



































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A transcript of Lecture 28 from the Performance Programming and Static Analysis for Security course given by Sean Peisert at Lawrence Livermore National Labs in Spring 2009. The lecture covers topics such as Power3's capabilities, harnessing its power, FLOP to MemOp ratio, pipeline latency, Fortran vs C, and security vulnerabilities like buffer overflows and TOCTTOU.
Typology: Slides
1 / 40

This page cannot be seen from the preview
Don't miss anything!
1
Status
4 Power3’s power … and limits
5 Can its power be harnessed?
FMA fp31=fp31,fp2,fp0,fcr LFL fp1=()double(gr3,16) FNMS fp30=fp30,fp2,fp0,fcr LFDU fp3,gr3=()double(gr3,32) FMA fp24=fp24,fp0,fp1,fcr FNMS fp25=fp25,fp0,fp1,fcr LFL fp0=()double(gr3,24) FMA fp27=fp27,fp2,fp3,fcr FNMS fp26=fp26,fp2,fp3,fcr LFL fp2=()double(gr3,8) FMA fp29=fp29,fp1,fp3,fcr FNMS fp28=fp28,fp1,fp3,fcr BCT ctr=CL.6,
7 FLOP to MemOp ratio
Matrix-vector product: ( _K+1_ ) loads, _K_ fma’s Matrix multiply (well-tuned): 2 FMA per load 8 The effect of pipeline latency for (i=0; i<size; i++) { sum = a[i] + sum; } for (i=0; i<size; i+=4) { sum0 += a[i]; sum1 += a[i+1]; sum2 += a[i+2]; sum3 += a[i+3]; } sum = sum0+sum1+sum2+sum3; 3.86 cycles/addition 1.1 cycles/addition Next add can’t start until previous is finished (3 to 4 cycles later)
What’s so great about Fortran??
L4A gr0=b(gr5,4) L4A gr6=b(gr5,8) L4A gr7=b(gr5,12) L4AU gr8,gr5=b(gr5,16) ST4A a(gr4,8)=gr ST4A a(gr4,4)=gr ST4A a(gr4,12)=gr ST4U gr4,a(gr4,16)=gr BCT ctr=CL.8,
ST4U gr4,()int(gr4,4)=gr L4AU gr24,gr3=()int(gr3,4) BCT ctr=CL.6,
10 Fortran vs C - what’s going on??
User may want b[0] and a[1] to be same location
Most C compilers don’t try to prove non-aliasing Fortran doesn’t allow arrays to be aliased Unless explicit, e.g. via EQUIVALENCE
12 Decreasing MemOp to FLOP Ratio for (i=1; i<N; i++) for (j=1; j<N; j++) b[i,j] = 0.25 * (a[i-1][j] + a[i+1][j]
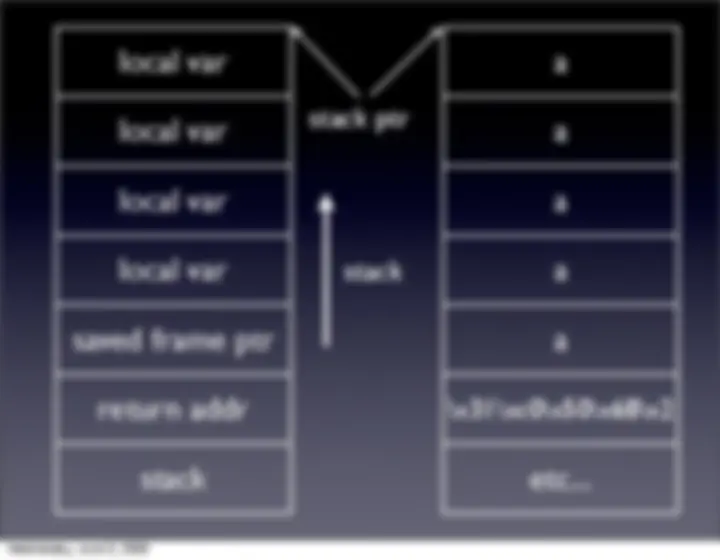
Vulnerable Program? int main(int argc, char *argv[]) { char buffer[500]; strcpy(buffer, argv[1]); printf("Safe program?"); return 0; }
Shellcode \x31\xc0\x50\x68\x2\x2\x73\x68\x68\x2\x62\x 69\x6\x89\xe3\x50\x53\x50\x54\x53\xb0\x3\x 0\xcd\x
Buffer Overflows 18
Impact of Buffer Overflows