


Network analysis of
biological data
Gang Fang, PhD
New York University Shanghai Campus






Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The concept of biological network analysis using the examples of E. coli transcriptional regulatory network and the Linux call graph. The author discusses the topology and evolution of these networks, their hierarchical organization, and the correlation between reuse and persistence. The document also highlights the differences between biological and computer operating systems networks in terms of modularity, node reuse, and robustness.
Typology: Slides
1 / 11

This page cannot be seen from the preview
Don't miss anything!
What's the best way to describe biology?
What is biological network
Gene, protein, metabolite, any “biological object”
Regulation, protein-protein interaction, any kind of “similarity” or “dissimilarity” etc.
Conservation of gene, expression value, half time, any measurable or categorical variable.
Clusters, modularity, node centrality, shortest path etc.
Comparison of networks: time series and environmental changes
Test your theory!
Hierarchical organization:
pyramidal versus top-heavy
E. coli transcriptional regulatory network the Linux call graph
master regulator
workhorse
middle manager
Persistent genes^ Persistent functions
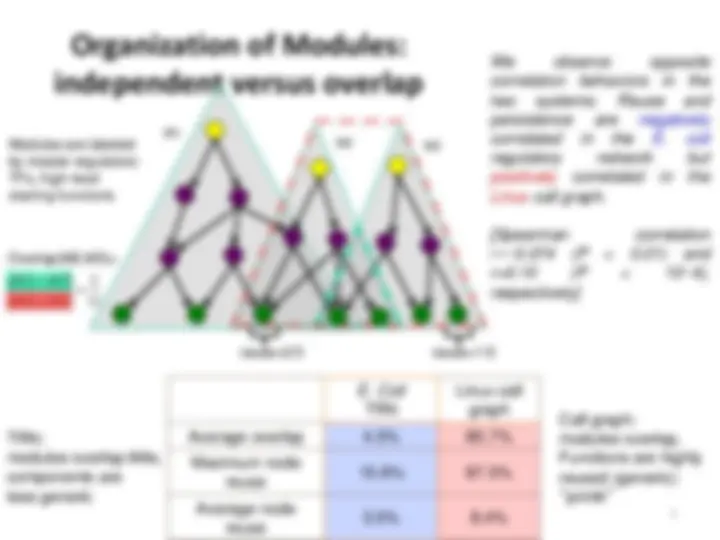
Organization of Modules:
independent versus overlap
7
E. Coli TRN
Linux call graph Average overlap 4.3% 80.7% Maximum node reuse 15.6%^ 87.5% Average node reuse
Modules are labeled by master regulators: TFs, high-level starting functions
modules overlap little, components are less generic
M 2 ∩ M 3 M 2 ∪ M 3
= 2 11
Overlap(M2,M3)=
reuse=2/3 reuse=1/
M M2 (^) M
Call graph: modules overlap, Functions are highly reused (generic): “printk”
We observe opposite correlation behaviors in the two systems: Reuse and persistence are negatively correlated in the E. coli regulatory network but positively correlated in the Linux call graph.
[Spearman correlation r=−0.074 (P < 0.01) and r=0.10 (P < 10 −4), respectively]
Can we use network analysis to
identify protein “living fossils”?