Download Multi Cycle Datapath - Lecture Slides | CDA 4150 and more Assignments Computer Architecture and Organization in PDF only on Docsity!
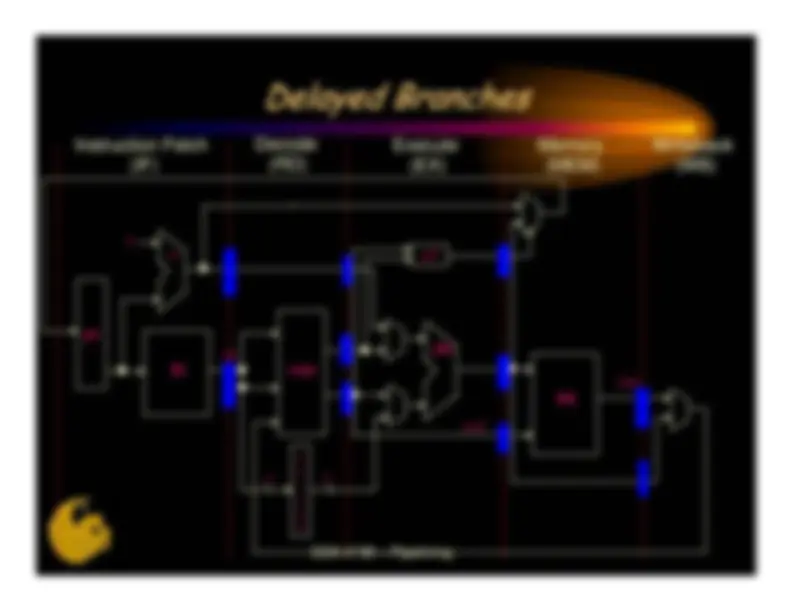
Single-Cycle implementation has poor performance•^ Cycle time longer than necessary for all but slowest instruction Solution: break the instruction into smaller steps•^ Execute each step in one clock cycle^ •^ Cycle time: time it takes to execute the longest step^ •^ Design all the steps to have similar length Advantages of the multiple cycle processor•^ Cycle time is much shorter^ •^ Functional units can be used > once/instruction (less HW) Disadvantages of the multiple cycle processor•^ More timing paths to analyze and tune^ •^ Additional registers to store intermediate data valuesCDA 4150 – Pipelining
pc^ I$ CDA 4150 – Pipelining
D$
4^ +^ =?^ alu^ IR^ regs^ smd^ e x^3216 t e n d
lmd
Decode Instruction Fetch(RD)(IF)
ExecuteMemory^ Writeback(EX)(MEM)
(WB)
We can execute multiple instructions at the same time!Each instruction will be in a different phase of executionThroughput will increase by the number of pipeline stagesOverlap different steps for consecutive instructions•^ Steps are called^ pipeline stages^ •^ Need latches after each stage to hold control/data for later stages A new instruction enters the pipeline at IF on each clock•^ Takes 5 clocks to complete execution and leave the pipeline^ •^ Potential throughput of 1 CPICDA 4150 – Pipelining
Instruction^ Clock Cycle => I^ IF^ RDEXMEMWBI^ I^ I^ I^ I I+1^ IF^ RDEXMEMWBI+1^ I+1^ I+1^ I+1^ I+1 I+2^ IF^ RDEXMEMI+2^ I+2^ I+2^ I+2^ CDA 4150 – Pipelining
WB^ I+
I+^
IF^ RDEXMEM^ I+3^ I+3^ I+3^ I+
WB^ I+
I+^
IF^ RDEX^ MEM^ I+4^ I+4^ I+4^ I+
Like assembly lines in manufacturing
4^ +^ =? pc^ alu^ IR^ regs^ I$^ D$^ smd^ e x^3216 t e n d CDA 4150 – Pipelining
lmd
Decode Instruction Fetch(RD)(IF)
ExecuteMemory(EX)(MEM)
Writeback(WB)
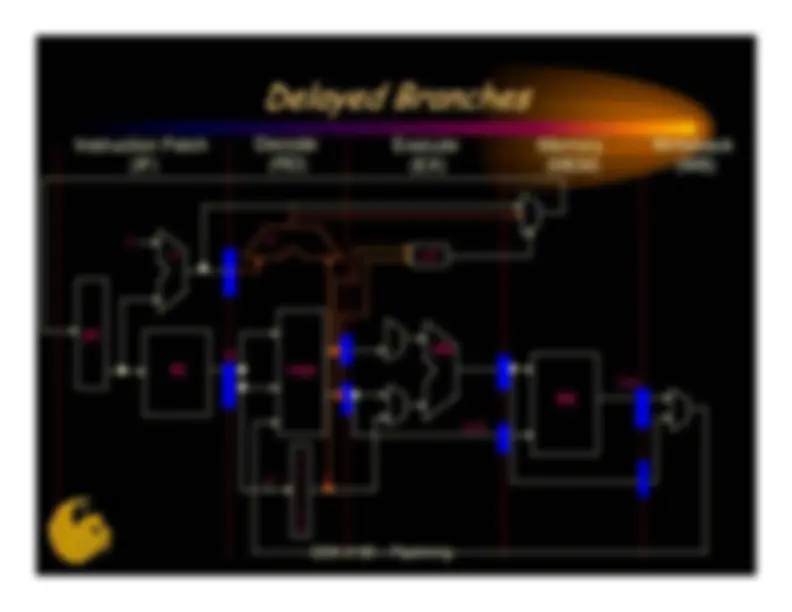
The major hurdle of pipelining•^ Situations where next instruction cannot execute^ •^ Reduce the performance of pipelining Speedup = Pipeline depth/(1 + pipeline stalls/inst)Want incredibly long pipelines, with no pipelinestallsGood luck!Long pipes increase likelihood of hazards•^ Let’s look at pipeline resources used by instructionclassCDA 4150 – Pipelining
Three classes of hazards•^ Data hazards^ –^ One instruction has a source operand that is the result of aprevious instruction in the pipeline (Read-After Write: RAW)^ –^ There are other types of data hazards (later)^ •^ Control hazards^ –^ The execution of an instruction depends on the resolution of aprevious branch instruction in the pipeline^ –^ Becomes a big problem with deep pipelines^ •^ Structural hazards^ –^ Two or more Instructions in the pipeline require the samehardware resource to progress^ –^ Most common instance is non-pipelined FU (multiplier)CDA 4150 – Pipelining
In MIPS R3000 pipeline, a data dependency occurswhen an instruction’s source register is thedestination register for either of the 2 priorinstructions•^ The simplest way to handle this is to stall thedependent instruction at RD until the required registerhas been written back^ •^ This would cause a 2-clock delay when theinstructions are consecutive^ Instruction^ Clock Cycle =>^ add^ $r3,$r1,$r2^ IF^ RD^ EX^ MEM^ WB sub^ $r5,$r3,$r4^ IF^ RD^ RD^ RD^ CDA 4150 – Pipelining
EX^ MEM^ WB
4^ +^ =? pc^ alu^ IR^ regs^ I$^ D$^ smd^ e x^3216 t e n d CDA 4150 – Pipelining
lmd
Decode Instruction Fetch(RD)(IF)
ExecuteMemory(EX)(MEM)
Writeback(WB)
add r1,r2,r3 add r4,r1,r
4^ +^ =? pc^ alu^ IR^ regs^ I$^ D$^ smd^ e x^3216 t e n d CDA 4150 – Pipelining
lmd
Decode Instruction Fetch(RD)(IF)
ExecuteMemory(EX)(MEM)
Writeback(WB)
add r1,r2,r3 add r4,r1,r5^ add r6,r4,r
4^ +^ =? pc^ alu^ IR^ regs^ I$^ D$^ smd^ e x^3216 t e n d CDA 4150 – Pipelining
lmd
Decode Instruction Fetch(RD)(IF)
ExecuteMemory(EX)(MEM)
Writeback(WB)
add r1,r2,r3 add r4,r1,r5^ add r6,r4,r1^ …
Performance can be improved by^ forwarding CDA 4150 – Pipelining
( bypassing ) a
result from a later stage to an earlier stage•^ The result of an ALU instruction is known at the end of EX^ •^ The result of a Load instruction is known at the end of MEM There is no delay when an ALU instruction executesThere is 1 clock delay when a Load instruction is directlyfollowed by a dependent instruction•^ The Load instruction is said to have a
latency^ of 2 clocks
Instruction^ Clock Cycle => add^ $t3,$t1,$t2^ IF^
RD^ EX^ MEM^ WB
sub^ $t5,$t3,$t^
IF^ RD^ EX^ MEM^ WB
lw^ $s1,0($t3)^
IF^ RD^ EX^ MEM^ WB
addi^ $s2,$s1,^
IF^ RD^ RD^ EX^ MEM^ WB
4^ +^ =? pc^ alu^ IR^ regs^ I$^ D$^ smd^ e x^3216 t e n d CDA 4150 – Pipelining
lmd
Decode Instruction Fetch(RD)(IF)
ExecuteMemory(EX)(MEM)
Writeback(WB)
add r1,r2,r3 add r4,r1,r5^ add r6,r4,r1^ …
Mem to ALU bypass ALU bypass
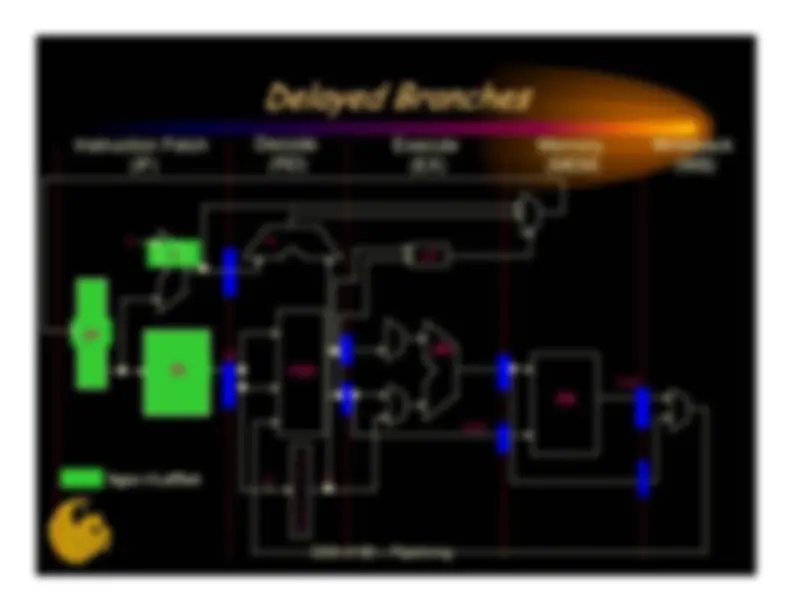
When a branch instruction is executed, execution ofsubsequent instructions depends on whether the branchis taken and the location of the destinationA simple, but effective approach is to assume the branch isnot taken and follow the sequential pathThe branch is resolved at the end of EX•^ If taken, cancel instructions in the sequential path and startfetching from the destination on the next clock^ –^ this results in a 2-clock delay for taken branches^ •^ If not taken, continue sequentially^ Instruction^ Clock Cycle =>^ I^ IF^ RD^ EX^ MEM^ WB^1 beq^ $t0,$t1,L1^ IF^ RD^ EX^ MEM^ CDA 4150 – Pipelining
WB
I^ IF^3
RD^ --^ --
I^4
IF^ --^ --
L1:^ I^5
IF^ RD