



Null Hypothesis Significance
Testing
Docsity.com





















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
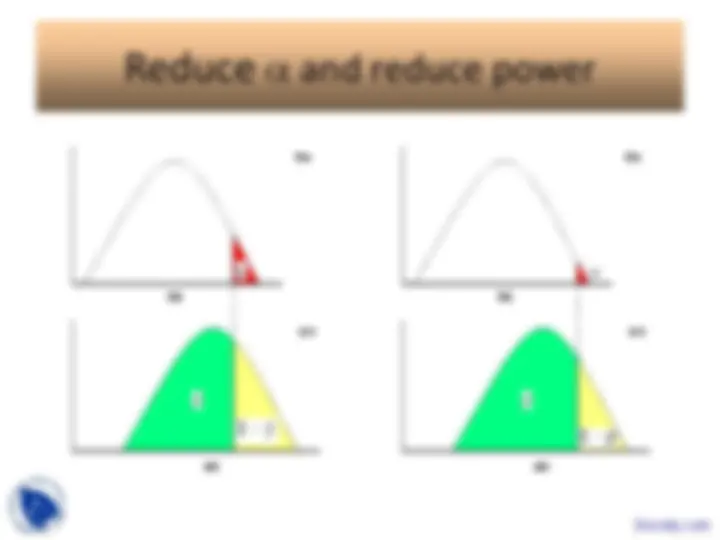
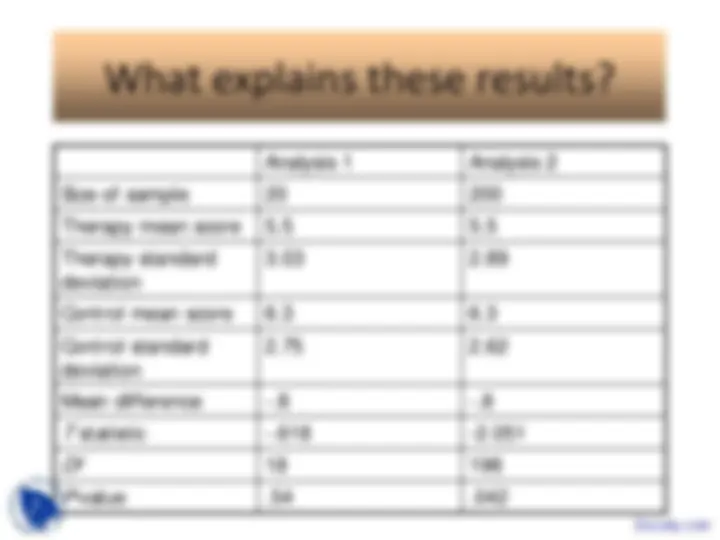
An overview of null hypothesis significance testing (nhst), focusing on the concepts of type i and type ii errors and power. It covers one-tailed and two-tailed tests, the role of significance levels, and the importance of minimizing both types of errors. The document also includes an exercise on increasing the power of a study.
Typology: Slides
1 / 30

This page cannot be seen from the preview
Don't miss anything!
True State of Nature
Decision Ho is True H (^) o is False
Accept H (^) o Correct Decision Type II Error
Reject H (^) o Type I Error Correct Decision