


Statistical
Natural Language
Parsing
Nguyen Phuong
Thai

















































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A comprehensive overview of statistical natural language parsing, highlighting the shift from traditional symbolic grammar-based approaches to data-driven methods. It explores the role of annotated data, probabilistic context-free grammars (pcfgs), and the chomsky normal form in parsing. The document also delves into the cky parsing algorithm, a widely used technique for efficient parsing of pcfgs. It includes illustrative examples and explanations of key concepts, making it a valuable resource for students and researchers in computational linguistics and natural language processing.
Typology: Study notes
1 / 65

This page cannot be seen from the preview
Don't miss anything!
(^) LLO1: Trình bày được các kiến thức cơ bản về phân tích cú pháp bao gồm bài toán và các tiếp cận giải quyết, các mô hình văn phạm CFG và PCFG, phân tích cú pháp theo tiếp cận thống kê và treebank, đánh giá kết quả phân tích cú pháp (^) LLO2: Vận dụng được văn phạm CFG/PCFG trong mô tả cú pháp của ngôn ngữ tự nhiên như đọc hiểu dữ liệu treebank, dựng cây cú pháp thủ công, tính xác suất của cây
Phrase structure organizes words into nested constituents.
Dependency structure shows which words depend on (modify or are arguments of) which other words. The boy put the tortoise on the rug rug the the tortoise^ on put boy The
Categorical constraints can be added to grammars to limit unlikely/weird parses for sentences
We need mechanisms that allow us to find the most likely parse(s) for a sentence
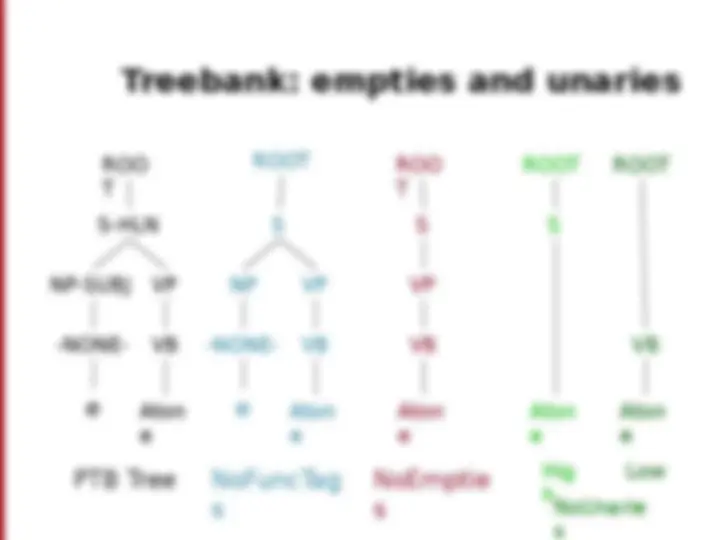
( (S (NP-SBJ (DT The) (NN move)) (VP (VBD followed) (NP (NP (DT a) (NN round)) (PP (IN of) (NP (NP (JJ similar) (NNS increases)) (PP (IN by) (NP (JJ other) (NNS lenders))) (PP (IN against) (NP (NNP Arizona) (JJ real) (NN estate) (NNS loans)))))) (, ,) (S-ADV (NP-SBJ (-NONE- *)) (VP (VBG reflecting) (NP (NP (DT a) (VBG continuing) (NN decline)) (PP-LOC (IN in) (NP (DT that) (NN market))))))) (. .))) [Marcus et al. 1993, Computational Linguistics ]
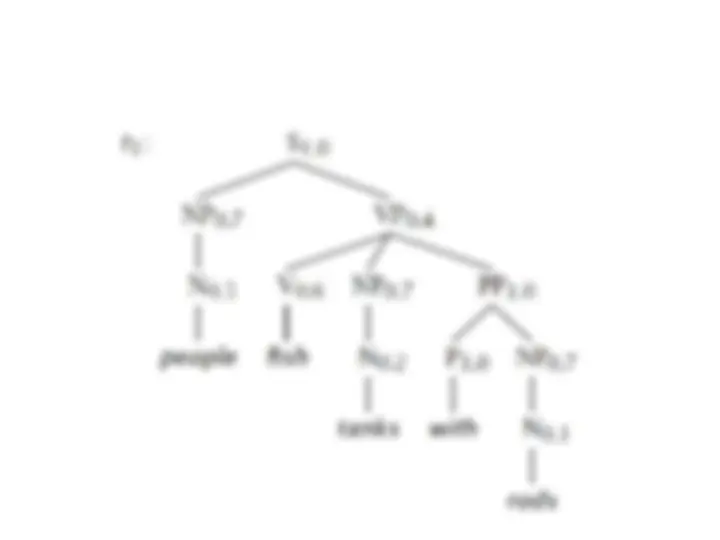
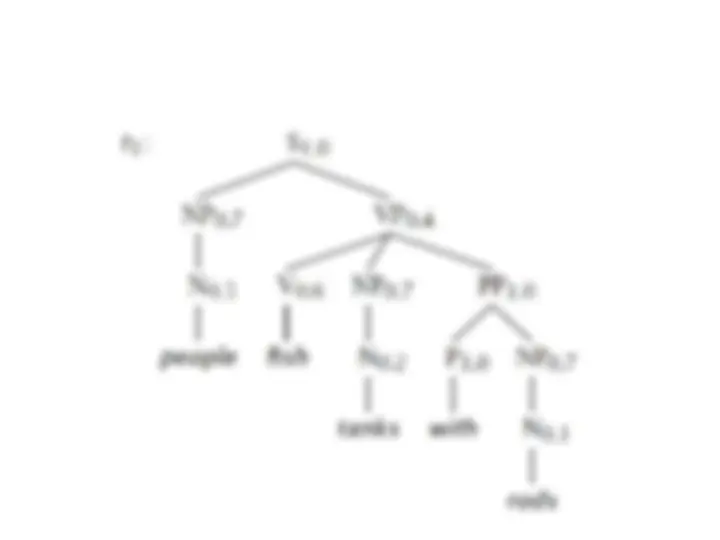
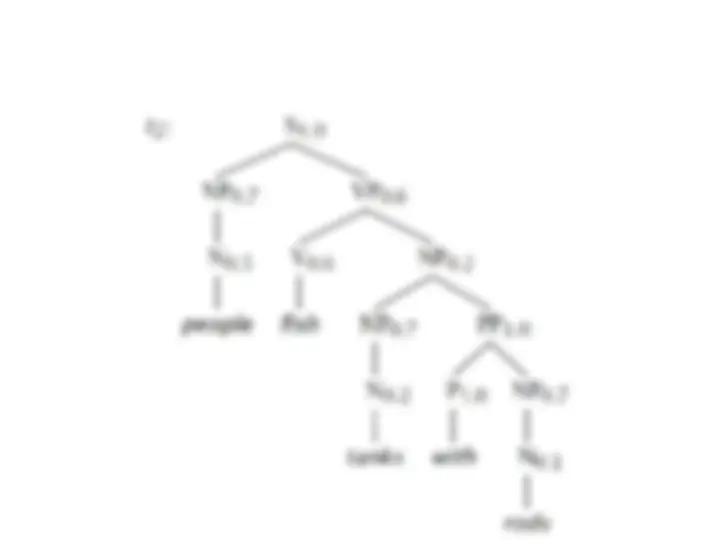
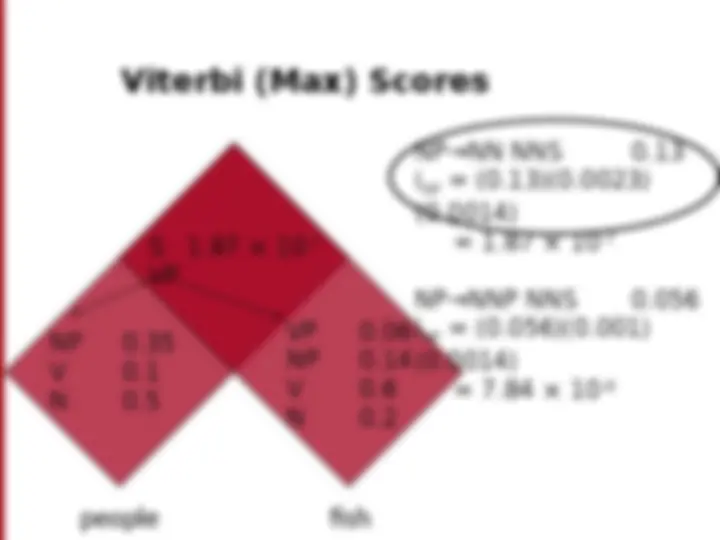
NP e PP P NP people fish tanks people fish with rods N people N fish N tanks N rods V people V fish V tanks P with
We usually write e for an empty sequence, rather than nothing
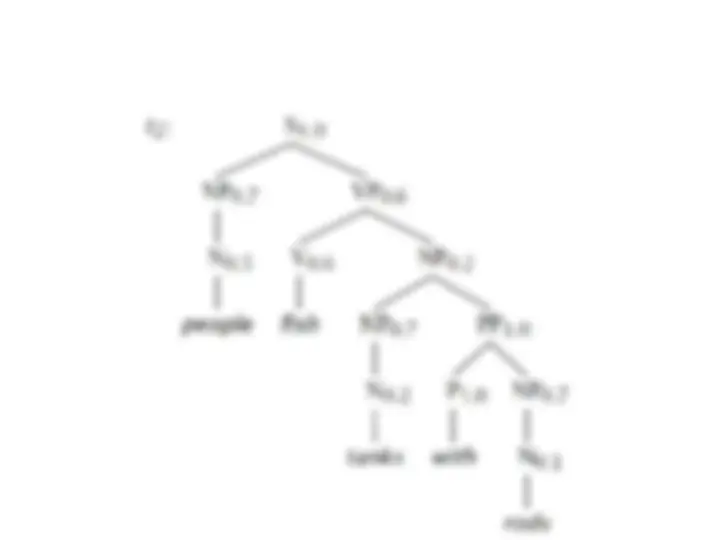
NP e PP P NP people fish tanks people fish with rods N people N fish N tanks N rods V people V fish V tanks P with
[With empty NP removed so less
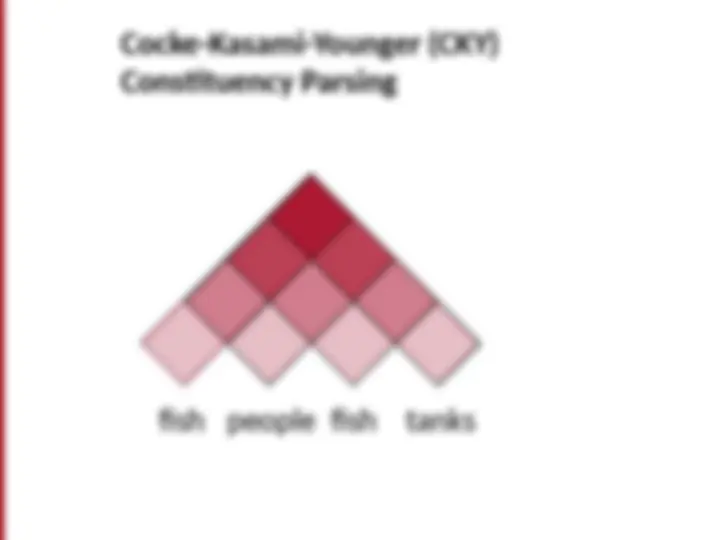
P( t ) – The probability of a tree t is the product of the probabilities of the rules used to generate it.