Download Computer System Analysis: Module 3 - State-Based Methods - Prof. David M. Nicol and more Lab Reports Computer Science in PDF only on Docsity!
Module 3, Slide 1
Module 3: State-Based Methods
Prof. William H. Sanders and David M. Nicol Department of Electrical and Computer Engineering and
Coordinated Science Laboratory
University of Illinois at Urbana-Champaign
[email protected]
http://www.crhc.uiuc.edu/PERFORM
Module 3, Slide 2
Availability: A Motivation for State-Based Methods
•^
Recall that
availability
quantifies the alternation between proper and improper
service.–
A
( t
) is 1 if service is proper, 0 otherwise.
–^
E
[ A
( t
)] is the probability that service is proper at time
t.
–^
A
t ) is the fraction of time the system delivers proper service during [0,
t ].
•^
For many systems, availability is a more “user-oriented” measure thanreliability.
-^
However, it is often more difficult to compute, since it must account for repairand/or replacement.
Module 3, Slide 4
State-Based Methods
•^
Availability modeling can be done with combinatorial methods, but only withthe independent repair assumption. More accurate modeling with state-basedmethods relaxes the independence assumptions.–
Failures need not be independent. Failure of one component may makeanother component more or less likely to fail.
-^
Repairs need not be independent. Repair and replacement strategies are animportant component that must be modeled in high-availability systems.
-^
High-availability systems may operate in a degraded mode. In a degradedmode, the system may deliver only a fraction of its services, and the repairprocess may start only after the system is sufficiently degraded.
•^
We use random processes to model these systems.
Module 3, Slide 5
Random Processes
Random processes are useful for characterizing the behavior of real systems.A
random process
is a collection of random variables indexed by time.
Example:
X
( t
) is a random process. Let
X
(1) be the result of tossing a die. Let
X
be the result of tossing a die plus
X
(1), and so on. Notice that time (
T
One can ask:
( ) [^
]
( )
( )
[^
]
( ) [^
]^
n
n X E
X
X
P
X
P
(^136)
(^136)
Module 3, Slide 7
Describing a Random Process
Recall that for a random variable
X
, we can use the cumulative distribution
F
X^
to
describe the random variable.In general, no such simple description exists for a random process.However, a random process can often be described succinctly in various differentways. For example, if
Y
is a random variable representing the roll of a die, and
X
( t
is the sum after
t rolls, then we can describe
X
( t
) by
X
( t
X
( t
Y
P
[ X
( t
i |
X
( t
j
] =
P
[ Y
i
j
],
or
X
( t
Y
1
Y
2
Y
, where the t
Y
’s are independent. i
Module 3, Slide 8
Classifying Random Processes: Characteristics of
T
If the number of time points defined for a random process, i.e., |
T
|, is finite or
countable (e.g., integers), then the random process is said to be a
discrete-time
random process
If |
T
| is uncountable (e.g., real numbers) then the random process is said to be a continuous-time random process
Example: Let
X
( t
) be the number of fault arrivals in a system up to time
t. Since
t^
T
is a real number,
X
( t
) is a continuous-time random process.
Module 3, Slide 10
Random Process State Spaces
If the state space
S
of a random process
X
is finite or countable
(e.g.,
S
= {1,2,3,.. .}), then
X
is said to be a
discrete-state random process
Example: Let
X
be a random process that represents the number of bad
packets received over a network.
X
is a discrete-state random process.
If the state space
S
of a random process
X
is infinite and uncountable (e.g.,
S
then
X
is said to be a
continuous-state random process
Example: Let
X
be a random process that represents the voltage on a
telephone line.
X
is a continuous-state random process.
We examine only discrete-state processes in this lecture.
Module 3, Slide 11
Stochastic-Process Classification Examples
Analog signal
A to D converter
Computeravailability
model
round-based
networkprotocolmodel
Time
State Continuous
Discrete
Discrete
Continuous
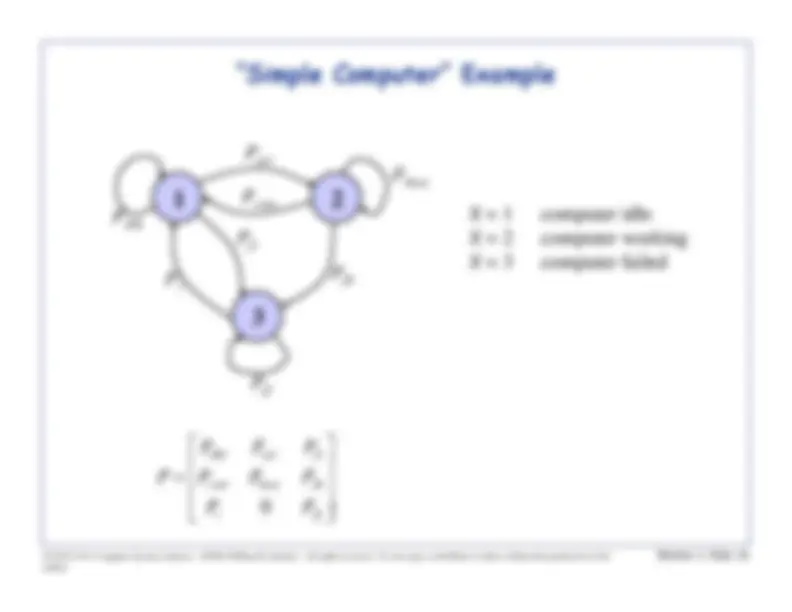
Module 3, Slide 13
Markov Chains
A
Markov chain
is a Markov process with a discrete state space.
We will always make the assumption that a Markov chain has a state space in{1,2,.. .} and that it is time-homogeneous.A Markov chain is
time-homogeneous
if its future behavior does not depend on
what time it is, only on the current state (i.e., the current value).We make this concrete by looking at a
discrete-time Markov chain
(hereafter
DTMC
). A DTMC
X
has the following property:
(^
)^
( )
(^
)^
(^
)^
(^
)
[^
]
(^
)^
( )
[^
]
(^ ) k ij
O
t
t
P
i t Xj
k t X P
n O X n t X n t X i t X j k t X P
−
−^
,^
2
1
Module 3, Slide 14
DTMCs
Notice that given
i ,^ j
, and
k
,^
is a number!
can be interpreted as the probability that if
X
has value
i , then after
k
time-steps,
X
will have value
j
Frequently, we write
to mean
(^
) k Pij
(^
) k Pij
P^ ij
(^ )
P^ ij
Module 3, Slide 16
DTMCs
Notice that given
i ,^ j
, and
k
,^
is a number!
can be interpreted as the probability that if
X
has value
i , then after
k
time-steps,
X
will have value
j
Frequently, we write
to mean
(^
) k Pij
(^
) k Pij
P^ ij
(^ )
P^ ij
Module 3, Slide 17
State Occupancy Probability Vector
Let
π
be a row vector. We denote
π
to be the i
i -th element of the vector. If
π
is a
state occupancy probability
vector, then
π
( ki
) is the probability that a DTMC has
value
i (or is in state
i ) at time-step
k
Assume that a DTMC
X
has a state-space size of
n
, i.e.,
S
n
}. We say
formally
π
( ki
P
[ X
( k
i
]
Note that
for all times
k
1
π
n ∑= i
i^
k
Module 3, Slide 19
Transition Probability Matrix
Notice that this resembles vector-matrix multiplication.In fact, if we arrange the matrix
P
P
}, that is, if ij
P
then
p
ij^
P
, and ij
π
π
P
, where
π
(0) and
π
(1) are row vectors, and
π
P
is a
vector-matrix multiplication.The important consequence of this is that we can easily specify a DTMC in terms ofan occupancy probability vector
π
and a transition probability matrix
P
all for
holds
which,
have We
1
j
P
n i
ij
i
j^
π
=
π
p^ 1n
p^11 p^ n
p^ nn
Module 3, Slide 20
Transient Behavior of Discrete-Time Markov Chains
Given
π
(0) and
P
, how can we compute
π
( k
We can generalize from earlier that
π ( k
)^
π
( k
P
Also, we can write
π
( k
π
( k
P
, and so
π ( k
)^
= [
π ( k
P
] P
π
( k
P
2
Similarly,
π
( k
π
( k
P
, and so
π ( k
)^
= [
π ( k
P
] P
2
π
( k
P
3
By repeating this, it should be easy to see that
π ( k
)^
π
P
k