


Topic: Functional Dependencies and Normalization
Instructor: Lecturer Ayesha Naseer









































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
this document contains detailed explanation for beginners..it has covered each and every topic in details for those who are eager to learn data base management system.
Typology: Slides
1 / 49

This page cannot be seen from the preview
Don't miss anything!
Overview of Course Outcomes
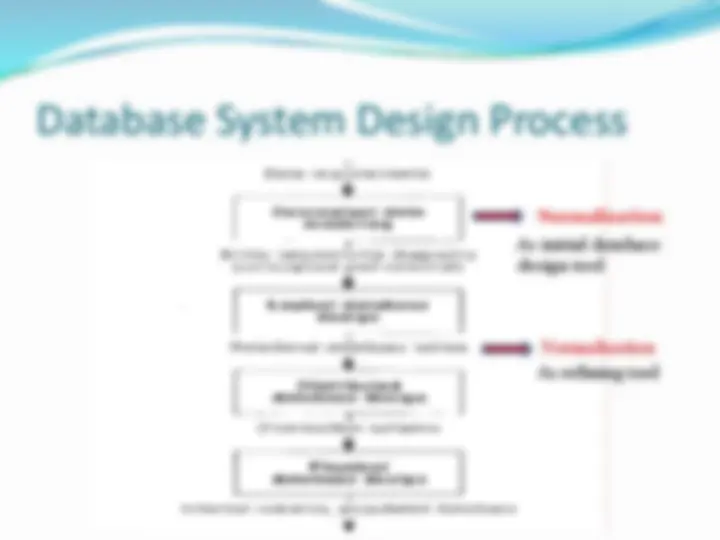
Database System Design Process Normalization Normalization As refining tool As initial database design tool
Informal Design Guide Lines For Relational Schema
Semantics of the Relation Attributes
Redundant Information in Tuples and Update Anomalies Mixing attributes of multiple entities may cause problems Information is stored redundantly wasting storage Problems with update anomalies Insertion anomalies Deletion anomalies Modification/Update anomalies
Insertion Anomalies Insertion Anomalies. Insertion anomalies can be differentiated into two types, illustrated by the following examples based on the EMP_DEPT relation: ■ To insert a new employee tuple into EMP_DEPT, we must include either the attribute values for the department that the employee works for, or NULLs (if the employee does not work for a department as yet). ■ It is difficult to insert a new department that has no employees as yet in the EMP_DEPT relation. The only way to do this is to place NULL values in the attributes for employee. This violates the entity integrity for EMP_DEPT because Ssn is its primary key. Moreover, when the first employee is assigned to that department, we do not need this tuple with NULL values any more.
Deletion Anomalies
Guideline to Redundant Information in Tuples and Update Anomalies GUIDELINE 2: Design a schema that does not suffer from the insertion, deletion and update anomalies. If there are any present, then note them so that applications can be made to take them into account.
GUIDELINE 3: Relations should be designed such that their tuples will have as few NULL values as possible Attributes that are NULL frequently could be placed in separate relations (with the primary key) Reasons for nulls: attribute not applicable or invalid attribute value unknown (may exist) value known to exist, but unavailable
Functional dependencies (FDs) are used to specify formal measures of the "goodness" of relational designs FDs and keys are used to define normal forms for relations FDs are constraints that are derived from the meaning and interrelationships of the data attributes A set of attributes X functionally determines a set of attributes Y if the value of X determines a unique value for Y
Examples of FD constraints (1) social security number determines employee name SSN - > ENAME project number determines project name and location PNUMBER - > {PNAME, PLOCATION} employee ssn and project number determines the hours per week that the employee works on the project {SSN, PNUMBER} - > HOURS
Practice Relation AB true BC false ABC false