



More Linked Lists
Docsity.com



















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Various types of linked lists, including singly linked lists, circular linked lists, and doubly linked lists. It also covers hash tables and their collision strategies, such as linear probing and chaining. Examples and explanations of how these data structures work and their respective advantages and disadvantages.
Typology: Slides
1 / 27

This page cannot be seen from the preview
Don't miss anything!
first?^9 17 22 26 34?
Not very common
Each node in a circular linked list has a predecessor (and a successor), provided that the list is nonempty.
insertion and deletion do not require special consideration of the first node. This is a good implementation for a linked queue or for any problem in
last (^) 9 17 22 26 34
Docsity.com
Circularly Linked Lists
Traversal must be modified: avoid an infinite loop by looking for the end of list as signalled by a null pointer.
Like other methods, deletion must also be slightly modified.
Deleting the last node is signalled when the node deleted points to itself.
if (first == 0) // list is empty
// Signal that the list is empty
else
{
ptr = predptr->next; // hold node for deletion if (ptr == predptr) // one-node list first = 0; else // list with 2 or more nodes predptr->next = ptr->next;
delete ptr;
} Docsity.com
last
L^ prev
first
mySize (^5)
next
e.g., §9.4 BigInt
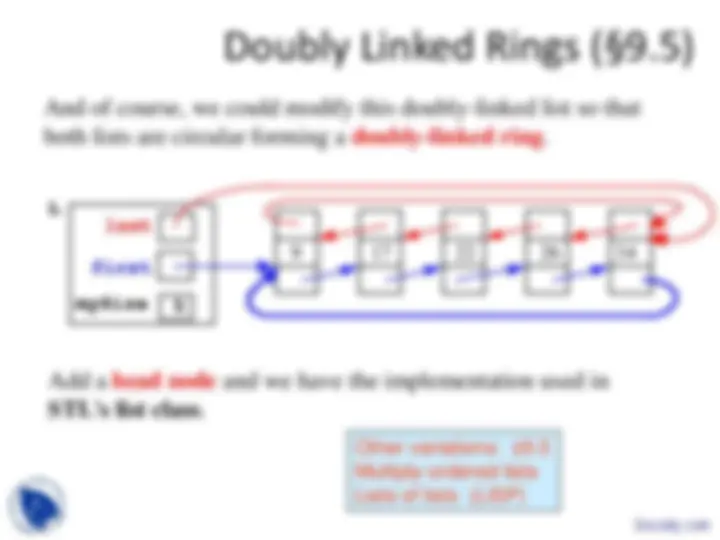
Doubly Linked Lists (§9.4)
first mySize (^5)
last 9 17 22 26 34
Other variations: §9. Multiply-ordered lists Lists of lists (LISP)
L
first mySize (^5)
last (^917 22 26 )
p r e v
n e x t
d a t a
Given up to 25 integers in the range 0 through 999 to be stored in a hash table.
This hash table can be implemented as an integer array table in which each array element is initialized with some dummy value, such as - 1.
If we use each integer i in the set as an index, that is, if we store i in table [ i ], then to determine whether a particular integer number has been stored, we need only check if table [ number ] is equal to number.
The hash function then is h ( i ) = i
The hash function in the previous example works perfectly because the time required to search the table for a given value is constant; only one location needs to be examined.
This hash function then is very time efficient, but it is surely not space-efficient.
Only 25 of the 1000 available locations are used to store items, leaving 975 unused locations; only 2.5 percent of the available space is used, and so 97.5 percent is wasted!
Because it is possible to store 25 values in 25 locations, we might try improving space utilization by using an array table with capacity 25.
Modified hash function h ( i ) = i modulo 25 addresses the space problem
// C++ syntax,
int h(int i)
{ return i % 25;}
But what about placing 77? h (77) = 77 % 25 = 2
Collision!!
Other values may collide at a given position: for example, all integers of the form 25 k + 2 hash to location 2.
Some strategy is needed to resolve such collisions:
linear probing : linear search of the table from location of collision until an empty slot is found in which the item can be stored. When 77 collides with 52 at location 2, put 77 in position 3
INDEX VALUE 0 500 1 - 2 52 3 77 4 129 5 102 … 23 273 24 49
To insert 102, we follow the probe sequence consisting of locations 2, 3, 4, and 5 to find the first available location and thus store 102 in table [5].
Chaining: use a hash table that is an array (or vector) of linked lists to store the items.
For example, to store names "alphabetically", use an array table of 26 linked lists, initially empty, and the simple hash function h ( name ) = name [0] - ‘A’;
that is, h ( name ) is 0 if name [0] is ‘A’,
1 if name [0] is ‘B’,... , 25 if name [0] is ‘Z’
Searching such a hash table is straightforward: apply the hash function to the item sought and then use one of the search algorithms for linked lists.
When a collision occurs, we simply insert the new item into the appropriate linked list.