Download OpenMP - Parallel Computing - Lecture Slides and more Slides Parallel Computing and Programming in PDF only on Docsity!
Programming Shared-memory
Platforms with OpenMP
2
Topics for Today
- Introduction to OpenMP
- OpenMP directives —concurrency directives - parallel regions - loops, sections, tasks —synchronization directives - reductions, barrier, critical, ordered —data handling clauses - shared, private, firstprivate, lastprivate —tasks
- Performance tuning hints
- Library primitives
- Environment variables
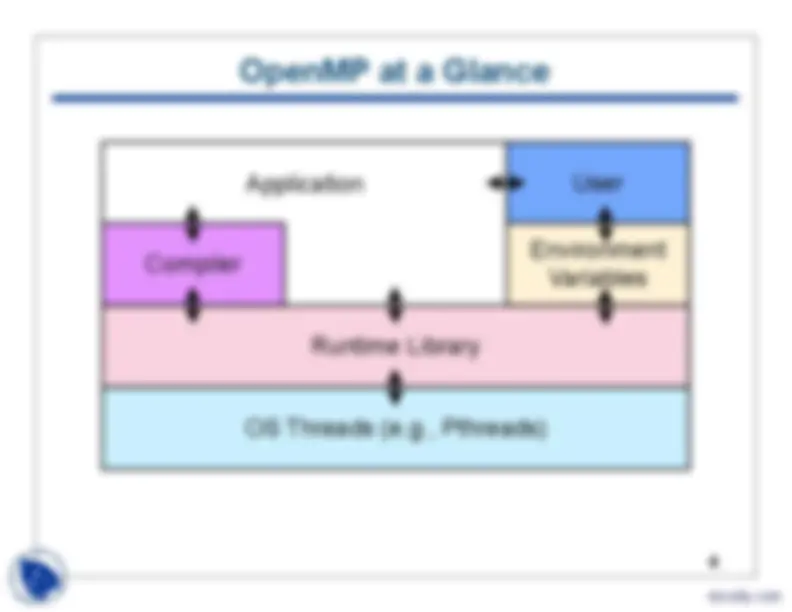
OpenMP at a Glance
4 User Environment Variables Runtime Library Compiler OS Threads (e.g., Pthreads) Application
5
OpenMP Is Not
- An automatic parallel programming model —parallelism is explicit —programmer full control (and responsibility) over parallelization
- Meant for distributed-memory parallel systems (by itself) —designed for shared address spaced machines
- Necessarily implemented identically by all vendors
- Guaranteed to make the most efficient use of shared memory —no data locality control
7
OpenMP: Fork-Join Parallelism
- OpenMP program begins execution as a single master thread
- Master thread executes sequentially until^1 st
parallel region
- When a parallel region is encountered, master thread —creates a group of threads —becomes the master of this group of threads —is assigned the thread id 0 within the group F o r k J o i n F o r k J o i n F o r k J o i n master thread shown in red
8
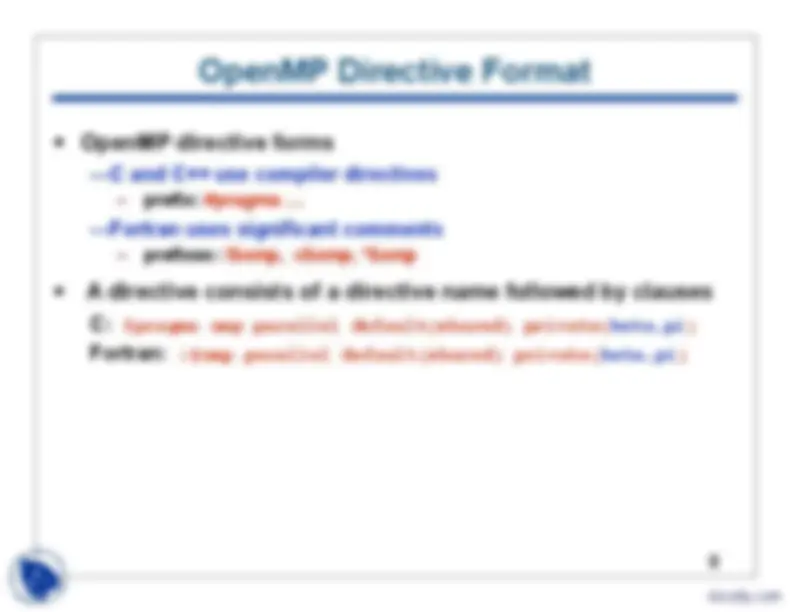
OpenMP Directive Format
- OpenMP directive forms —C and C++ use compiler directives - prefix: #pragma … —Fortran uses significant comments - prefixes: !$omp, c$omp, *$omp
- A directive consists of a directive name followed by clauses C: #pragma omp parallel default(shared) private(beta,pi) Fortran: !$omp parallel default(shared) private(beta,pi)
10
Interpreting an OpenMP Parallel Directive
#pragma omp parallel if (is_parallel==1) num_threads( 8 )
shared (b) private (a) firstprivate(c) default(none) { / structured block / } Meaning
- if (is_parallel== 1 ) num_threads( 8 ) —If the value of the variable is_parallel is one, create 8 threads
- shared (b) —each thread shares a single copy of variable b
- private^ (a)^ firstprivate(c) —each thread gets private copies of variables a and c —each private copy of c is initialized with the value of c in main thread when the parallel directive is encountered
- default(none) — (^) default state of a variable is specified as none (rather than shared ) —signals error if not all variables are specified as shared or private
int a, b; main() { // serial segment #pragma omp parallel num_threads(8) private (a) shared (b) { // parallel segment } // rest of program } 11
Meaning of OpenMP Parallel Directive
sample OpenMP program **int a, b; main() { // serial segment for (i = 0; i < 8; i++) pthread_create(..., internal_thread_fn, ...); for (i = 0; i < 8; i++) pthread_join(...); // rest of program } void internal_thread_fn(void thread_args) { int a; // parallel segment } naive Pthreads translation
13
Worksharing DO/for Directive
for directive partitions parallel iterations across threads
DO is the analogous directive for Fortran
- Usage: #pragma omp for [clause list] /* for loop */
- Possible clauses in [clause list] — private, firstprivate, lastprivate — reduction — schedule, nowait, and ordered
- Implicit barrier at end of^ for^ loop
A Simple Example Using parallel and for
Program void main() { #pragma omp parallel num_threads(3) { int i; printf(“Hello world\n”); #pragma omp for for (i = 1; i <= 4; i++) { printf(“Iteration %d\n”,i); } printf(“Goodbye world\n”); } } 14 Output Hello world Hello world Hello world Iteration 1 Iteration 2 Iteration 3 Iteration 4 Goodbye world Goodbye world Goodbye world
- a local copy of sum for each thread
- all local copies of sum added together and stored in master^ 16
OpenMP Reduction Clause Example
OpenMP threaded program to estimate PI #pragma omp parallel default(private) shared (npoints)
reduction(+: sum) num_threads( 8 ) { num_threads = omp_get_num_threads(); sample_points_per_thread = npoints / num_threads; sum = 0; for (i = 0; i < sample_points_per_thread; i++) { coord_x =(double)(rand_r(&seed))/(double)(RAND_MAX) - 0.5; coord_y =(double)(rand_r(&seed))/(double)(RAND_MAX) - 0.5; if ((coord_x * coord_x + coord_y * coord_y) < 0.25) sum ++; } }
here, user
manually
divides work
worksharing for
divides work
17
Using Worksharing for Directive
#pragma omp parallel default(private) shared (npoints)
reduction(+: sum) num_threads( 8 ) { sum = 0; #pragma omp for for (i = 0; i < npoints; i++) { rand_no_x =(double)(rand_r(&seed))/(double)(RAND_MAX); rand_no_y =(double)(rand_r(&seed))/(double)(RAND_MAX); if (((rand_no_x - 0.5) * (rand_no_x - 0.5) + (rand_no_y - 0.5) * (rand_no_y - 0.5)) < 0.25) sum ++; } }
Implicit barrier at end of loop
19
Statically Mapping Iterations to Threads
/* static scheduling of matrix multiplication loops */
#pragma omp parallel default(private) \
shared (a, b, c, dim) num_threads(4)
#pragma omp for schedule(static)
for (i = 0; i < dim; i++) {
for (j = 0; j < dim; j++) {
c(i,j) = 0;
for (k = 0; k < dim; k++) {
c(i,j) += a(i, k) * b(k, j);
static schedule maps iterations
to threads at compile time
20
Avoiding Unwanted Synchronization
- Default: worksharing^ for^ loops end with an implicit barrier
- Often, less synchronization is appropriate —series of independent for -directives within a parallel construct
- nowait^ clause —modifies a for directive —avoids implicit barrier at end of for