


EECS 553: Machine Learning
Lecture 15: Modern Regularization and
Optimization Methods























































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
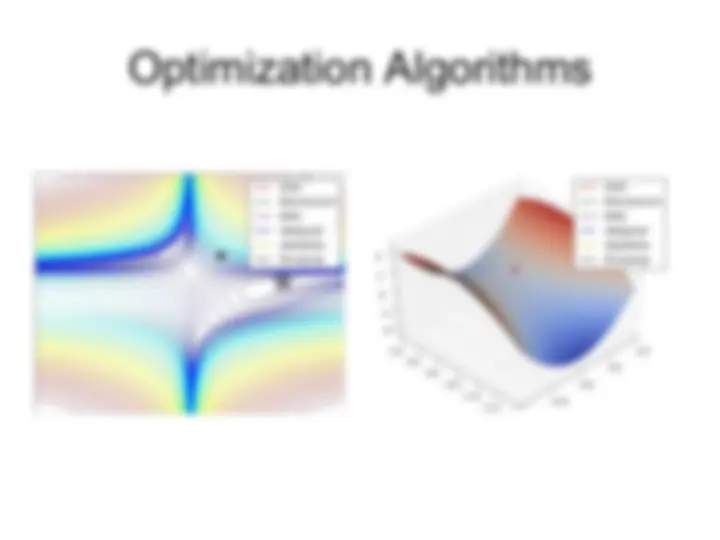
This lecture explores modern regularization and optimization methods in machine learning, focusing on deep learning techniques. It delves into the challenges of training deep convolutional neural networks (cnns) and introduces resnet, a solution to overcome optimization difficulties. The lecture then covers various regularization techniques, including max-norm, dropout, early stopping, and data augmentation, explaining their roles in preventing overfitting and improving generalization. It concludes with a discussion of optimization algorithms beyond stochastic gradient descent (sgd), including momentum, adaptive methods like adagrad, rmsprop, and adam, highlighting their advantages and applications in accelerating learning.
Typology: Slides
1 / 68

This page cannot be seen from the preview
Don't miss anything!
Lecture 15: Modern Regularization and Optimization Methods
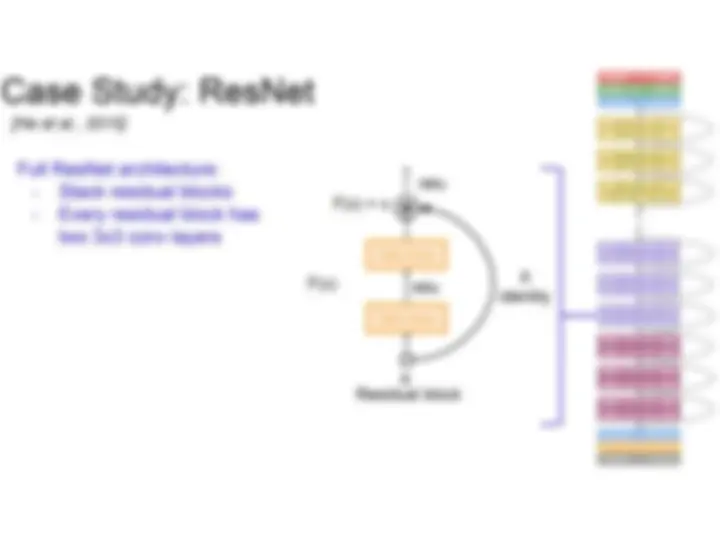
What happens when we continue stacking deeper layers on a “plain” convolutional neural network?
Q: What’s weird about these training and test curves? 56 - layer model performs worse on both training and test error
!"# $ ' ( !
!
Implication: Model weights are small Implication: Model weights are small and mostly equal to zero Loss function !(#)
Regularized empirical risk minimization ! !
&
!
& = " &
&
&