



Optimization in Deep Learning
Jes´us Fern´andez-Villaverde1and Galo Nu˜no2
September 1, 2022
1University of Pennsylvania
2Banco de Espa˜na

















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Optimization methods in deep learning, including descent direction iteration, gradient descent, stochastic gradient descent, minibatch gradient descent, and conjugate gradient descent. It also covers approaches to traditional optimization, such as random initializations, multi-starts, vanishing and exploding gradients, batch normalization, and bagging. insights into the trade-offs between speed of convergence and robustness, and the use of noisy update processes to avoid local minima. It also discusses the limitations of second-order and direct methods, as well as genetic algorithms.
Typology: Slides
1 / 26

This page cannot be seen from the preview
Don't miss anything!
Jes´us Fern´andez-Villaverde^1 and Galo Nu˜no^2 September 1, 2022 (^1) University of Pennsylvania
(^2) Banco de Espa˜na
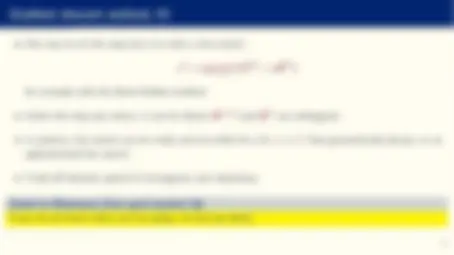
αk^ = arg min α E(θ(k)^ + αd(k))
for example with the Brent-Dekker method.
Heard in Minnesota Econ grad student lab If you do not know where you are going, at least go slowly.