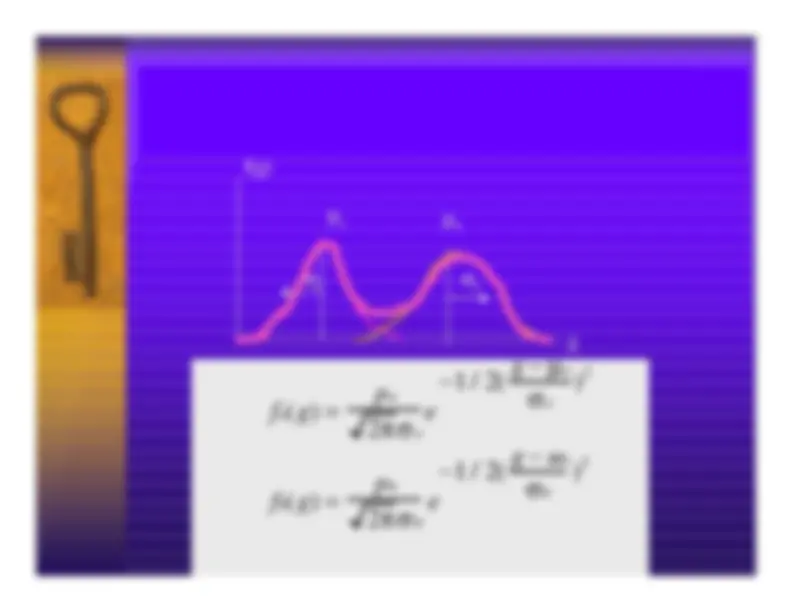
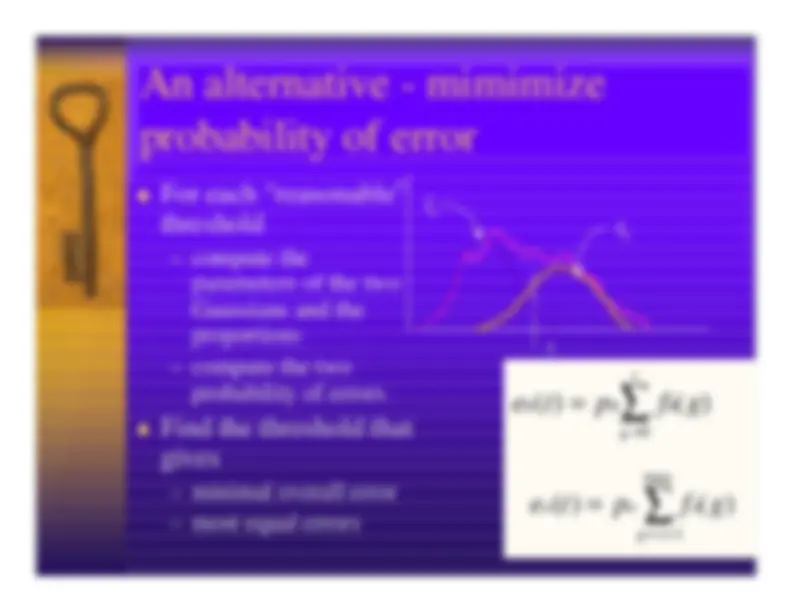
Statistical methods in recognition
♦Basic steps in classifier design
–Collect training data
–Choose a classification model
•Statistical
•Linguistic
–Estimate “parameters” of classification model from
training images
•Learning
–Evaluate model on training data and refine
–Collect test data set
–Apply classifier to test data