



NLP UNIT-3

















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The document contains detailed notes on the topic natural language processing in artificial intelligence. It covers basic as well as advance topics of nlp
Typology: Summaries
1 / 25

This page cannot be seen from the preview
Don't miss anything!
Science especially Artificial Intelligence (AI) that is concerned about
enabling computers to understand and process human language.
Technically, the main task of NLP would be to program computers for
analyzing and processing huge amount of natural language data.
generation.
3. Semantic Ambiguity
other words, semantic ambiguity happens when a sentence contains an ambiguous word or phrase.
Ex:“The car hit the pole while it was moving” is having semantic ambiguity because the
interpretations can be “The car, while moving, hit the pole” and “The car hit the pole while the pole
was moving”.
4. Anaphoric Ambiguity
EX: The horse ran up the hill. It was very steep. It soon got tired. Here, the anaphoric reference of “it”
in two situations cause ambiguity.
5. Pragmatic ambiguity
interpretations. In simple words, we can say that pragmatic ambiguity arises when the statement is
not specific.
Ex: “I like you too” can have multiple interpretations like I like you (just like you like me), I like you
(just like someone else dose).
NLP Phases
1. Morphological Processing
paragraphs, sentences and words. For example, a word like “uneasy” can be broken into two sub-word tokens as “un-easy”.
2. Syntax Analysis
break it up into a structure that shows the syntactic relationships between the different words. For example, the sentence like
“The school goes to the boy” would be rejected by syntax analyzer or parser.
3. Semantic Analysis
text. The text is checked for meaningfulness. For example, semantic analyzer would reject a sentence like “Hot ice-cream”.
4. Pragmatic Analysis
references obtained during the last phase (semantic analysis). For example, the sentence “Put the banana in the basket on the
shelf” can have two semantic interpretations and pragmatic analyzer will choose between these two possibilities.
5. Discourse Analysis
ambiguity that can arise when a reference to a word cannot be determined. In discourse analysis we try to remove this
ambiguity.
Morphemes, the smallest meaning-bearing units, can be divided into two types −
It is the core meaningful unit of a word. We can also say that it is the root of the word. For
example, in the word foxes, the stem is fox.
functions to the words. For example, in the word foxes, the affix is − es.
Further, affixes can also be divided into following four types −
unbuckle, un is the prefix.
-s is the suffix.
word cupful, can be pluralized as cupsful by using -s as the infix.
Types of Morphemes
2. Word Order
The order of the words would be decided by morphological parsing. Let us now see the
requirements for building a morphological parser −
The very first requirement for building a morphological parser is lexicon, which includes the
list of stems and affixes along with the basic information about them. For example, the
information like whether the stem is Noun stem or Verb stem, etc.
It is basically the model of morpheme ordering. In other sense, the model explaining which
classes of morphemes can follow other classes of morphemes inside a word. For example, the
morphotactic fact is that the English plural morpheme always follows the noun rather than
preceding it.
These spelling rules are used to model the changes occurring in a word. For example, the rule
of converting y to ie in word like city+s = cities not citys.
Syntactic Analysis
It is used to implement the task of parsing. It may be defined as the software
component designed for taking input data (text) and giving structural
representation of the input after checking for correct syntax as per formal
grammar. It also builds a data structure generally in the form of parse tree or
abstract syntax tree or other hierarchical structure.
The main roles of the parse include −
To recover from commonly occurring error so that the processing of the
remainder of program can be continued.
Types of Parsing
Derivation divides parsing into the followings two types −
symbol and then tries to transform the start symbol to the input. The most
common form of topdown parsing uses recursive procedure to process the input.
The main disadvantage of recursive descent parsing is backtracking.
2. Bottom-up Parsing
construct the parser tree up to the start symbol.
Set of Non-terminals
which further help defining the language, generated by the grammar
Set of Terminals
terminals.
Set of Productions
Every production(P) consists of non-terminals, an arrow, and terminals (the sequence of
terminals). Non-terminals are called the left side of the production and terminals are called
the right side of the production.
Start Symbol
symbol is always designated as start symbol.
one of the parts of speech to the given word. It is generally called POS tagging. In
simple words, we can say that POS tagging is a task of labelling each word in a
sentence with its appropriate part of speech. We already know that parts of
speech include nouns, verb, adverbs, adjectives, pronouns, conjunction and their
sub-categories.
tagging and Transformation based tagging.
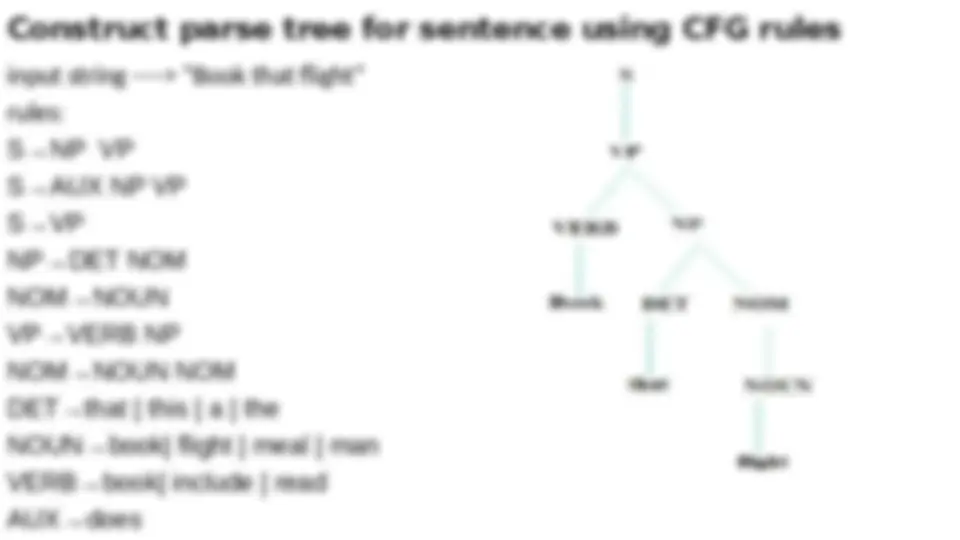
Construct parse tree for sentence using CFG rules
input string ----> “The man read this book”
rules:
S→NP VP
S→AUX NP VP
S→VP
NP→DET NOM
NOM→NOUN
VP→VERB NP
NOM→NOUN NOM
DET→that | this | a | the
NOUN→book| flight | meal | man
VERB→book| include | read
AUX→does
Construct parse tree for sentence using CFG rules
S:Sentence-->SB VP OB
SB:Subject-->PN
VP:Verb Phrase-->ADV V | V
OB:Object-->the S
s1:Subset of S--->ADJ N
PN:Proper Noun-->Ram
ADJ:Adjective-->interesting | delicious
N:Noun-->book | cake
V:Verb--->read | ate
Semantic Analysis
Elements of Semantic Analysis
1. Hyponymy & Hypernymy
It may be defined as the relationship between a generic term and instances of that
generic term. Here the generic term is called hypernym and its instances are called
hyponyms.
Ex: Dog is a hyponym of animal.
Animal is a hypernym of dog.
Ex: Purple is a hypernym of voilet and purple is a hyponym of color.
2. Homonymy
It may be defined as the words having same spelling or same form but having
different and unrelated meaning.
Ex: Give me that cricket bat.
Anu saw a bat that was sleeping on a tree.
Semantic Analysis
3. Polysemy
Polysemy is a Greek word, which means “many signs”. It is a word or phrase with
different but related sense. In other words, we can say that polysemy has the
same spelling but different and related meaning.
Ex: the word “bank” is a polysemy word having the following meanings −
A financial institution.
The building in which such an institution is located.
4. Meronymy
Ex: Coconut is a meronym of coconut tree.