



High Performance Computing
Lecture 40
Docsity.com












Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A lecture from docsity.com on high performance computing, focusing on message passing interface (mpi). It covers the standard api, key functions and constants, making mpi programs, mpi communicators, message tags, and synchronous vs asynchronous message passing. It also introduces mpi group communication with examples of broadcast, scatter, gather, and reduce.
Typology: Slides
1 / 24

This page cannot be seen from the preview
Don't miss anything!
3 Message Passing Interface (MPI)
Hides software/hardware details Portable, flexible
Your program MPI Library Custom software Standard TCP/IP Standard network HW Custom hardware
5 Making MPI Programs
6 MPI Communicators
8 Example MPI_Comm_rank(MPI_COMM_WORLD,&myrank); if (myrank == 0) { int x; MPI_Send(&x, 1, MPI_INT, 1, msgtag, MPI_COMM_WORLD); } else if (myrank == 1) { int x; MPI_Recv(&x, 1, MPI_INT, 0,msgtag,MPI_COMM_WORLD,status); }
9 MPI Message Tag
11 MPI Message Tag
12 MPI: Matching Sends and Recvs
Flavours of Sends/Receives
14 Asynchronous Message Passing
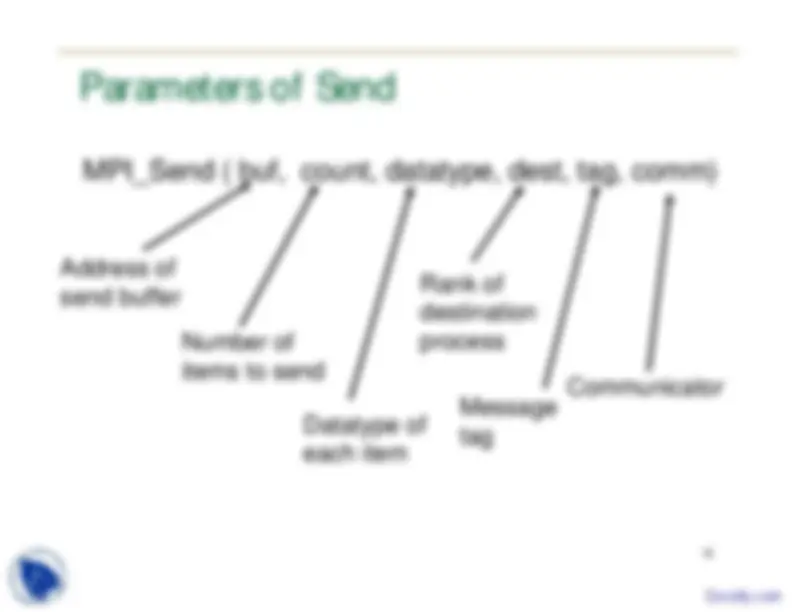
15 Parameters of Send
Address of send buffer Number of items to send Datatype of each item Rank of destination process Message tag Communicator
17 Non-blocking Routines
MPI_Wait() waits until operation completed and then returns MPI_Test() returns with flag set indicating whether or not operation has completed
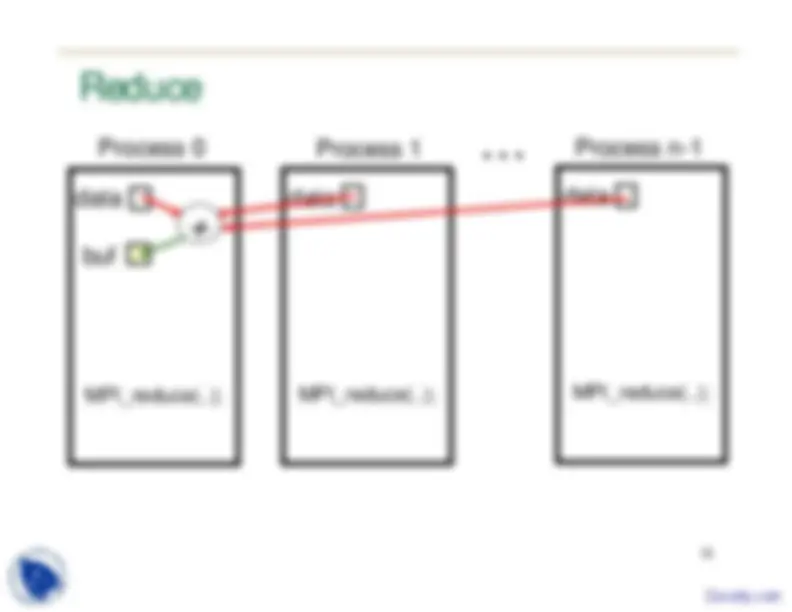
18 MPI Group Communication
Not absolutely necessary for programming More efficient than separate point-to-point routines
MPI_Bcast, MPI_Reduce, MPI_Allreduce, MPI_Alltoall, MPI_Scatter, MPI_Gather, MPI_Barrier
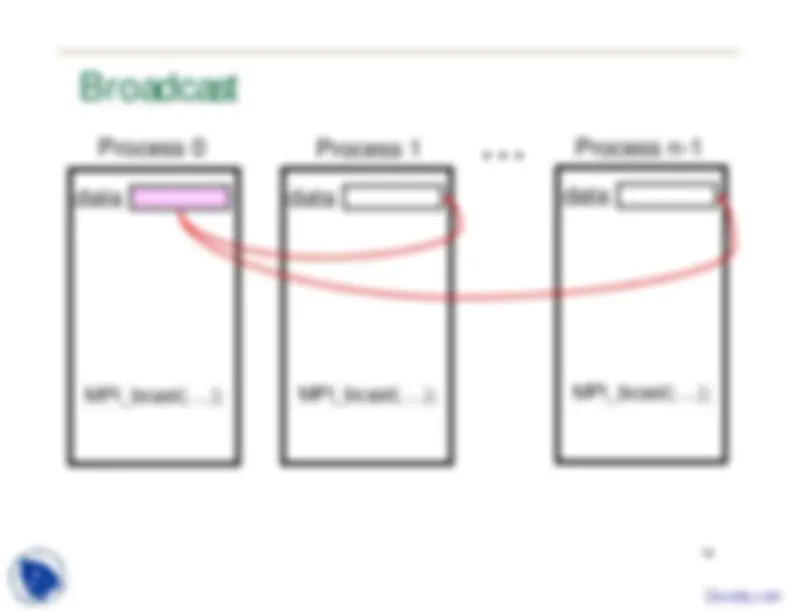
20 MPI Broadcast
21
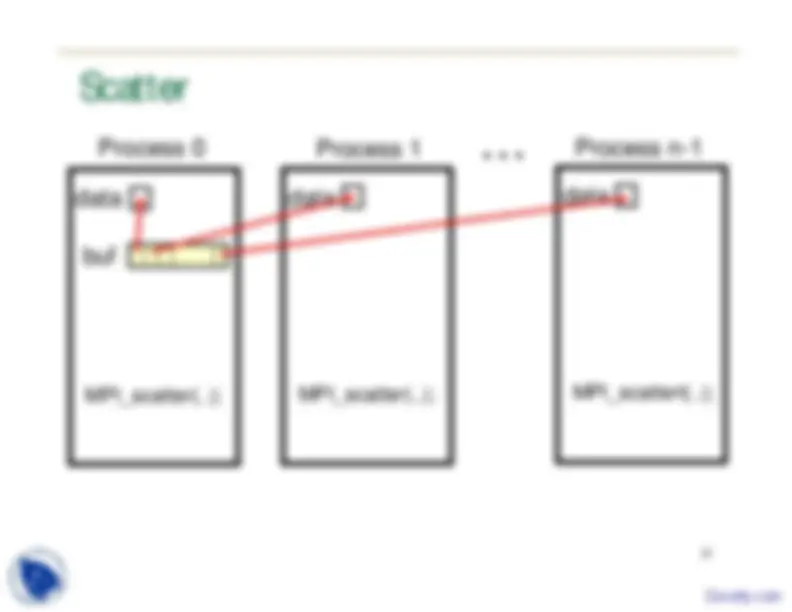
Process 0 (^) Process 1 Process n- 1 data buf MPI_scatter(..); data MPI_scatter(..); data MPI_scattert(..);