Download Sociologists' Regression Analysis: Least-Squares, Inference, Assumptions and more Slides Statistics in PDF only on Docsity!
Soci708 – Statistics for Sociologists
Module 11 – Multiple Regression^1
François Nielsen
University of North Carolina Chapel Hill
Fall 2009
(^1) Adapted from slides for the course Quantitative Methods in Sociology
(Sociology 6Z3) taught at McMaster University by Robert Andersen (now at University of Toronto)
Goals of This Module
… (^) Review of least-squares regression analysis … (^) Simple and multiple regression … (^) Slope, intercept and R^2 … (^) Standard error of the regression … (^) Inference for Regression … (^) Confidence intervals and hypothesis tests for the slope … (^) F-test for the entire regression model … (^) Assumptions of regression and how to check them
Inference in Multiple Regression (1)
… (^) At this point explain again meaning of Bk s in context of an example … (^) Remember standardized coefficients … (^) Explain R^2 and how it relates to correlation between ˆ Y and Y
Inference in Multiple Regression (2)
… (^) The standard deviation of y around the regression surface ( standard error of the regression ) is again simply estimated:
SE =
q∑ E^2 i / ( n − k − 1 )
… (^) There are n − k − 1 degrees of freedom, where n is the sample size and k is the number of slopes to estimate … (^) As in the simple regression case, SE is used to find the standard errors for each slope and CI and hypothesis are tested in exactly the same way … (^) We will not go into details regarding this here because the formulas are complicated. A computer program will calculated the SE ’s for us … (^) It is important to note, however, that we now use the t-distribution with n − k − 1 df
Analysis of Variance and F Test (1)
… (^) Recall that for the (simple or multiple) regression model
( yi − y ) = (ˆ yi − y ) + ( yi − ˆ yi )
… (^) It is an algebraic fact (that can be demonstrated) that the equality holds after one squares the deviations and sum them: ∑ ( yi − y )^2 =
(ˆ yi − y )^2 +
( yi − ˆ yi )^2
… (^) This can be written
SST = SSM + SSE
where
SST =
( yi − y )^2 (Sum of Squares Total)
SSM =
(ˆ yi − y )^2 (Sum of Squares Model)
SSE =
( yi − ˆ yi )^2 (Sum of Squares Error)
Analysis of Variance and F Test (2)
… (^) Recall that to calculate s^2 y , the sample variance of y , we divide SST by its degrees of freedom ( n − 1); likewise to calculate s^2 , the error variance, we divide SSE by its degrees of freedom ( n − k − 1 ) … (^) Each sum of squares has its degrees of freedom DF , and these add up to the total degrees of freedom DFT = ( n − 1 ):
DFT = DFM + DFE ( n − 1 ) = k + ( n − k − 1 )
… (^) For each source of variation the mean square MS is calculated as MS =
sum of squares degrees of freedom
Analysis of Variance and F Test (4)
… (^) A small P-value favors the alternative hypothesis^2
Ha : at least one of the βj is not 0
(^2) From Moore & McCabe (2006, p.689)
Analysis of Variance and F Test (5)
The Analysis of Variance (ANOVA) Table
… (^) The ANOVA table summarizes sums of squares, mean squares and the F test
ANOVA Table
Degrees Source of freedom Sum of squares Mean square F
Model k SSM =
(ˆ yi − y )^2 SSM/DFM MSM/MSE Error n − k − 1 SSE =
( yi − ˆ yi )^2 SSE/DFE
Total n − 1 SST =
( yi − y )^2 SST/DFT
Analysis of Variance and F Test (7)
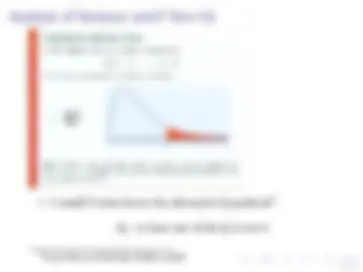
Stata output with ANOVA table for regression of depression score
. * in Stata . reg total l10inc age female cath jewi none Source | SS df MS ---------+------------------------------ Model | 2686.95106 6 447. Residual | 17554.7989 249 70. ---------+------------------------------ Total | 20241.75 255 79.
Number of obs = 256 F( 6, 249) = 6. Prob > F = 0. R-squared = 0. Adj R-squared = 0. Root MSE = 8.
Model = SSM =
∑ (ˆ yi − y )^2 Residual = SSE =
∑ ( yi − ˆ yi )^2 Total = SST =
∑ ( yi − y )^2 MS = SS/Df... What is SST/DFT = 79.379? F(6, 249) = MSM/MSE R-squared = SSM/SST Rooth MSE =
p MSE
Analysis of Variance and F Test (8)
Exercise: Can you recover the redacted figures?
. * in Stata . reg total l10inc age female cath jewi none Source | SS df MS Number of obs = 256 ---------+------------------------------ F( 6, 249) = xxxx Model | 2686.95106 xxx 447.825177 Prob > F = 0. Residual | 17554.7989 xxx 70.5012006 R-squared = xxxxxx ---------+------------------------------ Adj R-squared = 0. Total | 20241.75 255 79.3794118 Root MSE = 8.
total | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+---------------------------------------------------------------- l10inc | -6.946661 1.72227 xxxxx xxxxx -10.33874 -3. age | -.074917 .0334132 xxxxx xxxxx -.1407254 -. female | 2.559048 1.095151 2.34 0.020 .402108 4. cath | .7527141 1.440845 0.52 0.602 -2.085084 3. jewi | 4.674959 1.917259 2.44 0.015 .8988472 8. none | 3.264667 1.400731 2.33 0.021 .5058747 6. _cons | 18.24958 2.971443 6.14 0.000 12.39721 24.
Checking the Assumptions (1)
… (^) Although regression can be an effective method to summarize the relationship between quantitative variables, some assumptions must be met … (^) As with the other methods of inference we have discussed, these assumptions pertain to the population we want to make inferences about … (^) Of course, we do not have data on the whole population so cannot assess the assumptions directly … (^) We can, however, check whether the assumptions appear reasonable for the sample
Checking the Assumptions (2)
Assumptions for linear regression are:
- Linearity: … (^) Is there a linear relationship between y and x? We can assess this assumption in simple regression by looking at a scatterplot
- Constant Spread: … (^) Is the spread of the y-values approximately the same regardless of the value of x? If the spread of y changes with x , then we have a problem. A scatterplot of y and x or of the residuals against x allows us to assess this.
- Normality: … (^) Are the residuals normally distributed (is there a skew or outliers)? If not normally distributed, we have a problem. We can check this assumption using a histogram or stemplot of the residuals
Assessing Spread
> # in R > data(Prestige) > attach(Prestige) > par(pty="s") # to make square plot > mod1<-lm(prestige~education) > plot(education, mod1$residuals, xlab="Education", ylab="Residuals") > abline(h=0)
l
l l (^) l l l l
l l l
ll
l
l
l
l
l
l l
l
l
l l
l
l
l
l
l
l
l
l l l
l l l
l ll l
l
l
l ll
l
l
ll
l l l
l
l
l l
l ll l
l
l
l
l ll
l
l
l
l
l
l
l
l l l
l l
l l
l
l
l
l (^) l l l l l
l ll
l
l
l
l
l l
ll
l l
6 8 10 12 14 16
−
−
0
10
Education
Residuals
Assessing Normality
> # in R > mod1<-lm(prestige~education) > hist(mod1$residuals, main="Histogram of residuals", xlab="Residual", col="red")
Histogram of residuals
Residual
Frequency
−30 −20 −10 0 10 20
0
5
10
15
20
25