Download Optimization Techniques, Lecture Notes- Physics - Prof IB Leader 5 and more Study notes Physics in PDF only on Docsity!
7.4 Nonlinear Constrained Optimization
7.4.1 Optimality Conditions
As shown in Section 4.2, for to be local minimum for all feasible direc- tions. This means that, if an optimum is to lie on a constraint boundary, the gradient must be perpendicular to the constraint boundary. If it is not, then there must be a feasible direction along the constraint boundary for which. (When moving along a constraint boundary, if d is a feasible direction then − d is also a feasible direction.)
If more than one constraint is active, then the feasible directions at a given point on the con- straint boundary lie in the tangent plane of the surface defined by the constraints. Thus, for to be local minimum, must be perpendicular to the tangent plane of the surface defined by the constraints. Some examples of tangent planes/lines are shown in Figure 7.2.
An alternative way of stating the same condition is that the gradient of the objective function and the gradients of the active constraints lie in the same plane at any local minimum (or max-
x *^ ∇ f ( x *)⋅ d ≥ 0 ∇ f
∇ f ( x *)⋅ d < 0
x * ∇ f
Figure 7.2 : Examples of Tangent Planes at x *.
h ( x ) = 0
∇ h ( x *)
x * S
tangent plane
h ( x ) = 0
S
∇ h ( x *) tangent plane
x *
h 1 ( x ) = 0
h 2 ( x ) = 0
∇ h 1 ( x *)
∇ h 2 ( x *) tangent plane (line only)
x * S
imum), so that the gradient of the objective function can be written as a linear sum of the gra- dients of the active constraints:
, (7.9)
where is the Jacobian matrix:
(7.10)
For simplicity, equation (7.9) has been written in terms of equality constraints only, but, as an active inequality constraint is effectively an equality constraint, there is no loss of gener- ality in so doing.
Equation (7.9) gives us a first-order necessary condition for a local minimum.
7.5 Lagrange and Kuhn-Tucker Multipliers
7.5.1 Lagrange Multipliers
Let the problem be to minimize the objective function subject to a set of m equality con- straints.
Now define an unconstrained function
, (7.11)
where the are called Lagrange multipliers.
If is the minimum of L , then
(7.12)
or
. (7.13) Thus
, (7.14)
which can be by rewritten as
. (7.15)
∇ f α i ∇ h (^) i i = 1
m
∑ ∇ h^
= = T αα
∇ h
∇ h x ( *)
∇ h 1 ( x *) T
∇ hm ( x *) T
∂ h 1 ∂ x 1 …^
∂ h 1 ∂ xn
∂ hm ∂ x 1 …
∂ hm ∂ xn
= =
f ( x ) =
g 2 ( x ) =
h 1 ( x ) = 0 , … , hm ( x ) = 0
L ( x ) f ( x ) λ i hi ( x ) i = 1
m
λ i x *
∂ L ( x *, λλ) ∂ x 1 …^
∂ L ( x *, λλ) = = (^) ∂ xn = 0
∇ L ( x *, λλ) = 0
∇ f ( x *) + [ ∇ h x ( *)] T^ λλ = 0
∇ f ( x *) = −[ ∇ h x ( *)] T^ λλ
4Mt
Example: Lagrange Multipliers (continued)
Figure7,3:Contoursof /(x) andL(x).
The left-handdiagramdepictsthe contounof /(x) = \xi. The contourline corresponding to the constraintft(x) = xi+xi-2^ ,^ )^1 = 0 is superimposed.The righrhanddiagramdepicts the contoursof theLagrangian.
7.5.3 Inequality (^) Constrainls As alreadymentionedin Section7.3.4,oneway of dealingwith inequalityconstraintsis to transformtheminto equalityconsraintsby addingan extra(non-negative)variable,calleda slack variable,and an extraconstraint.That is, sincean inequalityconstraintis definedas 8r(x) < 0, a positiveslackvariables, transformsthe constraintto g,(x) =^ 8;(x) + s, = 0. For this new constraint,the Lagrangemultiplier must be greaterthan or equal to zero.This methodis describedin moredetailin Siddall. Alternatively,inequalityconstraintscanbe dealtwith usingthe methodof Kuhn-Tuckermulti- pliers.
7.5.4 Kuhn-Thcker (^) Multipliers
Let the problembe to minimizethe objectivefunction/(x) subjectto a setof m equalitycon- s t r a i n t s - f t , ( x ) : 0 ,... , h. ( x ) = 0 a n d p i n e q u a l i t y c o n s t r a i n t s C t ( x ) < 0 ,... , C e ( x ) < 0.
Definean unconstrainedfunction
GTP
! m- l.. ,. sP ' l L ( x ) = / ( x ) + L A i h i \ x ) + L p t S i \ x ). ; - l ; - 1
(7.1e)
A sufficient second-order condition for to be a local minimum is that be positive definite on the tangent plane M of the active constraints at , i.e.
. (7.24)
If there are no equality constraints, i.e. , then the first-order conditions
(7.25) and (7.26)
are sufficient to identify a local minimum.
The problem is now to solve the following equations:
(7.27)
So we have a system of equations and unknowns. These equations can be solved by systematically (or otherwise) checking for active inequality constraints, as illus- trated in the example which follows.
See Chapter 3 of Gill, Murray and Wright for the proofs of the above statements and a more detailed discussion.
x *^ ∇^2 L ( x *) x *
y T ∇^2 L ( x *) y > 0 ∀ y ∈ M m = 0
∇ f ( x *) + [ ∇ g x ( *)] T μμ = 0
μ i ≥ 0 ∀ i = 1 , … , p x *
∇ f ( x *) + [ ∇ h x ( *)] T^ λλ^ + [ ∇ g x ( *)] T μμ = 0 ( n equations) h x ( *) = 0 ( m equations) ∀ i = 1 , … , p , μ (^) i gi ( x ) = 0 ( p equations) m + n + p m + n + p
7.5.5 Example: Kuhn-Tucker Multipliers
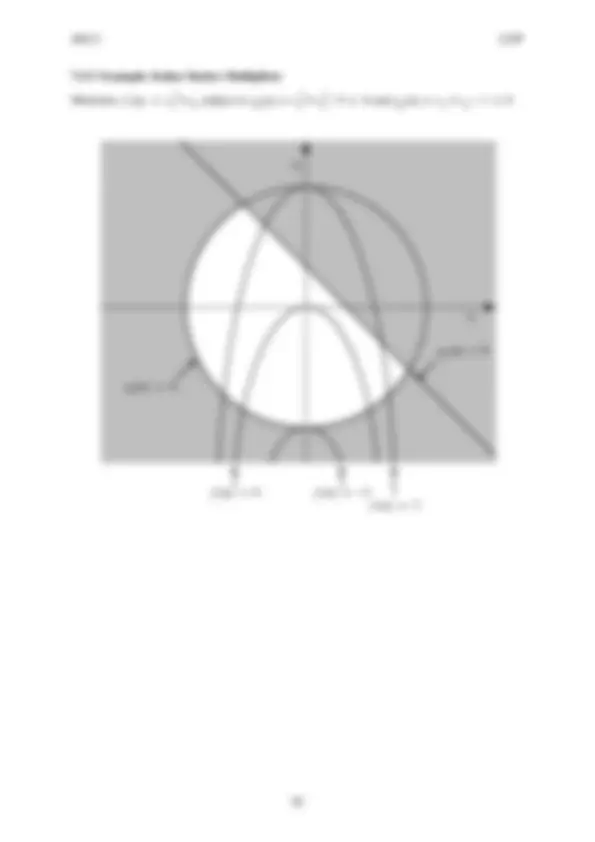
- Minimize f ( x ) = x 12 + x 2 subject to g 1 ( x ) = x 12 + x 22 − 9 ≤ 0 and g 2 ( x ) = x 1 + x 2 − 1 ≤ - x - x - f ( x ) = 0 f ( x ) = − - f ( x ) =
- g 1 ( x ) = - g 2 ( x ) =
7.5.6 Sensitivity of Constraints
It is often desirable to have information about the cost of the constraints in a problem or the sensitivity of the solution to variations in the constraints. The Lagrange and Kuhn-Tucker mul- tipliers associated with the constrained problem can provide this information.
Equality Constraints
Consider the family of problems
Minimize subject to (7.28)
and suppose that there are local solutions varying smoothly with c , with. Then it can be shown that
(7.29)
where is the Lagrange multiplier vector associated with.
Inequality & Equality Constraints
Consider now the family of problems
Minimize subject to and (7.30)
and suppose that there are local solutions varying smoothly with c and d , with , and for all active constraints, then it can be shown that
(7.31)
where is the Kuhn-Tucker multiplier vector associated with.
Thus Lagrange and Kuhn-Tucker multipliers provide a relative measure of the sensitivity of to changes in the constraints. For example, if in a problem we have and , then changes in will tend to have a much larger effect on the value of f than changes in.
(See Luenberger pp. 312-315 for proofs.)
f ( x ) h x ( ) = c x c ( ) x ( 0 ) = x *
∇ c f ( x c ( )) (^) c = 0 = −λλ λλ x *
f ( x ) h x ( ) = c g x ( ) ≤ d x c d ( , ) x ( 0 0, ) = x * μ i > 0 ∇ c f ( x c d ( , )) (^) c d , = 0 0, =−λλ ∇ d f ( x c d ( , )) (^) c d , = 0 0, =−μμ μμ x *
f ( x *) λ 1 = 10 3 λ 2 = 10 −^3 c 1 c 2
7.6 Penalty Functions
Another approach for constrained problems is to use a penalty function which is added to the objective function, and ‘penalises’ points which lie outside the feasible region.
The advantage of this approach is that it essentially turns a constrained problem into an uncon- strained one. The disadvantage is that a mild penalty function can still allow the search to leave the feasible region, while a severe penalty function can create awkward ‘valleys’ where a search algorithm can get stuck, or produce ill-conditioned gradients and Hessians for curve- fitting methods. (Ill-conditioning means that small perturbations in the input can lead to enor- mous changes in the output.)
The commonest penalty function is
, (7.32)
where m is the number of constraints and p is called the penalty parameter.
Note that equality constraints can be incorporated into the function by writing them as two inequalities:
Figure 7.4 : An Example of a Penalty Function.
q ( x , p ) f ( x ) p ( max [ 0 , gi ( x )])^2 i = 1
m
hi ( x ) = 0
hi ( x ) ≤ 0 ⇒− h (^) i ( x ) ≤ 0
x
f ( ) x
g x ( ) = x − x ˆ ≤ 0
x ˆ
increasing p
7.7 Barrier Functions
In order to preserve feasibility a ‘barrier’ preventing iterates from becoming infeasible is cre- ated by adding to the objective function a weighted sum of continuous functions with a posi- tive singularity at the boundary of the feasible region. (This is in contrast to a penalty function which merely adds a penalty for infeasibility).
A barrier function is infinite along the edge of the feasible region. This is fine provided the region is not disjoint , that is, any part of the boundary can be approached from within the region. It also means that a barrier function cannot be applied to an equality constraint.
A common form of barrier function is the inverse barrier function
, (7.33)
where r is termed the barrier parameter.
Another common form is the logarithmic barrier function
. (7.34)
Figure 7.6 : An Example of a Barrier Function with Two Constraints.
b ( x , r ) f ( x ) (^1) r g^1 i = 1 i^ (^ x )
m
b ( x , r ) f ( x ) (^1) r ln [ − gi ( x )] i = 1
m
x
x
f ( ) x
increasing r
g 1 ( ) x = a − x ≤ 0 g 2 ( ) x = x − b ≤ 0
a b
4Ml3 GTP
These barrier functions always yields infinity on the boundary- but conform increasingly closely to the original function within the feasible region for increasingvalues of the barrier parameterr. Again, it is necessaryto increasethe barrier parametergradually,and caremust be taken to use small step sizeswhen r is large, or the searchalgorithm might leap clear over the boundaryin "a single (^) bound". Method:
- Select an initial (small) value for r and a startingpoint in the feasibleregion.
- Minimize D(x, r) usinga suitableunconstrainedoptimizationalgorithm.
- Increaser and repeatthe minimization starting with dre final point of 2 until convergence. One ofthe practical advantagesof the barrier function method is that the optimization process will yield a feasibleanswerevenif it is terminatedprematurely.
7.7.1Example:Barrier Functions Minimize/(x) = xrxz2subjectto g(x) = x?+x:-2 S O
Figure7.7:ContoursofD(x, r).
The two diagramsrepresentthe contoursof the logarithmic barrier function b(x, r) for r = 5 (left-hand (^) diagram) and r = 1000 (right-hand (^) diagram). The selectionofan appropriateunconstrainedoptimization methodto use in conjunction with penalty and barrier functions dependsa great deal on the typs of problem to be solved. A detailed discussionon this subjectcan be found in Luenberger,Chapter 12.