
P P
Memory
Memory
Memory
ECE 4100/6100 (31)
Sequential Consistency
[Lamport] “ A multiprocessor system is sequentially consistent if
the result of any execution is the same as if the operations of
all processors were executed in some sequential order, and
the operations of each individual processor appear in this
sequence in the order specified by the program ”
P
SD
LD
LD
P P
Memory
Memory references from all processors are serialized
Implications of Sequential
Consistency
- Program order requirement
- Note that memory systems may be parallel and that the network
between processors and memories may re-order instructions
- Atomicity requirement
- Informally, a write takes place instantaneously with respect to the
ability of all other processors to read it
P
Memory
P P
Memory Memory Memory
P
Network
Reference: Adve, S. V. and K. Gharachorloo, “ Shared memory consistency models: A tutorial,” IEEE Computer, December 1996, pp. 66-
ECE 4100/6100 (33)
Program Ordering Issues
- Violation of program order requirement Æ can lead
to incorrect parallel programs
- Use of write buffers
- Note: Does not violate data dependence in uniprocessor
systems
- Ordering issues arise naturally in systems with
caches
- Compiler re-ordering of instructions lead violations
of sequential consistency
Atomicity Issues in the Presence of
Caches
- Consider the above example and an update based protocol
- Atomicity can be ensured by the following two conditions
- Writes completion: result of a write cannot be used until all copies have been updated/invalidated - A write must be atomic “system wide”
- Writes to a location are serialized, i.e., all processors see writes to the same location in the same order
Memory
P
Memory Memory Memory
Network
A
P
A
P
A
P
A
A= 1 A= 2
What order do P3 and P4 see the updates?
ECE 4100/6100 (37)
Relaxed Memory Models (cont.)
- Processor Consistency
- Writes by any processor are seen by all processor in the order
they were issued
- For any variable, all processors see writes in the same order
- Weaker than sequential consistency since the same ordering is not guaranteed to be see seen by all processors
- Weak Consistency
- Distinguish between data operations and synchronization
operations
- Synchronization operations are sequentially consistent
- All processors see synchronization operations in the same order
- When a synchronization operation is issued, the memory pipeline
is flushed
- All pending writes must complete before the synchronization operation executes
Relaxed Memory Models (cont.)
- Release Consistency
- Increases overlap in memory operations restricted by the
weak consistency model
- Similarity with instruction issue and dependences?
ECE 4100/6100 (39)
The Programmers View
- The use of synchronized programs
- All accesses to shared data are synchronized
- Data references are ordered by synchronization primitives
- Thus these programs are data-race free
- Outcome does not depend on the relative speed of
processors, network, and system software
- Utilize a programmer-centric view of consistency
- Do not have to reason about ordering and atomicity
constraints
- Write programs to conform to program semantics and let
the compiler and system libraries bring optimizations to
bear based on the model supported in the language
Summary
- Consistency models are a set of rules that can b
relied on by the programmer and compiler
- Consistency Models determine the system
optimizations that are possible
- Overlapping of memory operations from multiple
processors
- Many optimizations can violate consistency model
semantics
- Leads to incorrect execution
- Consistency models are distinct from coherence
- The latter is concerned with updates/invalidations to a
single shared variable
- The former is concerned with the behavior of memory
references from multiple concurrent threads